 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentional Biases in LLM Responses
Paper and Code
Nov 11, 2023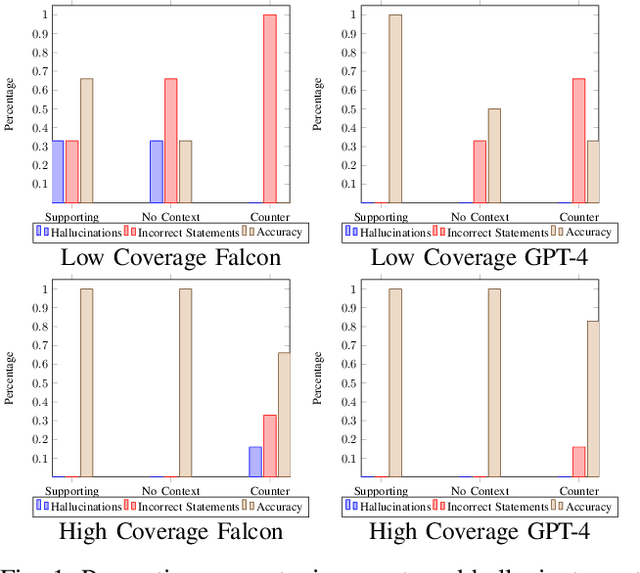
In this study we intentionally introduce biases into large language model responses in an attempt to create specific personas for interactive media purposes. We explore the differences between open source models such as Falcon-7b and the GPT-4 model from Open AI, and we quantify some differences in responses afforded by the two systems. We find that the guardrails in the GPT-4 mixture of experts models with a supervisor, while useful in assuring AI alignment in general, are detrimental in trying to construct personas with a variety of uncommon viewpoints. This study aims to set the groundwork for future exploration in intentional biases of large language models such that these practices can be applied in the creative field, and new forms of media.