 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing AAC Software for Dysarthric Speakers in e-Health Settings: An Evaluation Using TORGO
Nov 01, 2024



Individuals with cerebral palsy (CP) and amyotrophic lateral sclerosis (ALS) frequently face challenges with articulation, leading to dysarthria and resulting in atypical speech patterns. In healthcare settings, coomunication breakdowns reduce the quality of care. While building an augmentative and alternative communication (AAC) tool to enable fluid communication we found that state-of-the-art (SOTA) automatic speech recognition (ASR) technology like Whisper and Wav2vec2.0 marginalizes atypical speakers largely due to the lack of training data. Our work looks to leverage SOTA ASR followed by domain specific error-correction. English dysarthric ASR performance is often evaluated on the TORGO dataset. Prompt-overlap is a well-known issue with this dataset where phrases overlap between training and test speakers. Our work proposes an algorithm to break this prompt-overlap. After reducing prompt-overlap, results with SOTA ASR models produce extremely high word error rates for speakers with mild and severe dysarthria. Furthermore, to improve ASR, our work looks at the impact of n-gram language models and large-language model (LLM) based multi-modal generative error-correction algorithms like Whispering-LLaMA for a second pass ASR. Our work highlights how much more needs to be done to improve ASR for atypical speakers to enable equitable healthcare access both in-person and in e-health settings.
A new approach for fine-tuning sentence transformers for intent classification and out-of-scope detection tasks
Oct 17, 2024
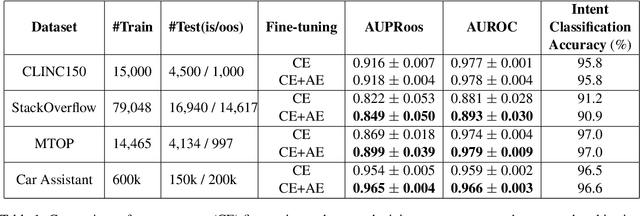

In virtual assistant (VA) systems it is important to reject or redirect user queries that fall outside the scope of the system. One of the most accurate approaches for out-of-scope (OOS) rejection is to combine it with the task of intent classification on in-scope queries, and to use methods based on the similarity of embeddings produced by transformer-based sentence encoders. Typically, such encoders are fine-tuned for the intent-classification task, using cross-entropy loss. Recent work has shown that while this produces suitable embeddings for the intent-classification task, it also tends to disperse in-scope embeddings over the full sentence embedding space. This causes the in-scope embeddings to potentially overlap with OOS embeddings, thereby making OOS rejection difficult. This is compounded when OOS data is unknown. To mitigate this issue our work proposes to regularize the cross-entropy loss with an in-scope embedding reconstruction loss learned using an auto-encoder. Our method achieves a 1-4% improvement in the area under the precision-recall curve for rejecting out-of-sample (OOS) instances, without compromising intent classification performance.
Human Latency Conversational Turns for Spoken Avatar Systems
Apr 11, 2024A problem with many current Large Language Model (LLM) driven spoken dialogues is the response time. Some efforts such as Groq address this issue by lightning fast processing of the LLM, but we know from the cognitive psychology literature that in human-to-human dialogue often responses occur prior to the speaker completing their utterance. No amount of delay for LLM processing is acceptable if we wish to maintain human dialogue latencies. In this paper, we discuss methods for understanding an utterance in close to real time and generating a response so that the system can comply with human-level conversational turn delays. This means that the information content of the final part of the speaker's utterance is lost to the LLM. Using the Google NaturalQuestions (NQ) database, our results show GPT-4 can effectively fill in missing context from a dropped word at the end of a question over 60% of the time. We also provide some examples of utterances and the impacts of this information loss on the quality of LLM response in the context of an avatar that is currently under development. These results indicate that a simple classifier could be used to determine whether a question is semantically complete, or requires a filler phrase to allow a response to be generated within human dialogue time constraints.
Impact of Channel Variation on One-Class Learning for Spoof Detection
Oct 09, 2021
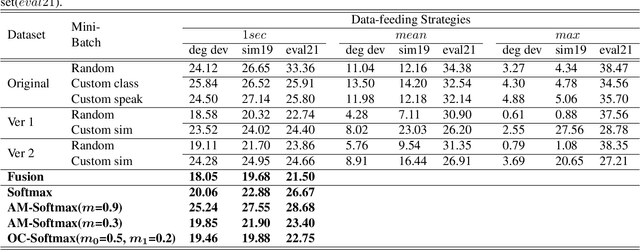
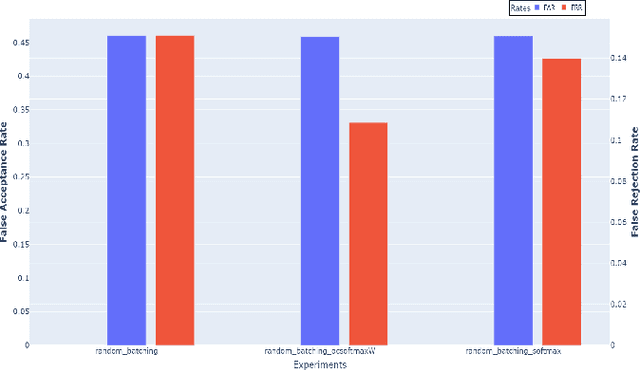
The value of Spoofing detection in increasing the reliability of the ASV system is unparalleled. In reality, however, the performance of countermeasure systems (CMs) degrades significantly due to channel variation. Multi-conditional training(MCT) is a well-established technique to handle such scenarios. However, "which data-feeding strategy is optimal for MCT?" is not known in the case of spoof detection. In this paper, various codec simulations were used to modify ASVspoof 2019 dataset, and assessments were done using data-feeding and mini-batching strategies to help address this question. Our experiments aim to test the efficacy of the various margin-based losses for training Resnet based models with LFCC front-end feature extractor to correctly classify the spoofed and bonafide samples degraded using codec simulations. Contrastingly to most of the works that focus mainly on architectures, this study highlights the relevance of the deemed-of-low-importance process of data-feeding and mini-batching to raise awareness of the need to refine it for better performance.