 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVistaFormer: Scalable Vision Transformers for Satellite Image Time Series Segmentation
Paper and Code
Sep 13, 2024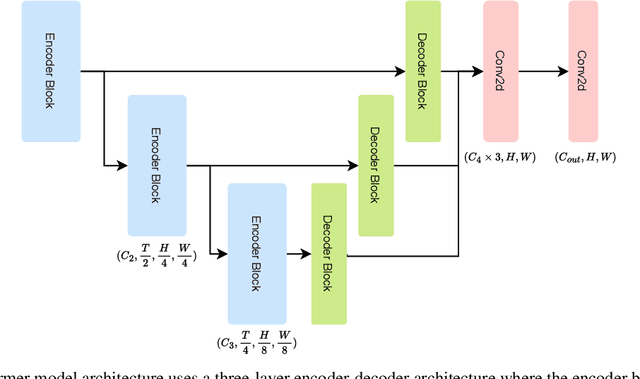

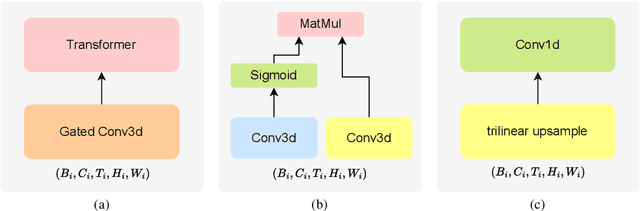

We introduce VistaFormer, a lightweight Transformer-based model architecture for the semantic segmentation of remote-sensing images. This model uses a multi-scale Transformer-based encoder with a lightweight decoder that aggregates global and local attention captured in the encoder blocks. VistaFormer uses position-free self-attention layers which simplifies the model architecture and removes the need to interpolate temporal and spatial codes, which can reduce model performance when training and testing image resolutions differ. We investigate simple techniques for filtering noisy input signals like clouds and demonstrate that improved model scalability can be achieved by substituting Multi-Head Self-Attention (MHSA) with Neighbourhood Attention (NA). Experiments on the PASTIS and MTLCC crop-type segmentation benchmarks show that VistaFormer achieves better performance than comparable models and requires only 8% of the floating point operations using MHSA and 11% using NA while also using fewer trainable parameters. VistaFormer with MHSA improves on state-of-the-art mIoU scores by 0.1% on the PASTIS benchmark and 3% on the MTLCC benchmark while VistaFormer with NA improves on the MTLCC benchmark by 3.7%.