 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSHCNet: Multi-Stream Hybridized Convolutional Networks with Mixed Statistics in Euclidean/Non-Euclidean Spaces and Its Application to Hyperspectral Image Classification
Oct 07, 2021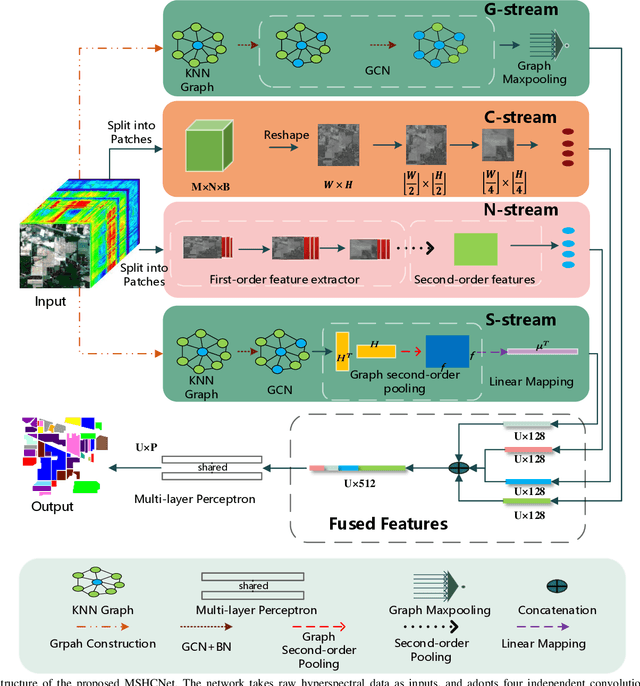
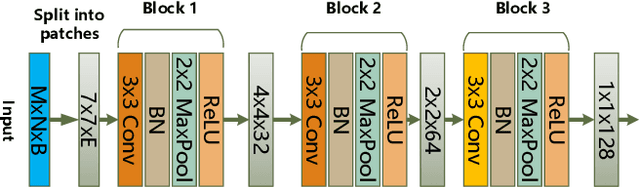

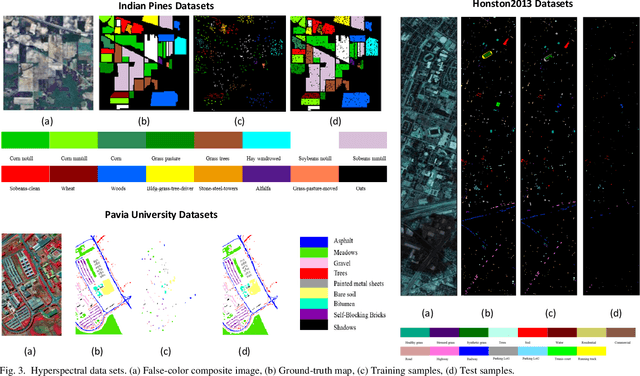
It is well known that hyperspectral images (HSI) contain rich spatial-spectral contextual information, and how to effectively combine both spectral and spatial information using DNN for HSI classification has become a new research hotspot. Compared with CNN with square kernels, GCN have exhibited exciting potential to model spatial contextual structure and conduct flexible convolution on arbitrarily irregular image regions. However, current GCN only using first-order spectral-spatial signatures can result in boundary blurring and isolated misclassification. To address these, we first designed the graph-based second-order pooling (GSOP) operation to obtain contextual nodes information in non-Euclidean space for GCN. Further, we proposed a novel multi-stream hybridized convolutional network (MSHCNet) with combination of first and second order statistics in Euclidean/non-Euclidean spaces to learn and fuse multi-view complementary information to segment HSIs. Specifically, our MSHCNet adopted four parallel streams, which contained G-stream, utilizing the irregular correlation between adjacent land covers in terms of first-order graph in non-Euclidean space; C-stream, adopting convolution operator to learn regular spatial-spectral features in Euclidean space; N-stream, combining first and second order features to learn representative and discriminative regular spatial-spectral features of Euclidean space; S-stream, using GSOP to capture boundary correlations and obtain graph representations from all nodes in graphs of non-Euclidean space. Besides, these feature representations learned from four different streams were fused to integrate the multi-view complementary information for HSI classification. Finally, we evaluated our proposed MSHCNet on three hyperspectral datasets, and experimental results demonstrated that our method significantly outperformed state-of-the-art eight methods.
RSI-Net: Two-Stream Deep Neural Network Integrating GCN and Atrous CNN for Semantic Segmentation of High-resolution Remote Sensing Images
Sep 19, 2021
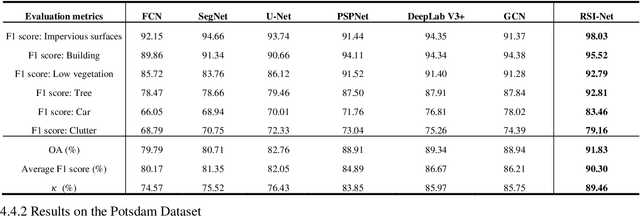
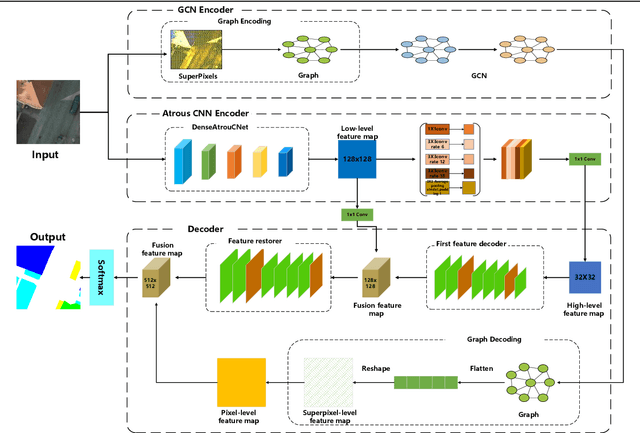
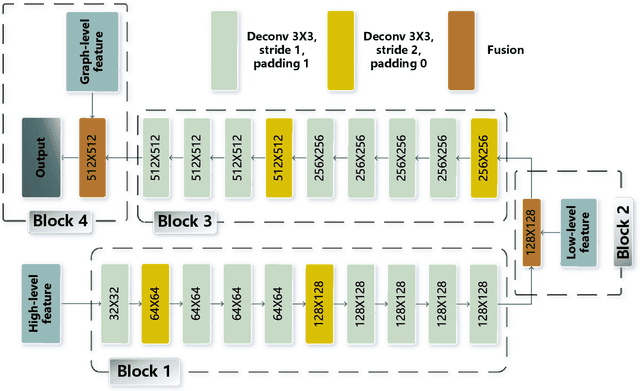
For semantic segmentation of remote sensing images (RSI), trade-off between representation power and location accuracy is quite important. How to get the trade-off effectively is an open question, where current approaches of utilizing attention schemes or very deep models result in complex models with large memory consumption. Compared with the popularly-used convolutional neural network (CNN) with fixed square kernels, graph convolutional network (GCN) can explicitly utilize correlations between adjacent land covers and conduct flexible convolution on arbitrarily irregular image regions. However, the problems of large variations of target scales and blurred boundary cannot be easily solved by GCN, while densely connected atrous convolution network (DenseAtrousCNet) with multi-scale atrous convolution can expand the receptive fields and obtain image global information. Inspired by the advantages of both GCN and Atrous CNN, a two-stream deep neural network for semantic segmentation of RSI (RSI-Net) is proposed in this paper to obtain improved performance through modeling and propagating spatial contextual structure effectively and a novel decoding scheme with image-level and graph-level combination. Extensive experiments are implemented on the Vaihingen, Potsdam and Gaofen RSI datasets, where the comparison results demonstrate the superior performance of RSI-Net in terms of overall accuracy, F1 score and kappa coefficient when compared with six state-of-the-art RSI semantic segmentation methods.
CSC-Unet: A Novel Convolutional Sparse Coding Strategy based Neural Network for Semantic Segmentation
Aug 01, 2021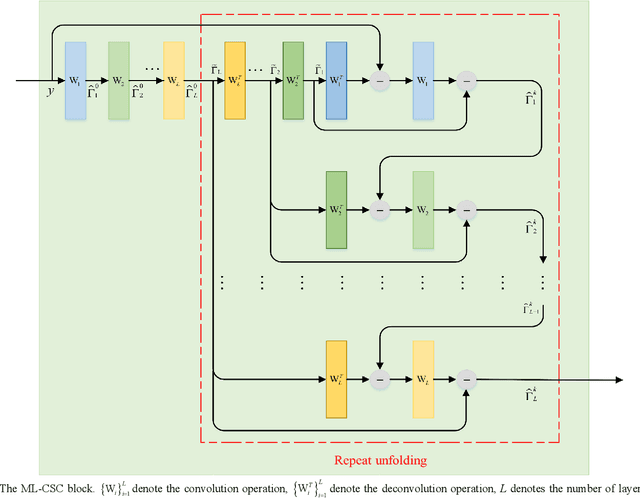
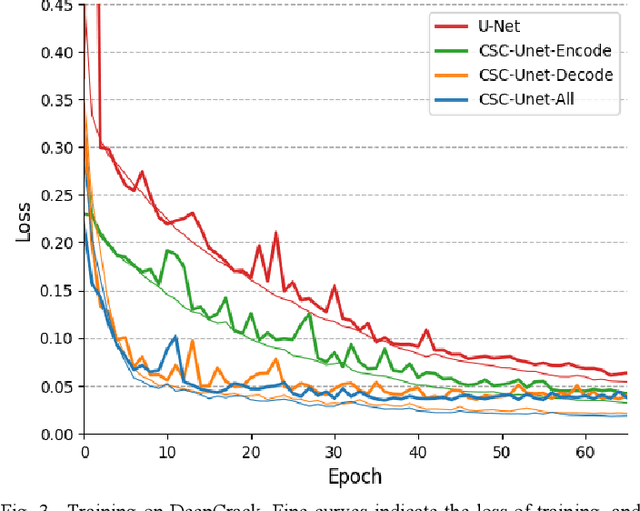

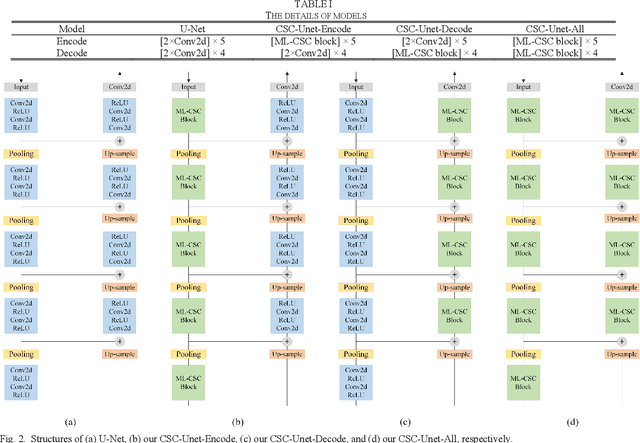
It is a challenging task to accurately perform semantic segmentation due to the complexity of real picture scenes. Many semantic segmentation methods based on traditional deep learning insufficiently captured the semantic and appearance information of images, which put limit on their generality and robustness for various application scenes. In this paper, we proposed a novel strategy that reformulated the popularly-used convolution operation to multi-layer convolutional sparse coding block to ease the aforementioned deficiency. This strategy can be possibly used to significantly improve the segmentation performance of any semantic segmentation model that involves convolutional operations. To prove the effectiveness of our idea, we chose the widely-used U-Net model for the demonstration purpose, and we designed CSC-Unet model series based on U-Net. Through extensive analysis and experiments, we provided credible evidence showing that the multi-layer convolutional sparse coding block enables semantic segmentation model to converge faster, can extract finer semantic and appearance information of images, and improve the ability to recover spatial detail information. The best CSC-Unet model significantly outperforms the results of the original U-Net on three public datasets with different scenarios, i.e., 87.14% vs. 84.71% on DeepCrack dataset, 68.91% vs. 67.09% on Nuclei dataset, and 53.68% vs. 48.82% on CamVid dataset, respectively.