 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSC-Unet: A Novel Convolutional Sparse Coding Strategy based Neural Network for Semantic Segmentation
Paper and Code
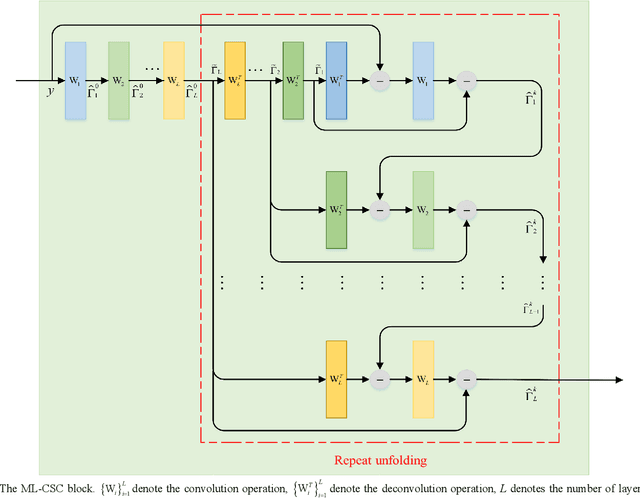
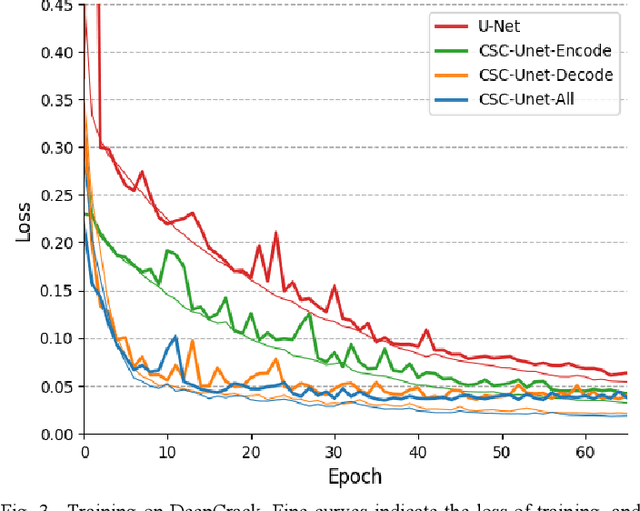

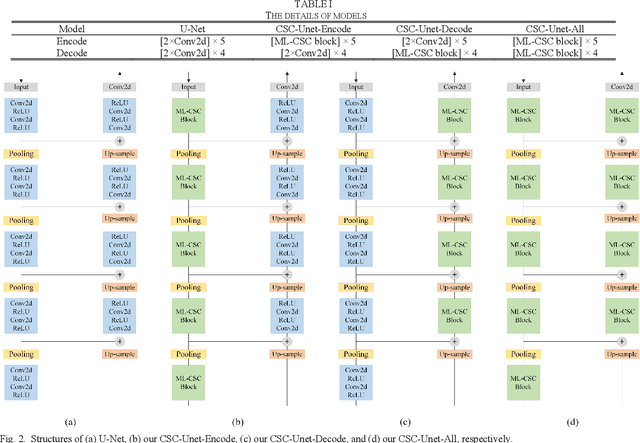
It is a challenging task to accurately perform semantic segmentation due to the complexity of real picture scenes. Many semantic segmentation methods based on traditional deep learning insufficiently captured the semantic and appearance information of images, which put limit on their generality and robustness for various application scenes. In this paper, we proposed a novel strategy that reformulated the popularly-used convolution operation to multi-layer convolutional sparse coding block to ease the aforementioned deficiency. This strategy can be possibly used to significantly improve the segmentation performance of any semantic segmentation model that involves convolutional operations. To prove the effectiveness of our idea, we chose the widely-used U-Net model for the demonstration purpose, and we designed CSC-Unet model series based on U-Net. Through extensive analysis and experiments, we provided credible evidence showing that the multi-layer convolutional sparse coding block enables semantic segmentation model to converge faster, can extract finer semantic and appearance information of images, and improve the ability to recover spatial detail information. The best CSC-Unet model significantly outperforms the results of the original U-Net on three public datasets with different scenarios, i.e., 87.14% vs. 84.71% on DeepCrack dataset, 68.91% vs. 67.09% on Nuclei dataset, and 53.68% vs. 48.82% on CamVid dataset, respectively.