 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSI-Net: Two-Stream Deep Neural Network Integrating GCN and Atrous CNN for Semantic Segmentation of High-resolution Remote Sensing Images
Sep 19, 2021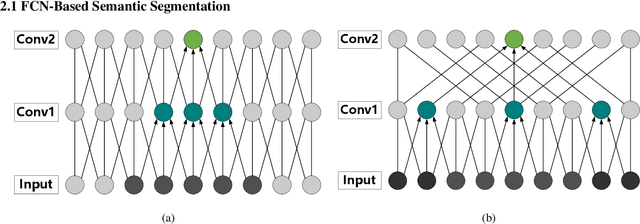
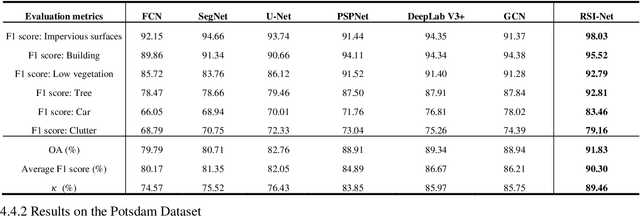
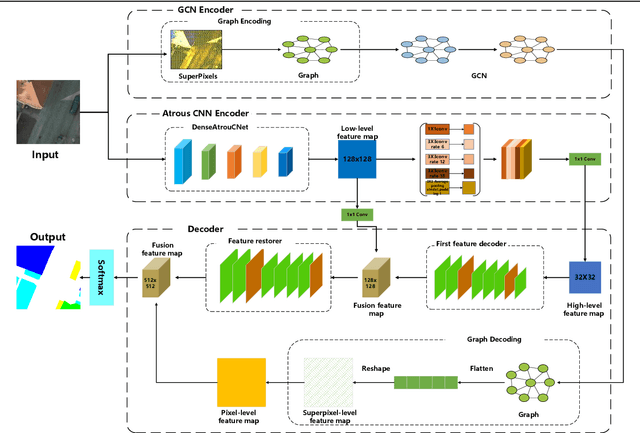
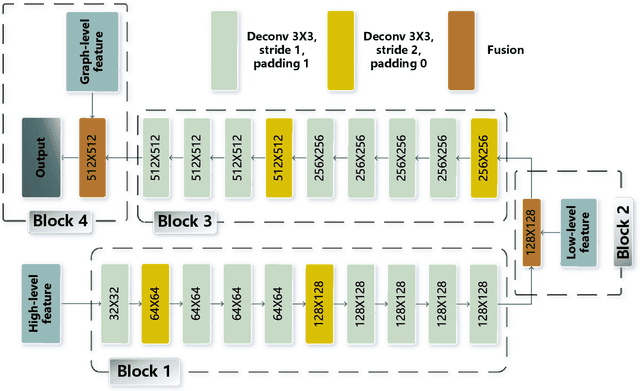
For semantic segmentation of remote sensing images (RSI), trade-off between representation power and location accuracy is quite important. How to get the trade-off effectively is an open question, where current approaches of utilizing attention schemes or very deep models result in complex models with large memory consumption. Compared with the popularly-used convolutional neural network (CNN) with fixed square kernels, graph convolutional network (GCN) can explicitly utilize correlations between adjacent land covers and conduct flexible convolution on arbitrarily irregular image regions. However, the problems of large variations of target scales and blurred boundary cannot be easily solved by GCN, while densely connected atrous convolution network (DenseAtrousCNet) with multi-scale atrous convolution can expand the receptive fields and obtain image global information. Inspired by the advantages of both GCN and Atrous CNN, a two-stream deep neural network for semantic segmentation of RSI (RSI-Net) is proposed in this paper to obtain improved performance through modeling and propagating spatial contextual structure effectively and a novel decoding scheme with image-level and graph-level combination. Extensive experiments are implemented on the Vaihingen, Potsdam and Gaofen RSI datasets, where the comparison results demonstrate the superior performance of RSI-Net in terms of overall accuracy, F1 score and kappa coefficient when compared with six state-of-the-art RSI semantic segmentation methods.
CSC-Unet: A Novel Convolutional Sparse Coding Strategy based Neural Network for Semantic Segmentation
Aug 01, 2021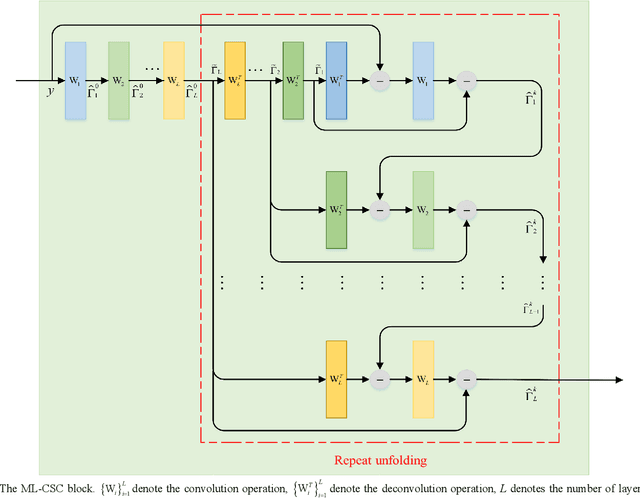
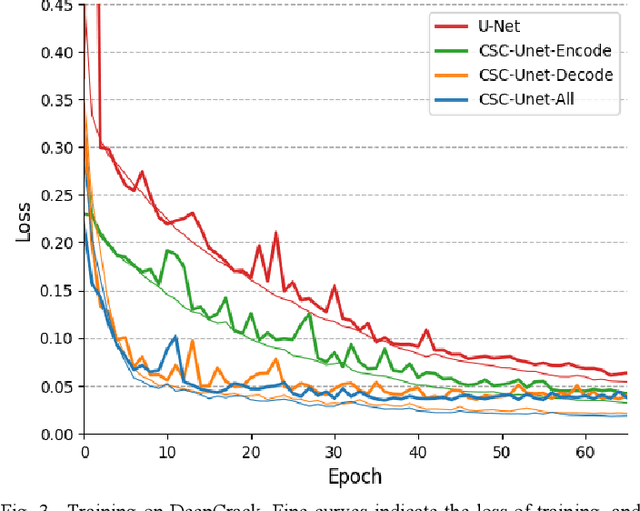

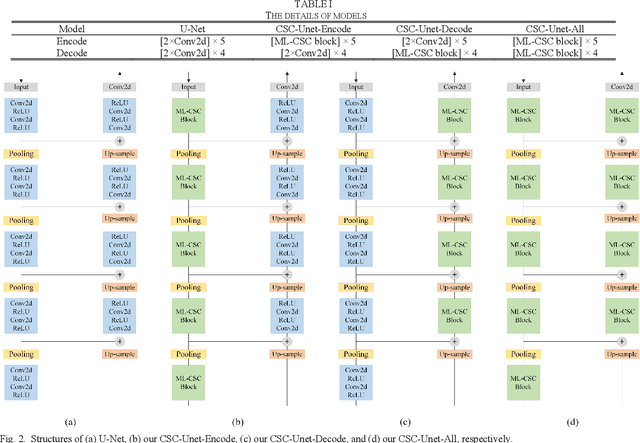
It is a challenging task to accurately perform semantic segmentation due to the complexity of real picture scenes. Many semantic segmentation methods based on traditional deep learning insufficiently captured the semantic and appearance information of images, which put limit on their generality and robustness for various application scenes. In this paper, we proposed a novel strategy that reformulated the popularly-used convolution operation to multi-layer convolutional sparse coding block to ease the aforementioned deficiency. This strategy can be possibly used to significantly improve the segmentation performance of any semantic segmentation model that involves convolutional operations. To prove the effectiveness of our idea, we chose the widely-used U-Net model for the demonstration purpose, and we designed CSC-Unet model series based on U-Net. Through extensive analysis and experiments, we provided credible evidence showing that the multi-layer convolutional sparse coding block enables semantic segmentation model to converge faster, can extract finer semantic and appearance information of images, and improve the ability to recover spatial detail information. The best CSC-Unet model significantly outperforms the results of the original U-Net on three public datasets with different scenarios, i.e., 87.14% vs. 84.71% on DeepCrack dataset, 68.91% vs. 67.09% on Nuclei dataset, and 53.68% vs. 48.82% on CamVid dataset, respectively.
Sparse Object-level Supervision for Instance Segmentation with Pixel Embeddings
Mar 26, 2021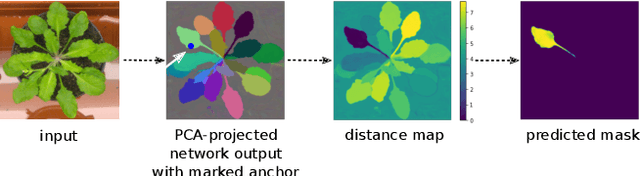

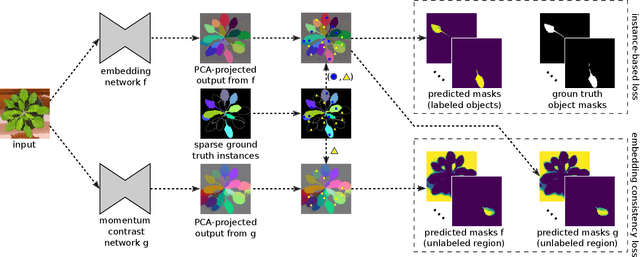

Most state-of-the-art instance segmentation methods have to be trained on densely annotated images. While difficult in general, this requirement is especially daunting for biomedical images, where domain expertise is often required for annotation. We propose to address the dense annotation bottleneck by introducing a proposal-free segmentation approach based on non-spatial embeddings, which exploits the structure of the learned embedding space to extract individual instances in a differentiable way. The segmentation loss can then be applied directly on the instances and the overall method can be trained on ground truth images where only a few objects are annotated, from scratch or in a semi-supervised transfer learning setting. In addition to the segmentation loss, our setup allows to apply self-supervised consistency losses on the unlabeled parts of the training data. We evaluate the proposed method on challenging 2D and 3D segmentation problems in different microscopy modalities as well as on the popular CVPPP instance segmentation benchmark where we achieve state-of-the-art results. The code is available at: https://github.com/kreshuklab/spoco
Fully Dense Neural Network for the Automatic Modulation Recognition
Dec 07, 2019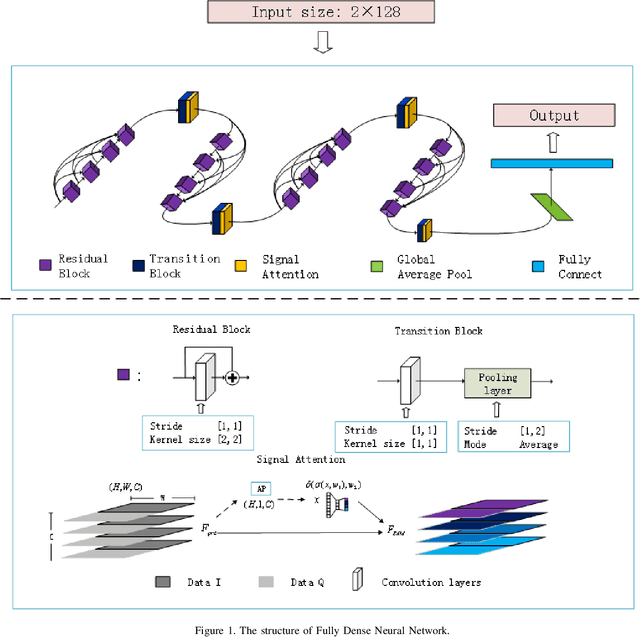
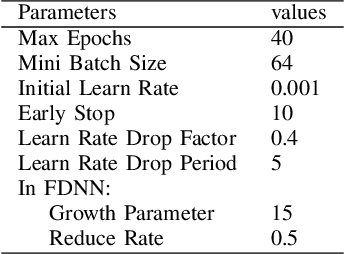

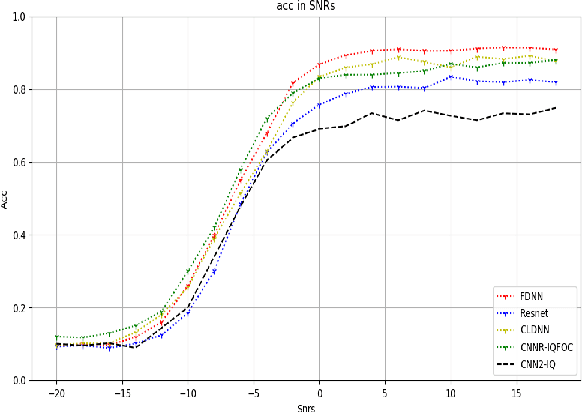
Nowadays, we mainly use various convolution neural network (CNN) structures to extract features from radio data or spectrogram in AMR. Based on expert experience and spectrograms, they not only increase the difficulty of preprocessing, but also consume a lot of memory. In order to directly use in-phase and quadrature (IQ) data obtained by the receiver and enhance the efficiency of network extraction features to improve the recognition rate of modulation mode, this paper proposes a new network structure called Fully Dense Neural Network (FDNN). This network uses residual blocks to extract features, dense connect to reduce model size, and adds attentions mechanism to recalibrate. Experiments on RML2016.10a show that this network has a higher recognition rate and lower model complexity. And it shows that the FDNN model with dense connections can not only extract features effectively but also greatly reduce model parameters, which also provides a significant contribution for the application of deep learning to the intelligent radio system.
Adaptive Ensemble of Classifiers with Regularization for Imbalanced Data Classification
Aug 13, 2019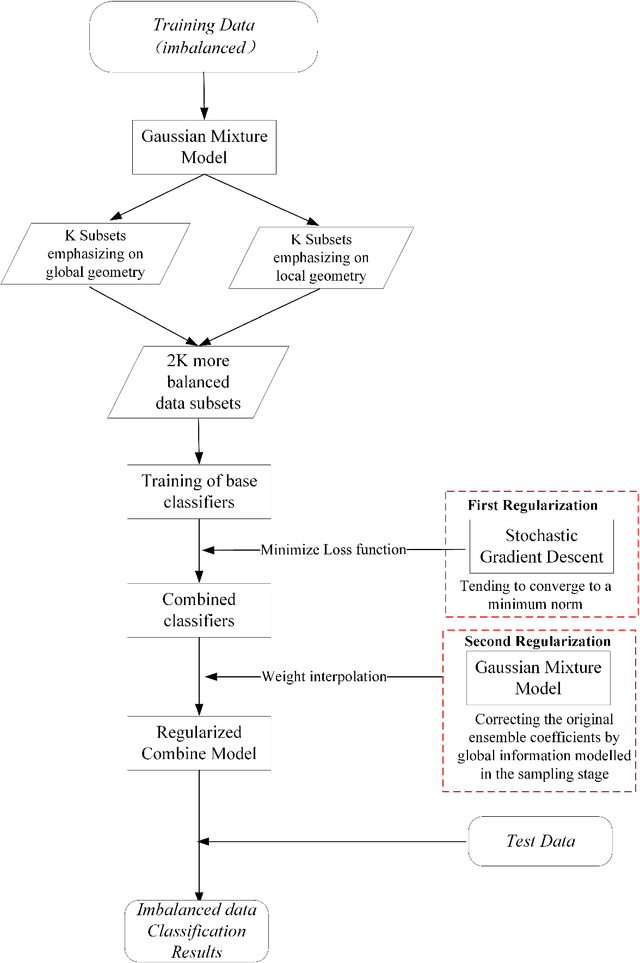

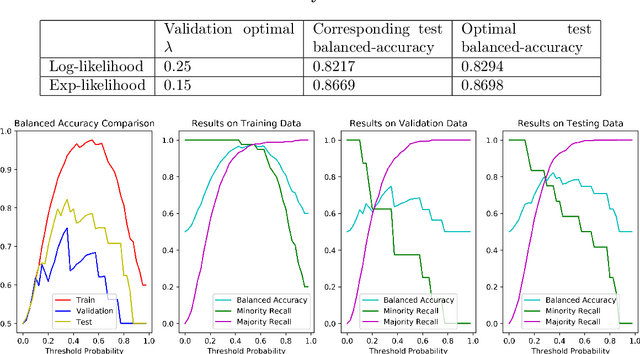

Dynamic ensembling of classifiers is an effective approach in processing label-imbalanced classifications. However, in dynamic ensemble methods, the combination of classifiers is usually determined by the local competence and conventional regularization methods are difficult to apply, leaving the technique prone to overfitting. In this paper, focusing on the binary label-imbalanced classification field, a novel method of Adaptive Ensemble of classifiers with Regularization (AER) has been proposed. The method deals with the overfitting problem from a perspective of implicit regularization. Specifically, it leverages the properties of Stochastic Gradient Descent (SGD) to obtain the solution with the minimum norm to achieve regularization, and interpolates ensemble weights via the global geometry of data to further prevent overfitting. The method enjoys a favorable time and memory complexity, and theoretical proofs show that algorithms implemented with AER paradigm have time and memory complexities upper-bounded by their original implementations. Furthermore, the proposed AER method is tested with a specific implementation based on Gradient Boosting Machine (XGBoost) on the three datasets: UCI Bioassay, KEEL Abalone19, and a set of GMM-sampled artificial dataset. Results show that the proposed AER algorithm can outperform the major existing algorithms based on multiple metrics, and Mcnemar's tests are applied to validate performance superiorities. To summarize, this work complements regularization for dynamic ensemble methods and develops an algorithm superior in grasping both the global and local geometry of data to alleviate overfitting in imbalanced data classification.