 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Dense Neural Network for the Automatic Modulation Recognition
Dec 07, 2019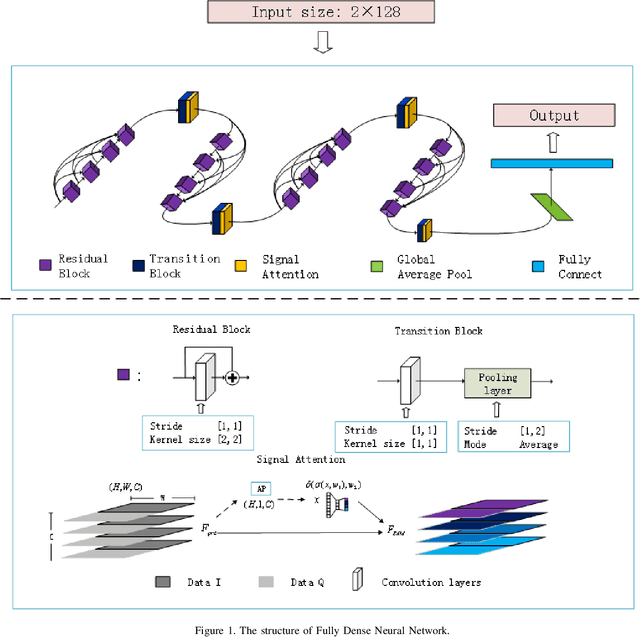

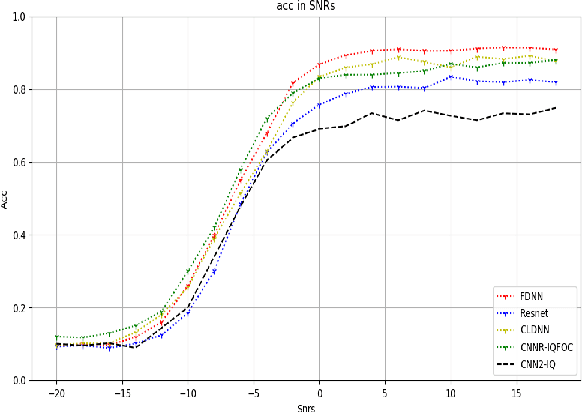
Nowadays, we mainly use various convolution neural network (CNN) structures to extract features from radio data or spectrogram in AMR. Based on expert experience and spectrograms, they not only increase the difficulty of preprocessing, but also consume a lot of memory. In order to directly use in-phase and quadrature (IQ) data obtained by the receiver and enhance the efficiency of network extraction features to improve the recognition rate of modulation mode, this paper proposes a new network structure called Fully Dense Neural Network (FDNN). This network uses residual blocks to extract features, dense connect to reduce model size, and adds attentions mechanism to recalibrate. Experiments on RML2016.10a show that this network has a higher recognition rate and lower model complexity. And it shows that the FDNN model with dense connections can not only extract features effectively but also greatly reduce model parameters, which also provides a significant contribution for the application of deep learning to the intelligent radio system.
A Radio Signal Modulation Recognition Algorithm Based on Residual Networks and Attention Mechanisms
Sep 27, 2019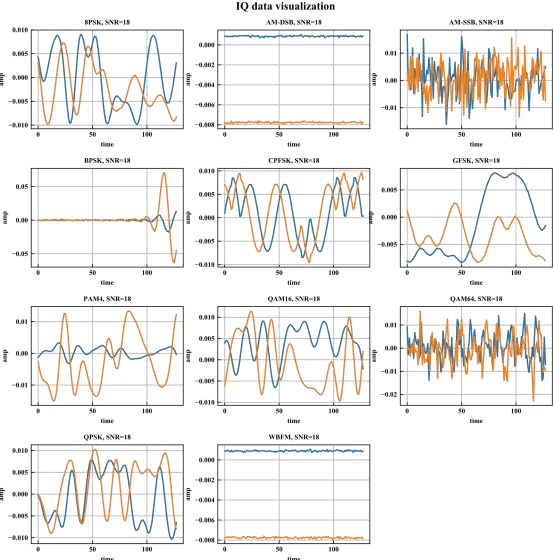
To solve the problem of inaccurate recognition of types of communication signal modulation, a RNN neural network recognition algorithm combining residual block network with attention mechanism is proposed. In this method, 10 kinds of communication signals with Gaussian white noise are generated from standard data sets, such as MASK, MPSK, MFSK, OFDM, 16QAM, AM and FM. Based on the original RNN neural network, residual block network is added to solve the problem of gradient disappearance caused by deep network layers. Attention mechanism is added to the network to accelerate the gradient descent. In the experiment, 16QAM, 2FSK and 4FSK are used as actual samples, IQ data frames of signals are used as input, and the RNN neural network combined with residual block network and attention mechanism is trained. The final recognition results show that the average recognition rate of real-time signals is over 93%. The network has high robustness and good use value.
Adaptive Ensemble of Classifiers with Regularization for Imbalanced Data Classification
Aug 13, 2019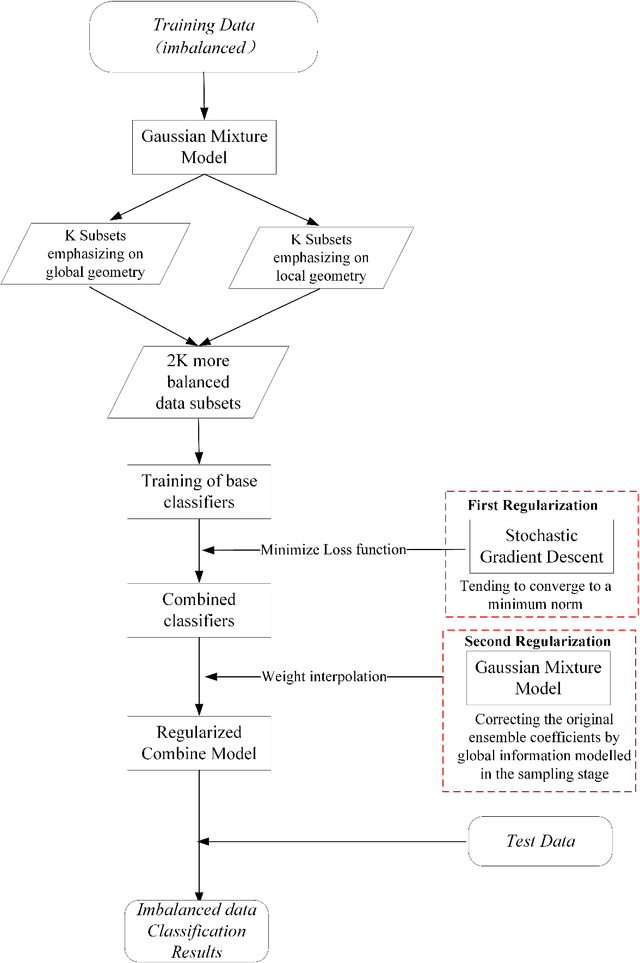

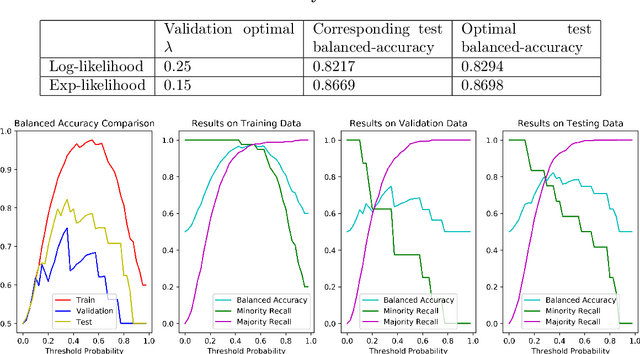

Dynamic ensembling of classifiers is an effective approach in processing label-imbalanced classifications. However, in dynamic ensemble methods, the combination of classifiers is usually determined by the local competence and conventional regularization methods are difficult to apply, leaving the technique prone to overfitting. In this paper, focusing on the binary label-imbalanced classification field, a novel method of Adaptive Ensemble of classifiers with Regularization (AER) has been proposed. The method deals with the overfitting problem from a perspective of implicit regularization. Specifically, it leverages the properties of Stochastic Gradient Descent (SGD) to obtain the solution with the minimum norm to achieve regularization, and interpolates ensemble weights via the global geometry of data to further prevent overfitting. The method enjoys a favorable time and memory complexity, and theoretical proofs show that algorithms implemented with AER paradigm have time and memory complexities upper-bounded by their original implementations. Furthermore, the proposed AER method is tested with a specific implementation based on Gradient Boosting Machine (XGBoost) on the three datasets: UCI Bioassay, KEEL Abalone19, and a set of GMM-sampled artificial dataset. Results show that the proposed AER algorithm can outperform the major existing algorithms based on multiple metrics, and Mcnemar's tests are applied to validate performance superiorities. To summarize, this work complements regularization for dynamic ensemble methods and develops an algorithm superior in grasping both the global and local geometry of data to alleviate overfitting in imbalanced data classification.
Multi-layer Attention Mechanism for Speech Keyword Recognition
Jul 10, 2019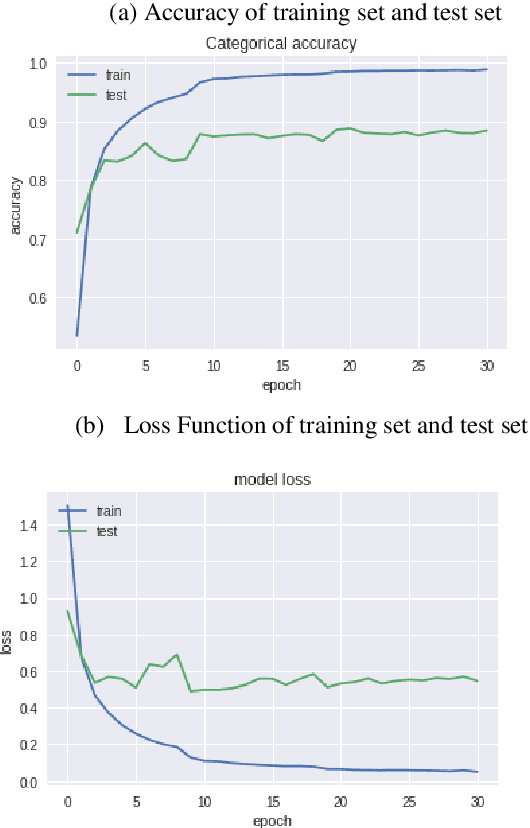
As an important part of speech recognition technology, automatic speech keyword recognition has been intensively studied in recent years. Such technology becomes especially pivotal under situations with limited infrastructures and computational resources, such as voice command recognition in vehicles and robot interaction. At present, the mainstream methods in automatic speech keyword recognition are based on long short-term memory (LSTM) networks with attention mechanism. However, due to inevitable information losses for the LSTM layer caused during feature extraction, the calculated attention weights are biased. In this paper, a novel approach, namely Multi-layer Attention Mechanism, is proposed to handle the inaccurate attention weights problem. The key idea is that, in addition to the conventional attention mechanism, information of layers prior to feature extraction and LSTM are introduced into attention weights calculations. Therefore, the attention weights are more accurate because the overall model can have more precise and focused areas. We conduct a comprehensive comparison and analysis on the keyword spotting performances on convolution neural network, bi-directional LSTM cyclic neural network, and cyclic neural network with the proposed attention mechanism on Google Speech Command datasets V2 datasets. Experimental results indicate favorable results for the proposed method and demonstrate the validity of the proposed method. The proposed multi-layer attention methods can be useful for other researches related to object spotting.
Vector Quantization as Sparse Least Square Optimization
Sep 24, 2018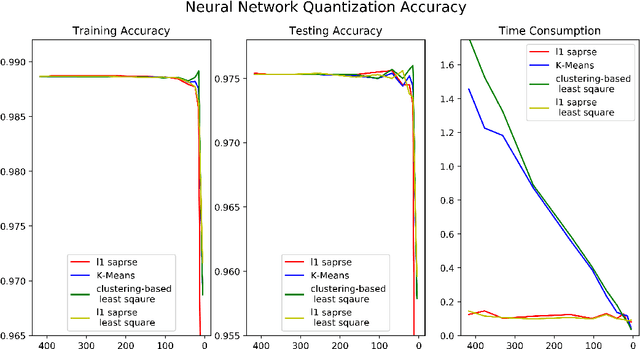
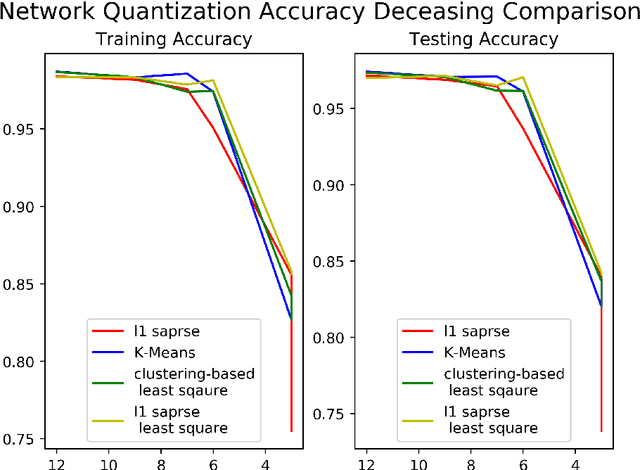
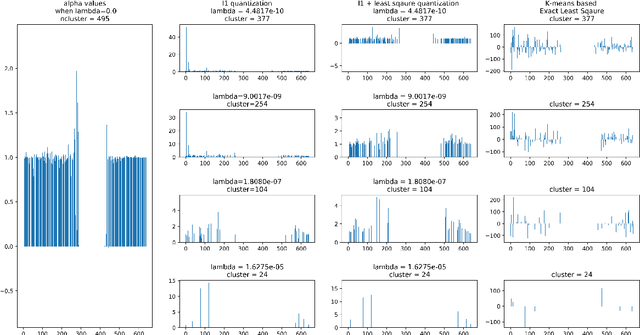
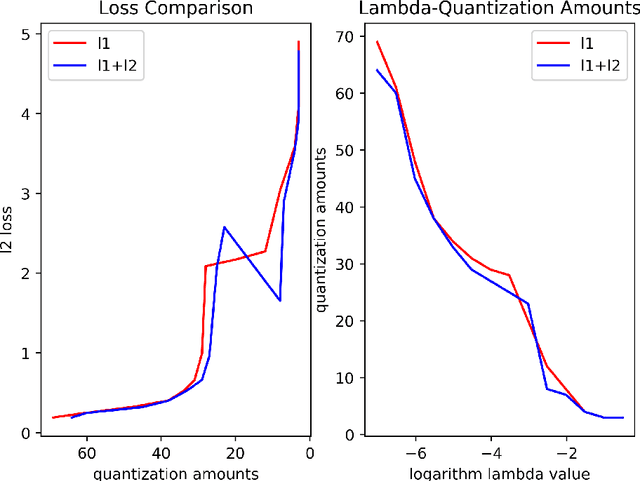
Vector quantization aims to form new vectors/matrices with shared values close to the original. It could compress data with acceptable information loss and could be of great usefulness in areas like Image Processing, Pattern Recognition, and Machine Learning. In this paper, the problem of vector quantization is examined from a new perspective, namely sparse least square optimization. Specifically, inspired by the property of sparsity of Lasso, a novel quantization algorithm based on $l_1$ least square is proposed and implemented. Similar schemes with $l_1 + l_2$ combination penalization and $l_0$ regularization are simultaneously proposed. In addition, to produce quantization results with given amount of quantized values(instead of penalization coefficient $\lambda$), this paper proposed an iterative sparse least square method and a cluster-based least square quantization method. It is also noticed that the later method is mathematically equivalent to an improved version of the existed clustering-based quantization algorithm, although the two algorithms originated from different intuitions. The algorithms proposed were tested under three scenarios of data and their computational performance, including information loss, time consumption and the distribution of the value of sparse vectors were compared and analyzed. The paper offers a new perspective to probe the area of vector quantization, and the algorithms proposed could offer better performance especially when the required post-quantization value amounts are not on a tiny scale.