 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiling artifacts and trade-offs of feature normalization in the segmentation of large biological images
Mar 25, 2025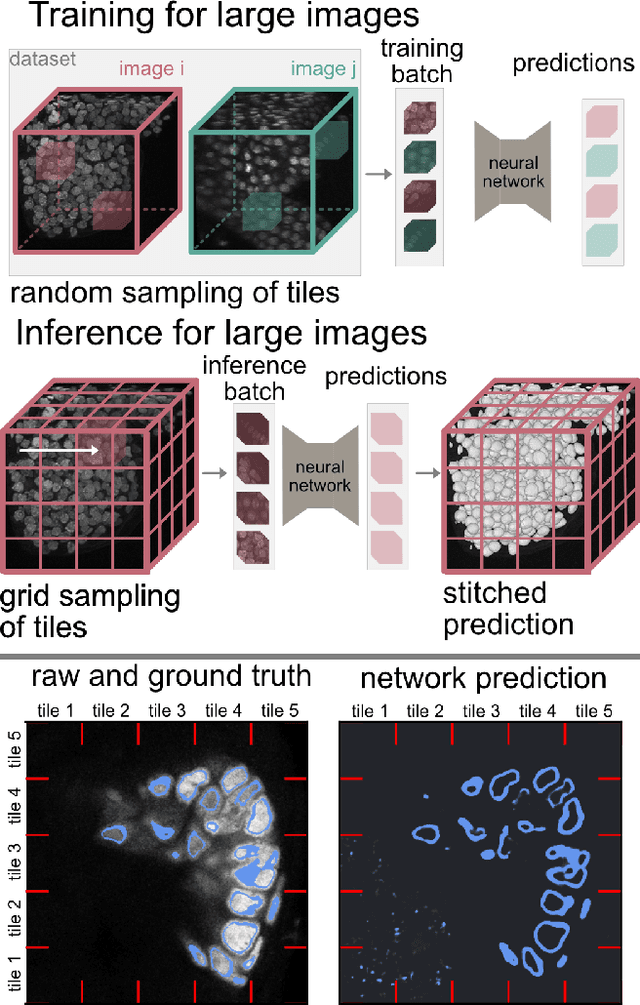
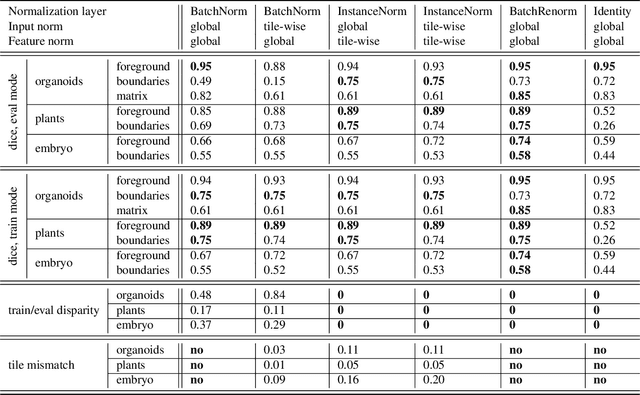
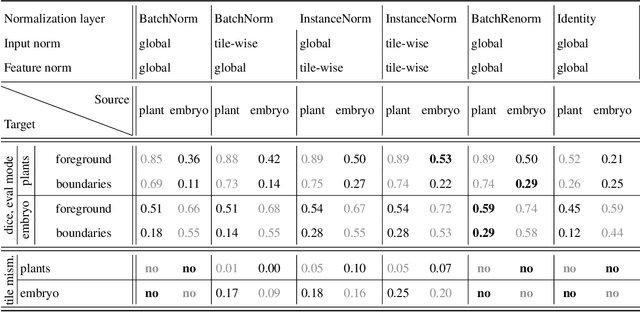
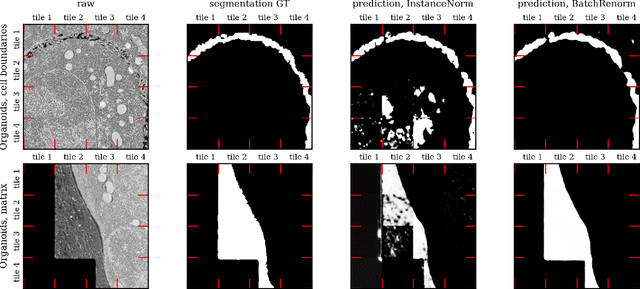
Segmentation of very large images is a common problem in microscopy, medical imaging or remote sensing. The problem is usually addressed by sliding window inference, which can theoretically lead to seamlessly stitched predictions. However, in practice many of the popular pipelines still suffer from tiling artifacts. We investigate the root cause of these issues and show that they stem from the normalization layers within the neural networks. We propose indicators to detect normalization issues and further explore the trade-offs between artifact-free and high-quality predictions, using three diverse microscopy datasets as examples. Finally, we propose to use BatchRenorm as the most suitable normalization strategy, which effectively removes tiling artifacts and enhances transfer performance, thereby improving the reusability of trained networks for new datasets.
How to Build the Virtual Cell with Artificial Intelligence: Priorities and Opportunities
Sep 18, 2024

The cell is arguably the smallest unit of life and is central to understanding biology. Accurate modeling of cells is important for this understanding as well as for determining the root causes of disease. Recent advances in artificial intelligence (AI), combined with the ability to generate large-scale experimental data, present novel opportunities to model cells. Here we propose a vision of AI-powered Virtual Cells, where robust representations of cells and cellular systems under different conditions are directly learned from growing biological data across measurements and scales. We discuss desired capabilities of AI Virtual Cells, including generating universal representations of biological entities across scales, and facilitating interpretable in silico experiments to predict and understand their behavior using Virtual Instruments. We further address the challenges, opportunities and requirements to realize this vision including data needs, evaluation strategies, and community standards and engagement to ensure biological accuracy and broad utility. We envision a future where AI Virtual Cells help identify new drug targets, predict cellular responses to perturbations, as well as scale hypothesis exploration. With open science collaborations across the biomedical ecosystem that includes academia, philanthropy, and the biopharma and AI industries, a comprehensive predictive understanding of cell mechanisms and interactions is within reach.
MIFA: Metadata, Incentives, Formats, and Accessibility guidelines to improve the reuse of AI datasets for bioimage analysis
Nov 22, 2023



Artificial Intelligence methods are powerful tools for biological image analysis and processing. High-quality annotated images are key to training and developing new methods, but access to such data is often hindered by the lack of standards for sharing datasets. We brought together community experts in a workshop to develop guidelines to improve the reuse of bioimages and annotations for AI applications. These include standards on data formats, metadata, data presentation and sharing, and incentives to generate new datasets. We are positive that the MIFA (Metadata, Incentives, Formats, and Accessibility) recommendations will accelerate the development of AI tools for bioimage analysis by facilitating access to high quality training data.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022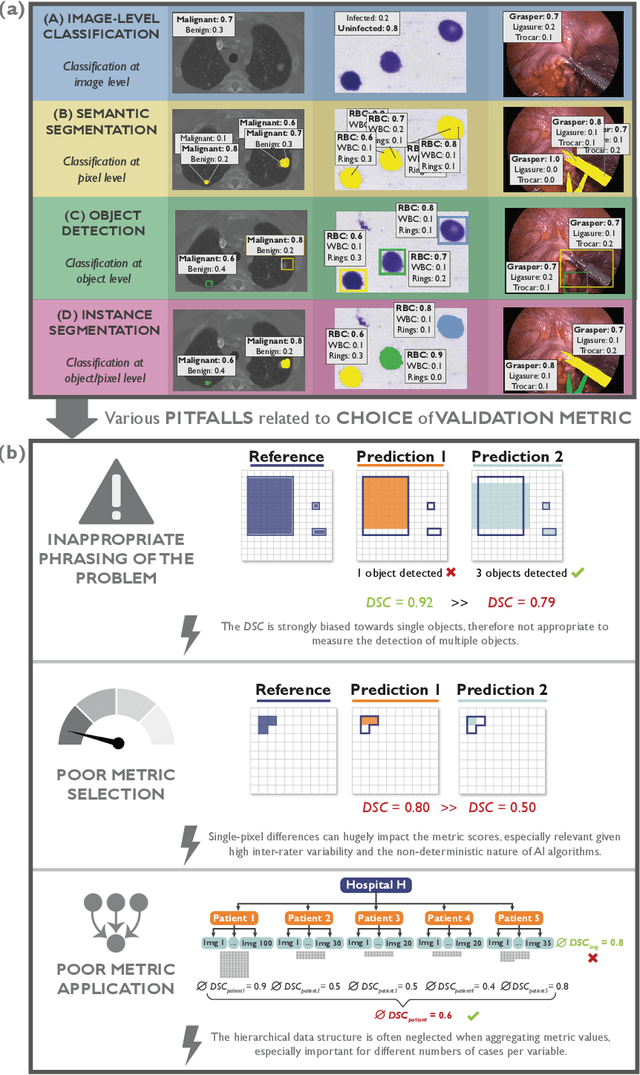
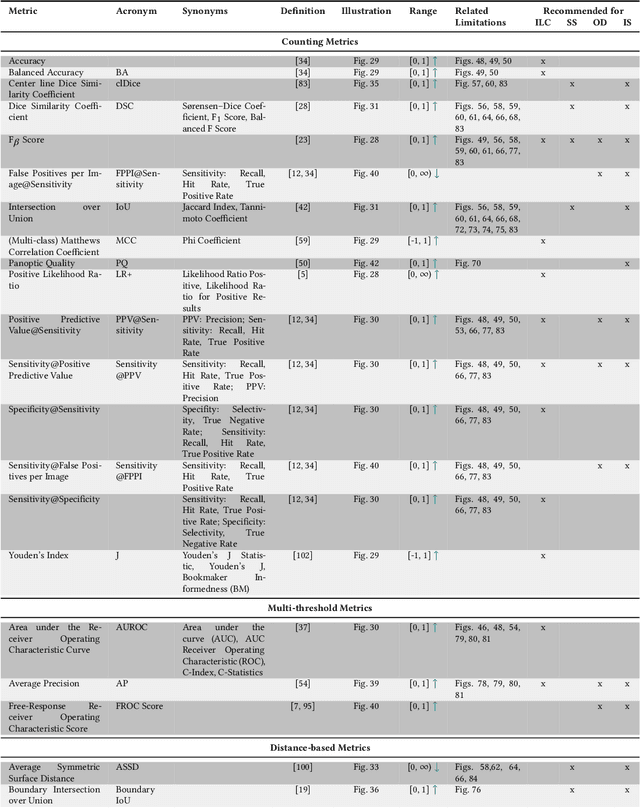
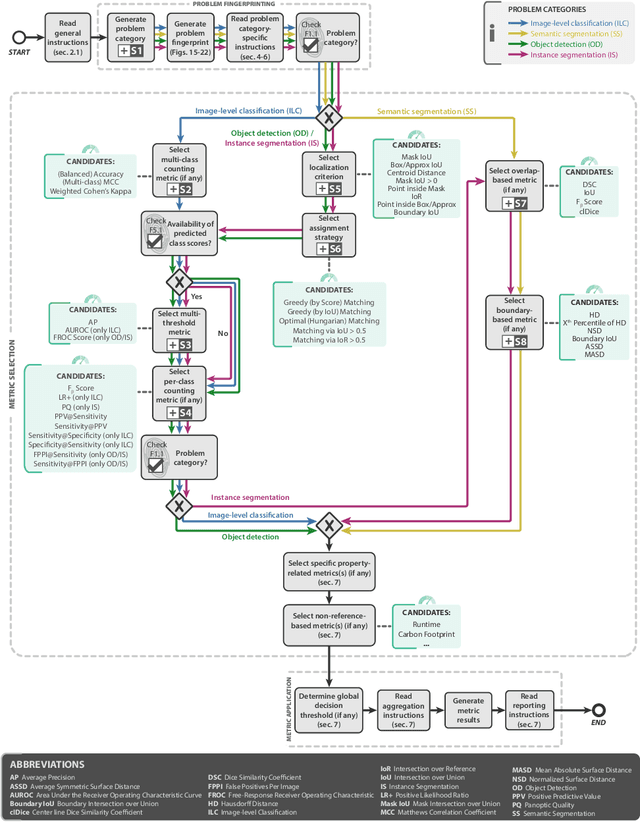
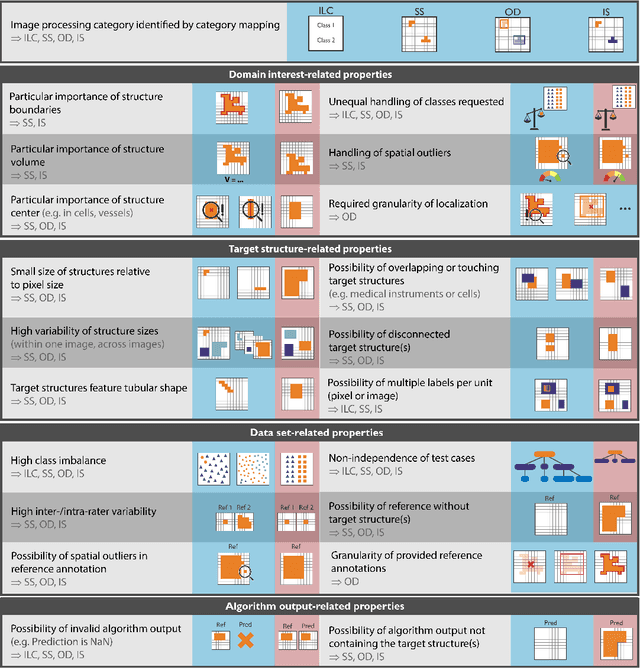
The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
Stateless actor-critic for instance segmentation with high-level priors
Jul 06, 2021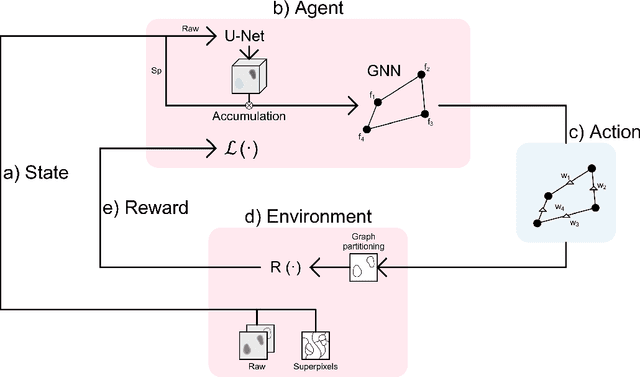

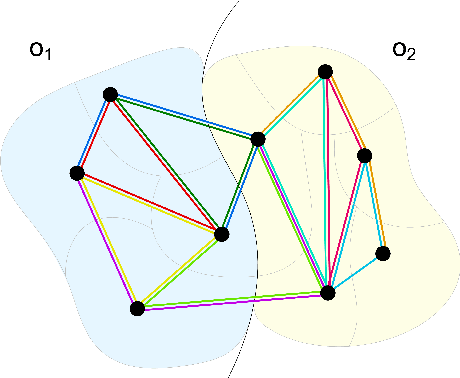

Instance segmentation is an important computer vision problem which remains challenging despite impressive recent advances due to deep learning-based methods. Given sufficient training data, fully supervised methods can yield excellent performance, but annotation of ground-truth data remains a major bottleneck, especially for biomedical applications where it has to be performed by domain experts. The amount of labels required can be drastically reduced by using rules derived from prior knowledge to guide the segmentation. However, these rules are in general not differentiable and thus cannot be used with existing methods. Here, we relax this requirement by using stateless actor critic reinforcement learning, which enables non-differentiable rewards. We formulate the instance segmentation problem as graph partitioning and the actor critic predicts the edge weights driven by the rewards, which are based on the conformity of segmented instances to high-level priors on object shape, position or size. The experiments on toy and real datasets demonstrate that we can achieve excellent performance without any direct supervision based only on a rich set of priors.
Sparse Object-level Supervision for Instance Segmentation with Pixel Embeddings
Mar 26, 2021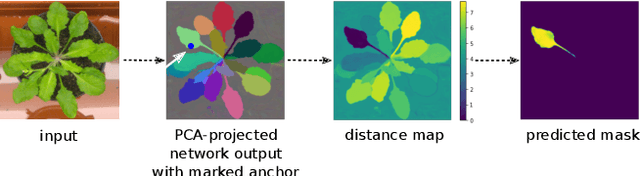

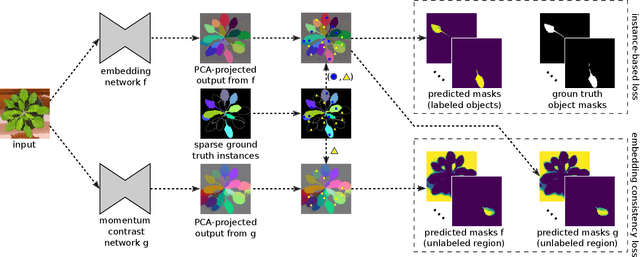

Most state-of-the-art instance segmentation methods have to be trained on densely annotated images. While difficult in general, this requirement is especially daunting for biomedical images, where domain expertise is often required for annotation. We propose to address the dense annotation bottleneck by introducing a proposal-free segmentation approach based on non-spatial embeddings, which exploits the structure of the learned embedding space to extract individual instances in a differentiable way. The segmentation loss can then be applied directly on the instances and the overall method can be trained on ground truth images where only a few objects are annotated, from scratch or in a semi-supervised transfer learning setting. In addition to the segmentation loss, our setup allows to apply self-supervised consistency losses on the unlabeled parts of the training data. We evaluate the proposed method on challenging 2D and 3D segmentation problems in different microscopy modalities as well as on the popular CVPPP instance segmentation benchmark where we achieve state-of-the-art results. The code is available at: https://github.com/kreshuklab/spoco
Proposal-Free Volumetric Instance Segmentation from Latent Single-Instance Masks
Sep 10, 2020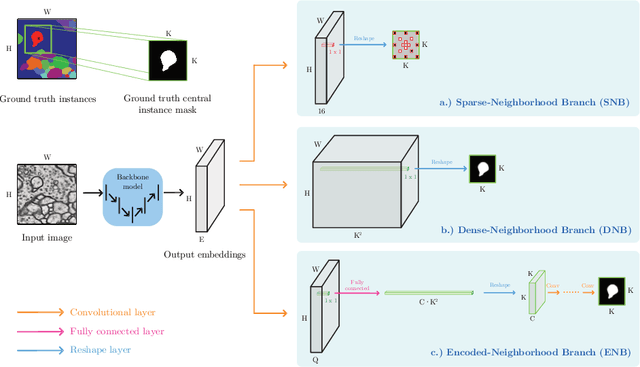
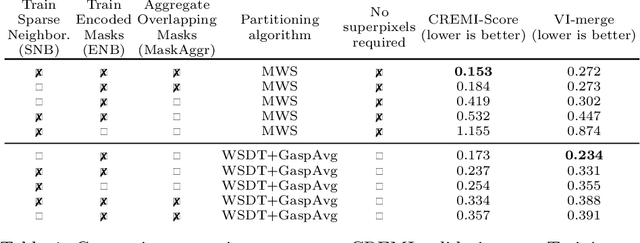

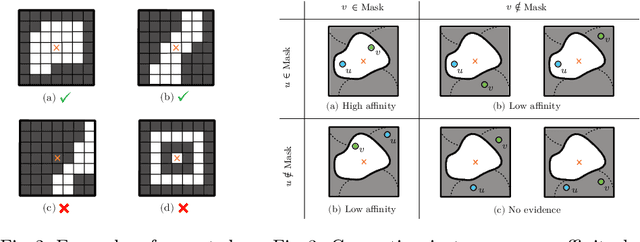
This work introduces a new proposal-free instance segmentation method that builds on single-instance segmentation masks predicted across the entire image in a sliding window style. In contrast to related approaches, our method concurrently predicts all masks, one for each pixel, and thus resolves any conflict jointly across the entire image. Specifically, predictions from overlapping masks are combined into edge weights of a signed graph that is subsequently partitioned to obtain all final instances concurrently. The result is a parameter-free method that is strongly robust to noise and prioritizes predictions with the highest consensus across overlapping masks. All masks are decoded from a low dimensional latent representation, which results in great memory savings strictly required for applications to large volumetric images. We test our method on the challenging CREMI 2016 neuron segmentation benchmark where it achieves competitive scores.
The Semantic Mutex Watershed for Efficient Bottom-Up Semantic Instance Segmentation
Dec 29, 2019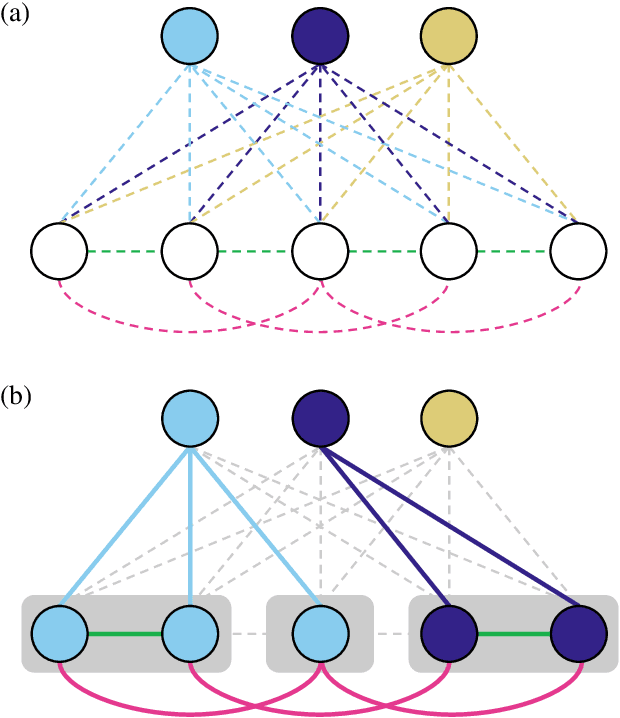


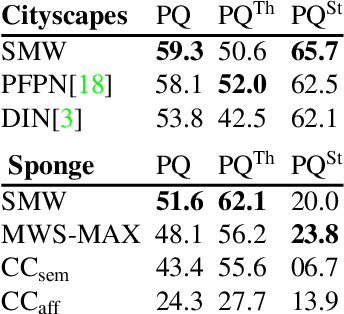
Semantic instance segmentation is the task of simultaneously partitioning an image into distinct segments while associating each pixel with a class label. In commonly used pipelines, segmentation and label assignment are solved separately since joint optimization is computationally expensive. We propose a greedy algorithm for joint graph partitioning and labeling derived from the efficient Mutex Watershed partitioning algorithm. It optimizes an objective function closely related to the Symmetric Multiway Cut objective and empirically shows efficient scaling behavior. Due to the algorithm's efficiency it can operate directly on pixels without prior over-segmentation of the image into superpixels. We evaluate the performance on the Cityscapes dataset (2D urban scenes) and on a 3D microscopy volume. In urban scenes, the proposed algorithm combined with current deep neural networks outperforms the strong baseline of `Panoptic Feature Pyramid Networks' by Kirillov et al. (2019). In the 3D electron microscopy images, we show explicitly that our joint formulation outperforms a separate optimization of the partitioning and labeling problems.
Synthetic patches, real images: screening for centrosome aberrations in EM images of human cancer cells
Aug 27, 2019



Recent advances in high-throughput electron microscopy imaging enable detailed study of centrosome aberrations in cancer cells. While the image acquisition in such pipelines is automated, manual detection of centrioles is still necessary to select cells for re-imaging at higher magnification. In this contribution we propose an algorithm which performs this step automatically and with high accuracy. From the image labels produced by human experts and a 3D model of a centriole we construct an additional training set with patch-level labels. A two-level DenseNet is trained on the hybrid training data with synthetic patches and real images, achieving much better results on real patient data than training only at the image-level. The code can be found at https://github.com/kreshuklab/centriole_detection.