 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Accuracy and Maintainability in Nuclear Plant Data Retrieval: A Function-Calling LLM Approach Over NL-to-SQL
Jun 10, 2025Retrieving operational data from nuclear power plants requires exceptional accuracy and transparency due to the criticality of the decisions it supports. Traditionally, natural language to SQL (NL-to-SQL) approaches have been explored for querying such data. While NL-to-SQL promises ease of use, it poses significant risks: end-users cannot easily validate generated SQL queries, and legacy nuclear plant databases -- often complex and poorly structured -- complicate query generation due to decades of incremental modifications. These challenges increase the likelihood of inaccuracies and reduce trust in the approach. In this work, we propose an alternative paradigm: leveraging function-calling large language models (LLMs) to address these challenges. Instead of directly generating SQL queries, we define a set of pre-approved, purpose-specific functions representing common use cases. Queries are processed by invoking these functions, which encapsulate validated SQL logic. This hybrid approach mitigates the risks associated with direct NL-to-SQL translations by ensuring that SQL queries are reviewed and optimized by experts before deployment. While this strategy introduces the upfront cost of developing and maintaining the function library, we demonstrate how NL-to-SQL tools can assist in the initial generation of function code, allowing experts to focus on validation rather than creation. Our study includes a performance comparison between direct NL-to-SQL generation and the proposed function-based approach, highlighting improvements in accuracy and maintainability. This work underscores the importance of balancing user accessibility with operational safety and provides a novel, actionable framework for robust data retrieval in critical systems.
Towards Secure and Private Language Models for Nuclear Power Plants
Jun 10, 2025This paper introduces a domain-specific Large Language Model for nuclear applications, built from the publicly accessible Essential CANDU textbook. Drawing on a compact Transformer-based architecture, the model is trained on a single GPU to protect the sensitive data inherent in nuclear operations. Despite relying on a relatively small dataset, it shows encouraging signs of capturing specialized nuclear vocabulary, though the generated text sometimes lacks syntactic coherence. By focusing exclusively on nuclear content, this approach demonstrates the feasibility of in-house LLM solutions that align with rigorous cybersecurity and data confidentiality standards. Early successes in text generation underscore the model's utility for specialized tasks, while also revealing the need for richer corpora, more sophisticated preprocessing, and instruction fine-tuning to enhance domain accuracy. Future directions include extending the dataset to cover diverse nuclear subtopics, refining tokenization to reduce noise, and systematically evaluating the model's readiness for real-world applications in nuclear domain.
Managing the Impact of Sensor's Thermal Noise in Machine Learning for Nuclear Applications
Oct 02, 2023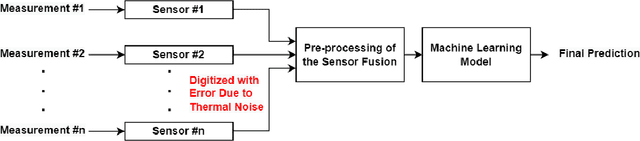
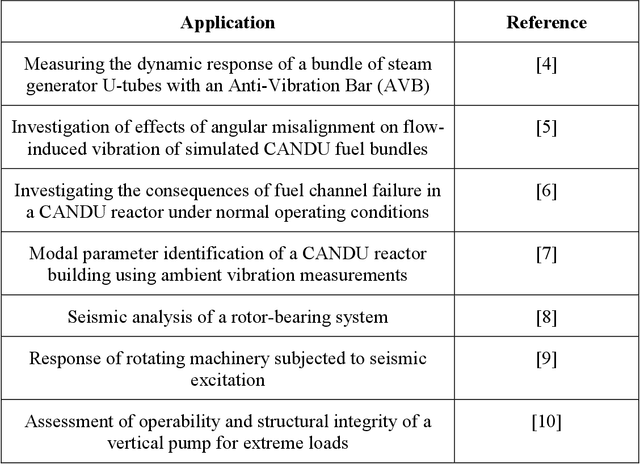
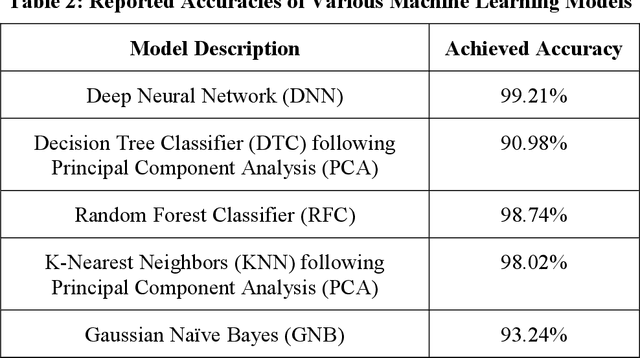
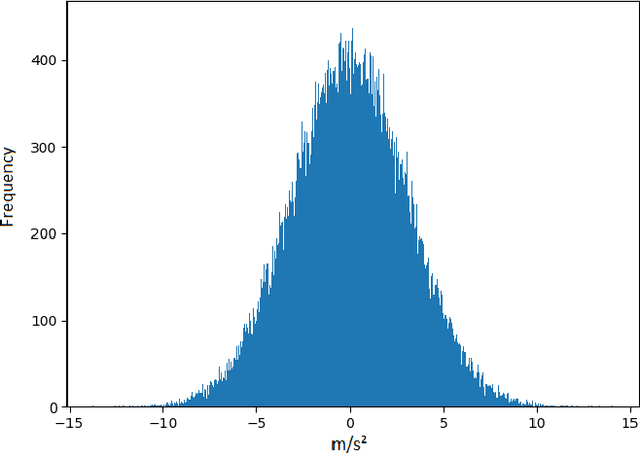
Sensors such as accelerometers, magnetometers, and gyroscopes are frequently utilized to perform measurements in nuclear power plants. For example, accelerometers are used for vibration monitoring of critical systems. With the recent rise of machine learning, data captured from such sensors can be used to build machine learning models for predictive maintenance and automation. However, these sensors are known to have thermal noise that can affect the sensor's accuracy. Thermal noise differs between sensors in terms of signal-to-noise ratio (SNR). This thermal noise will cause an accuracy drop in sensor-fusion-based machine learning models when deployed in production. This paper lists some applications for Canada Deuterium Uranium (CANDU) reactors where such sensors are used and therefore can be impacted by the thermal noise issue if machine learning is utilized. A list of recommendations to help mitigate the issue when building future machine learning models for nuclear applications based on sensor fusion is provided. Additionally, this paper demonstrates that machine learning algorithms can be impacted differently by the issue, therefore selecting a more resilient model can help in mitigating it.
Subtractor-Based CNN Inference Accelerator
Oct 02, 2023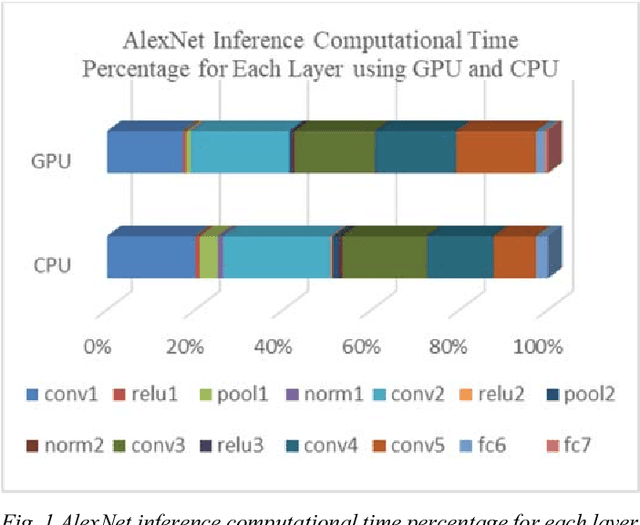
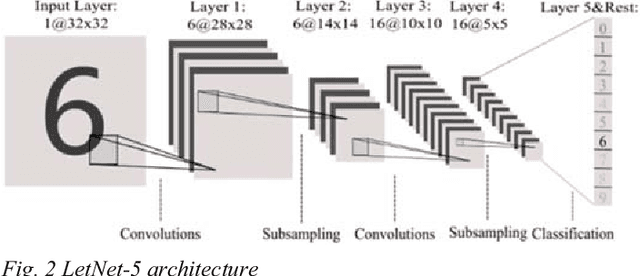
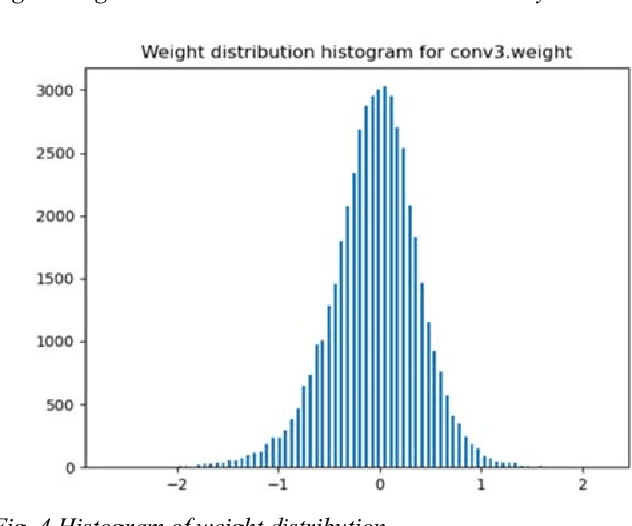
This paper presents a novel method to boost the performance of CNN inference accelerators by utilizing subtractors. The proposed CNN preprocessing accelerator relies on sorting, grouping, and rounding the weights to create combinations that allow for the replacement of one multiplication operation and addition operation by a single subtraction operation when applying convolution during inference. Given the high cost of multiplication in terms of power and area, replacing it with subtraction allows for a performance boost by reducing power and area. The proposed method allows for controlling the trade-off between performance gains and accuracy loss through increasing or decreasing the usage of subtractors. With a rounding size of 0.05 and by utilizing LeNet-5 with the MNIST dataset, the proposed design can achieve 32.03% power savings and a 24.59% reduction in area at the cost of only 0.1% in terms of accuracy loss.
Using Deep Learning to Automate the Detection of Flaws in Nuclear Fuel Channel UT Scans
Feb 26, 2021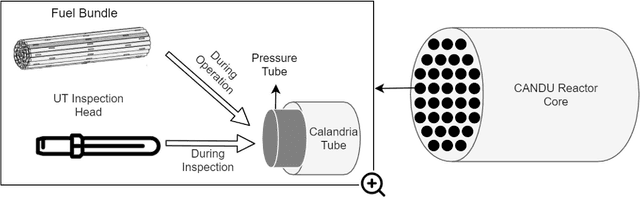

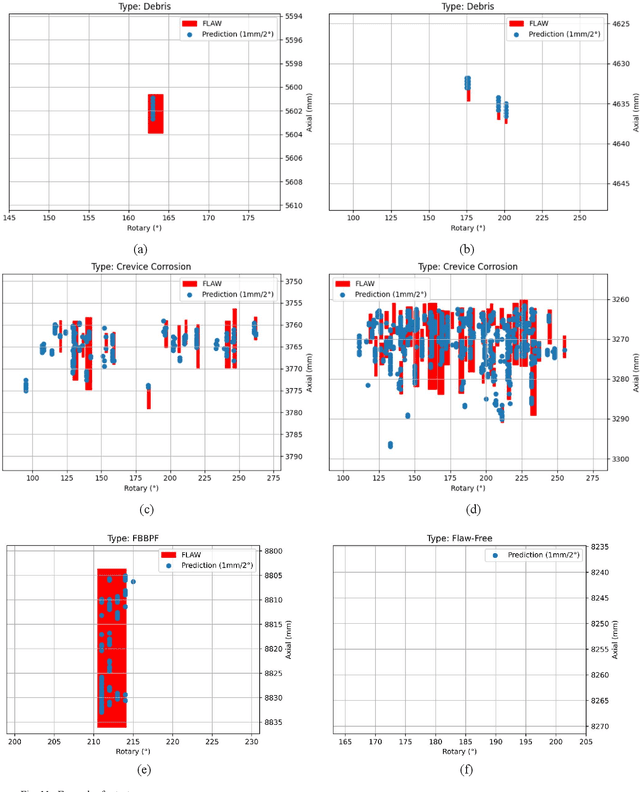

Nuclear reactor inspections are critical to ensure the safety and reliability of plants operation. Inspections occur during planned outages and include the inspection of the reactor's fuel channels. In Canada, Ultrasonic Testing (UT) is used to inspect the health of fuel channels in Canada's Deuterium Uranium (CANDU) reactors. Currently, analysis of the UT scans is performed by manual visualization and measurement to locate, characterize, and disposition flaws. Therefore, there is a motivation to develop an automated method that is fast and accurate. In this paper, a proof of concept (PoC) that automates the detection of flaws in nuclear fuel channel UT scans using a convolutional neural network (CNN) is presented. This industry research was conducted at Alithya Digital Technology Corporation in Pickering, Ontario, Canada. The CNN model was trained after constructing a dataset using historical UT scans and the corresponding inspection results. This data was obtained from a large nuclear power generation company in Ontario. The requirement for this prototype was to identify the location of at least a portion of each flaw in fuel channel scans while minimizing false positives (FPs). This allows for automatic detection of the location of each flaw where further manual analysis is performed to identify the extent and the type of the flaw. Based on the defined requirement, the proposed model was able to achieve 100% accuracy for UT scans with minor chatter and a 100% sensitivity with minimal FPs for complicated UT scans with severe chatter using 18 UT full test scans.
A Comparative Study on Machine Learning Algorithms for the Control of a Wall Following Robot
Dec 26, 2019



A comparison of the performance of various machine learning models to predict the direction of a wall following robot is presented in this paper. The models were trained using an open-source dataset that contains 24 ultrasound sensors readings and the corresponding direction for each sample. This dataset was captured using SCITOS G5 mobile robot by placing the sensors on the robot waist. In addition to the full format with 24 sensors per record, the dataset has two simplified formats with 4 and 2 input sensor readings per record. Several control models were proposed previously for this dataset using all three dataset formats. In this paper, two primary research contributions are presented. First, presenting machine learning models with accuracies higher than all previously proposed models for this dataset using all three formats. A perfect solution for the 4 and 2 inputs sensors formats is presented using Decision Tree Classifier by achieving a mean accuracy of 100%. On the other hand, a mean accuracy of 99.82% was achieves using the 24 sensor inputs by employing the Gradient Boost Classifier. Second, presenting a comparative study on the performance of different machine learning and deep learning algorithms on this dataset. Therefore, providing an overall insight on the performance of these algorithms for similar sensor fusion problems. All the models in this paper were evaluated using Monte-Carlo cross-validation.
Deep Learning Training with Simulated Approximate Multipliers
Dec 26, 2019



This paper presents by simulation how approximate multipliers can be utilized to enhance the training performance of convolutional neural networks (CNNs). Approximate multipliers have significantly better performance in terms of speed, power, and area compared to exact multipliers. However, approximate multipliers have an inaccuracy which is defined in terms of the Mean Relative Error (MRE). To assess the applicability of approximate multipliers in enhancing CNN training performance, a simulation for the impact of approximate multipliers error on CNN training is presented. The paper demonstrates that using approximate multipliers for CNN training can significantly enhance the performance in terms of speed, power, and area at the cost of a small negative impact on the achieved accuracy. Additionally, the paper proposes a hybrid training method which mitigates this negative impact on the accuracy. Using the proposed hybrid method, the training can start using approximate multipliers then switches to exact multipliers for the last few epochs. Using this method, the performance benefits of approximate multipliers in terms of speed, power, and area can be attained for a large portion of the training stage. On the other hand, the negative impact on the accuracy is diminished by using the exact multipliers for the last epochs of training.