 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdered Reliability Direct Error Pattern Testing Decoding Algorithm
Oct 18, 2023



We introduce a novel universal soft-decision decoding algorithm for binary block codes called ordered reliability direct error pattern testing (ORDEPT). Our results, obtained for a variety of popular short high-rate codes, demonstrate that ORDEPT outperforms state-of-the-art decoding algorithms of comparable complexity such as ordered reliability bits guessing random additive noise decoding (ORBGRAND) in terms of the decoding error probability and latency. The improvements carry on to the iterative decoding of product codes and convolutional product-like codes, where we present a new adaptive decoding algorithm and demonstrate the ability of ORDEPT to efficiently find multiple candidate codewords to produce soft output.
Subtractor-Based CNN Inference Accelerator
Oct 02, 2023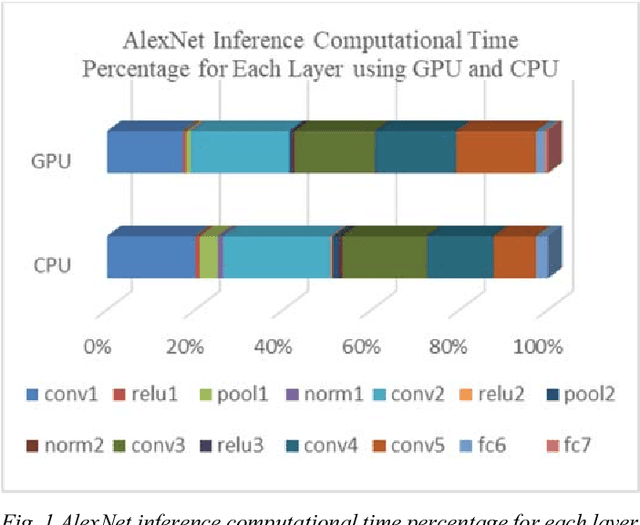
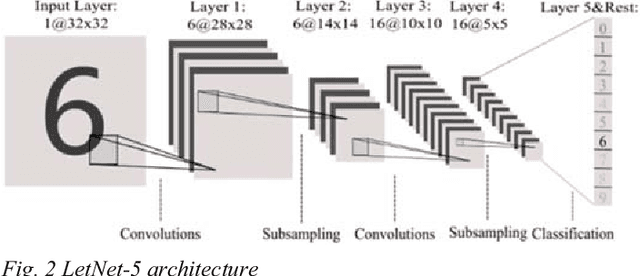
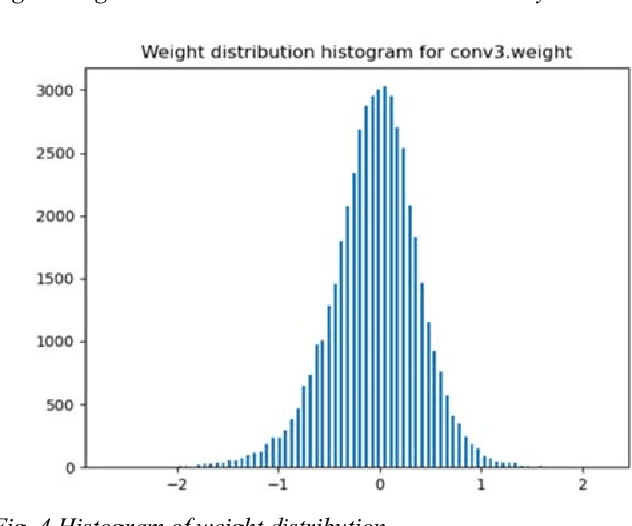
This paper presents a novel method to boost the performance of CNN inference accelerators by utilizing subtractors. The proposed CNN preprocessing accelerator relies on sorting, grouping, and rounding the weights to create combinations that allow for the replacement of one multiplication operation and addition operation by a single subtraction operation when applying convolution during inference. Given the high cost of multiplication in terms of power and area, replacing it with subtraction allows for a performance boost by reducing power and area. The proposed method allows for controlling the trade-off between performance gains and accuracy loss through increasing or decreasing the usage of subtractors. With a rounding size of 0.05 and by utilizing LeNet-5 with the MNIST dataset, the proposed design can achieve 32.03% power savings and a 24.59% reduction in area at the cost of only 0.1% in terms of accuracy loss.
A Comparative Study on Machine Learning Algorithms for the Control of a Wall Following Robot
Dec 26, 2019



A comparison of the performance of various machine learning models to predict the direction of a wall following robot is presented in this paper. The models were trained using an open-source dataset that contains 24 ultrasound sensors readings and the corresponding direction for each sample. This dataset was captured using SCITOS G5 mobile robot by placing the sensors on the robot waist. In addition to the full format with 24 sensors per record, the dataset has two simplified formats with 4 and 2 input sensor readings per record. Several control models were proposed previously for this dataset using all three dataset formats. In this paper, two primary research contributions are presented. First, presenting machine learning models with accuracies higher than all previously proposed models for this dataset using all three formats. A perfect solution for the 4 and 2 inputs sensors formats is presented using Decision Tree Classifier by achieving a mean accuracy of 100%. On the other hand, a mean accuracy of 99.82% was achieves using the 24 sensor inputs by employing the Gradient Boost Classifier. Second, presenting a comparative study on the performance of different machine learning and deep learning algorithms on this dataset. Therefore, providing an overall insight on the performance of these algorithms for similar sensor fusion problems. All the models in this paper were evaluated using Monte-Carlo cross-validation.
Deep Learning Training with Simulated Approximate Multipliers
Dec 26, 2019



This paper presents by simulation how approximate multipliers can be utilized to enhance the training performance of convolutional neural networks (CNNs). Approximate multipliers have significantly better performance in terms of speed, power, and area compared to exact multipliers. However, approximate multipliers have an inaccuracy which is defined in terms of the Mean Relative Error (MRE). To assess the applicability of approximate multipliers in enhancing CNN training performance, a simulation for the impact of approximate multipliers error on CNN training is presented. The paper demonstrates that using approximate multipliers for CNN training can significantly enhance the performance in terms of speed, power, and area at the cost of a small negative impact on the achieved accuracy. Additionally, the paper proposes a hybrid training method which mitigates this negative impact on the accuracy. Using the proposed hybrid method, the training can start using approximate multipliers then switches to exact multipliers for the last few epochs. Using this method, the performance benefits of approximate multipliers in terms of speed, power, and area can be attained for a large portion of the training stage. On the other hand, the negative impact on the accuracy is diminished by using the exact multipliers for the last epochs of training.