 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid CNN Based Attention with Category Prior for User Image Behavior Modeling
May 05, 2022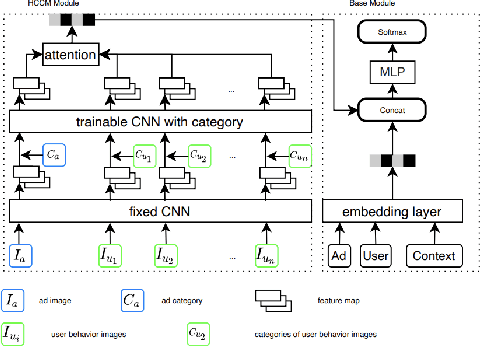
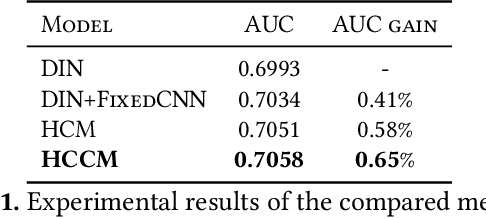
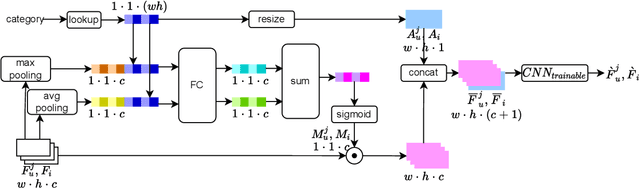
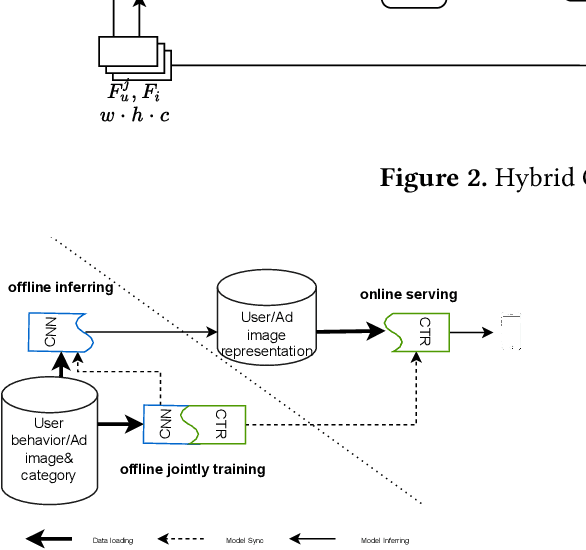
User historical behaviors are proved useful for Click Through Rate (CTR) prediction in online advertising system. In Meituan, one of the largest e-commerce platform in China, an item is typically displayed with its image and whether a user clicks the item or not is usually influenced by its image, which implies that user's image behaviors are helpful for understanding user's visual preference and improving the accuracy of CTR prediction. Existing user image behavior models typically use a two-stage architecture, which extracts visual embeddings of images through off-the-shelf Convolutional Neural Networks (CNNs) in the first stage, and then jointly trains a CTR model with those visual embeddings and non-visual features. We find that the two-stage architecture is sub-optimal for CTR prediction. Meanwhile, precisely labeled categories in online ad systems contain abundant visual prior information, which can enhance the modeling of user image behaviors. However, off-the-shelf CNNs without category prior may extract category unrelated features, limiting CNN's expression ability. To address the two issues, we propose a hybrid CNN based attention module, unifying user's image behaviors and category prior, for CTR prediction. Our approach achieves significant improvements in both online and offline experiments on a billion scale real serving dataset.
Deep Position-wise Interaction Network for CTR Prediction
Jun 17, 2021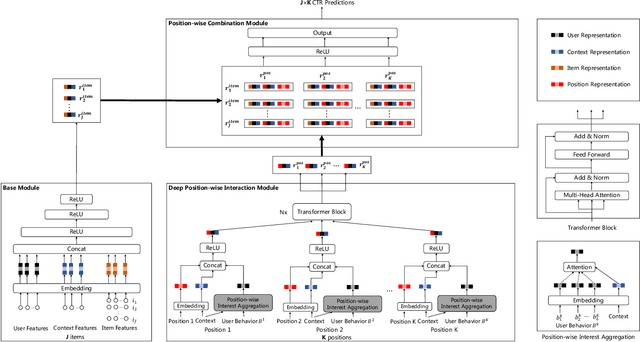
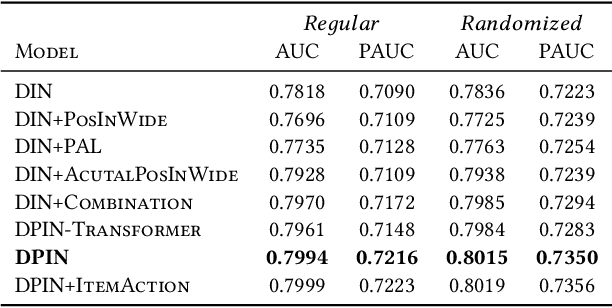
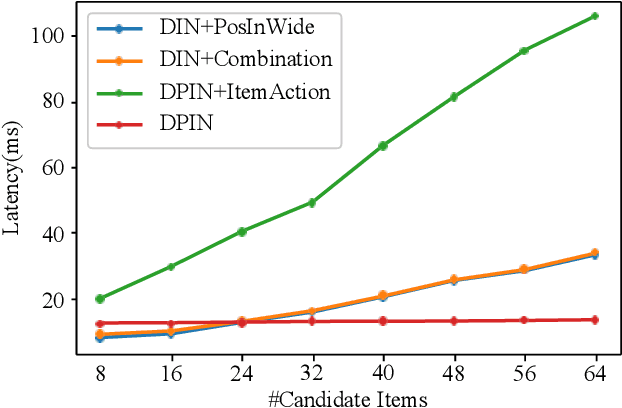
Click-through rate (CTR) prediction plays an important role in online advertising and recommender systems. In practice, the training of CTR models depends on click data which is intrinsically biased towards higher positions since higher position has higher CTR by nature. Existing methods such as actual position training with fixed position inference and inverse propensity weighted training with no position inference alleviate the bias problem to some extend. However, the different treatment of position information between training and inference will inevitably lead to inconsistency and sub-optimal online performance. Meanwhile, the basic assumption of these methods, i.e., the click probability is the product of examination probability and relevance probability, is oversimplified and insufficient to model the rich interaction between position and other information. In this paper, we propose a Deep Position-wise Interaction Network (DPIN) to efficiently combine all candidate items and positions for estimating CTR at each position, achieving consistency between offline and online as well as modeling the deep non-linear interaction among position, user, context and item under the limit of serving performance. Following our new treatment to the position bias in CTR prediction, we propose a new evaluation metrics named PAUC (position-wise AUC) that is suitable for measuring the ranking quality at a given position. Through extensive experiments on a real world dataset, we show empirically that our method is both effective and efficient in solving position bias problem. We have also deployed our method in production and observed statistically significant improvement over a highly optimized baseline in a rigorous A/B test.
JSRT: James-Stein Regression Tree
Oct 21, 2020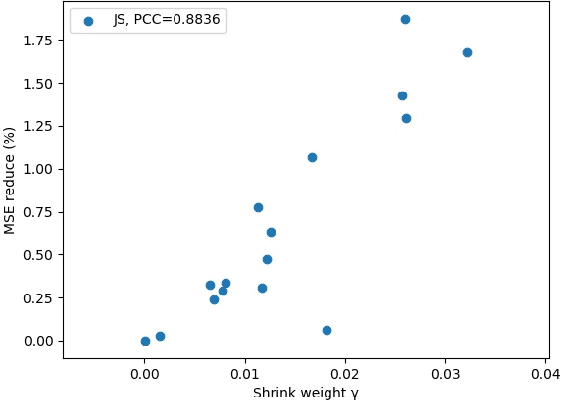
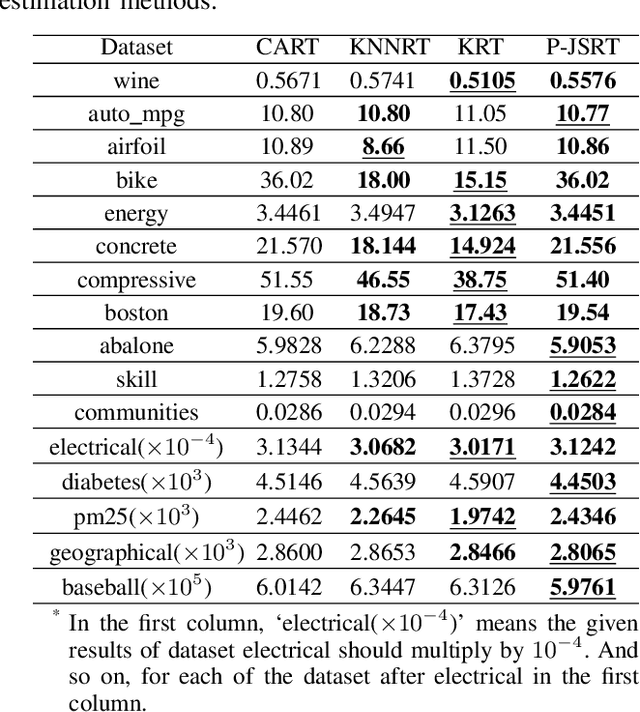
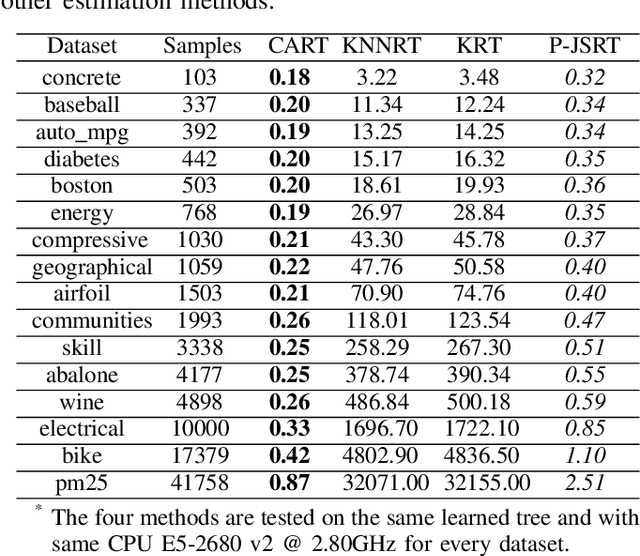
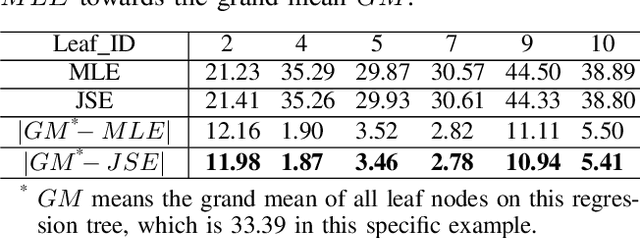
Regression tree (RT) has been widely used in machine learning and data mining community. Given a target data for prediction, a regression tree is first constructed based on a training dataset before making prediction for each leaf node. In practice, the performance of RT relies heavily on the local mean of samples from an individual node during the tree construction/prediction stage, while neglecting the global information from different nodes, which also plays an important role. To address this issue, we propose a novel regression tree, named James-Stein Regression Tree (JSRT) by considering global information from different nodes. Specifically, we incorporate the global mean information based on James-Stein estimator from different nodes during the construction/predicton stage. Besides, we analyze the generalization error of our method under the mean square error (MSE) metric. Extensive experiments on public benchmark datasets verify the effectiveness and efficiency of our method, and demonstrate the superiority of our method over other RT prediction methods.
$t$-$k$-means: A $k$-means Variant with Robustness and Stability
Jul 17, 2019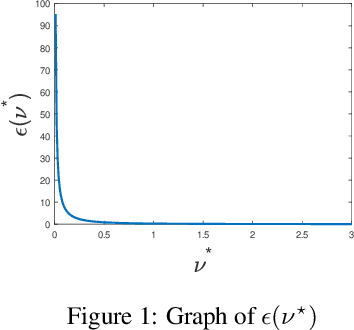
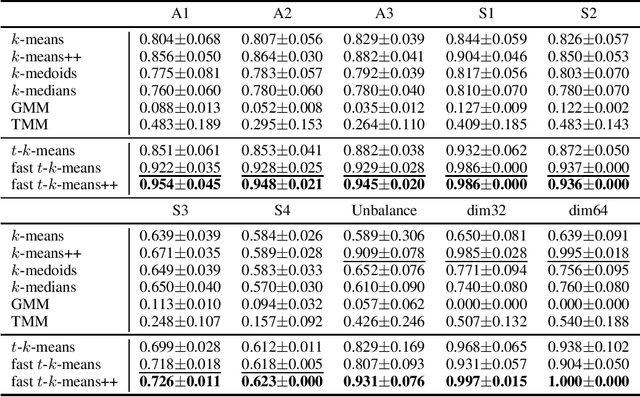
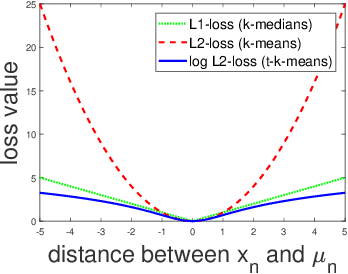
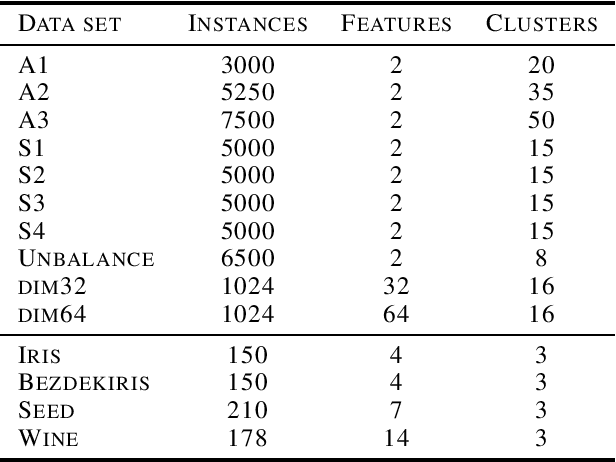
Lloyd's $k$-means algorithm is one of the most classical clustering method, which is widely used in data mining or as a data pre-processing procedure. However, due to the thin-tailed property of the Gaussian distribution, $k$-means suffers from relatively poor performance on the heavy-tailed data or outliers. In addition, $k$-means have a relatively weak stability, $i.e.$ its result has a large variance, which reduces the credibility of the model. In this paper, we propose a robust and stable $k$-means variant, the $t$-$k$-means, as well as its fast version in solving the flat clustering problem. Theoretically, we detail the derivations of $t$-$k$-means and analyze its robustness and stability from the aspect of loss function, influence function and the expression of clustering center. A large number of experiments are conducted, which empirically demonstrates that our method has empirical soundness while preserving running efficiency.
Multinomial Random Forests: Fill the Gap between Theoretical Consistency and Empirical Soundness
Mar 10, 2019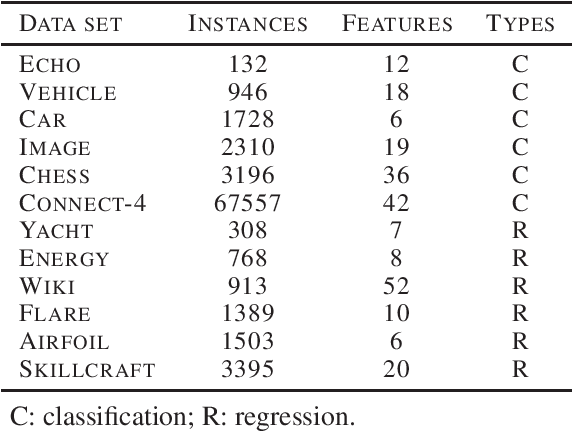
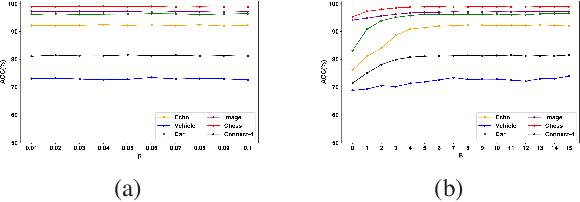

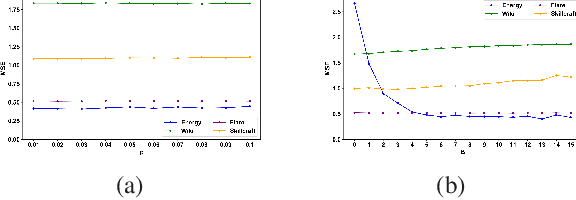
Random forests (RF) are one of the most widely used ensemble learning methods in classification and regression tasks. Despite its impressive performance, its theoretical consistency, which would ensure that its result converges to the optimum as the sample size increases, has been left far behind. Several consistent random forest variants have been proposed, yet all with relatively poor performance compared to the original random forests. In this paper, a novel RF framework named multinomial random forests (MRF) is proposed. In the MRF, an impurity-based multinomial distribution is constructed as the basis for the selection of a splitting point. This ensures that a certain degree of randomness is achieved while the overall quality of the trees is not much different from the original random forests. We prove the consistency of the MRF and demonstrate with multiple datasets that it performs similarly as the original random forests and better than existent consistent random forest variants for both classification and regression tasks.
Learning from Noisy Web Data with Category-level Supervision
May 24, 2018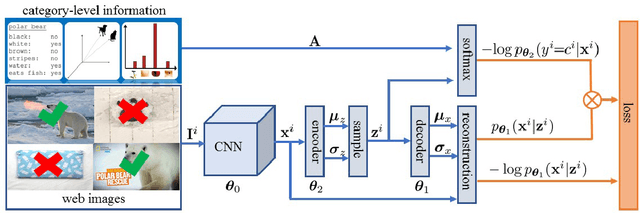
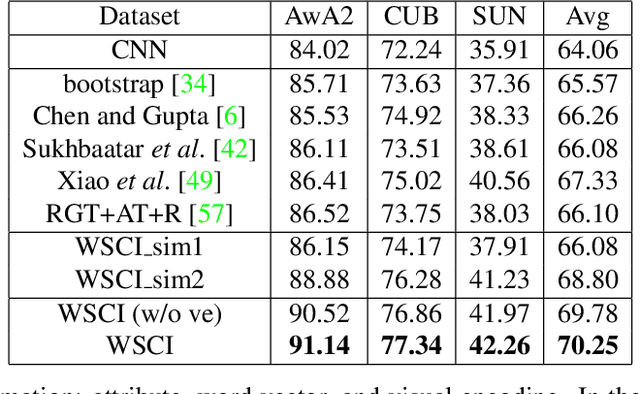

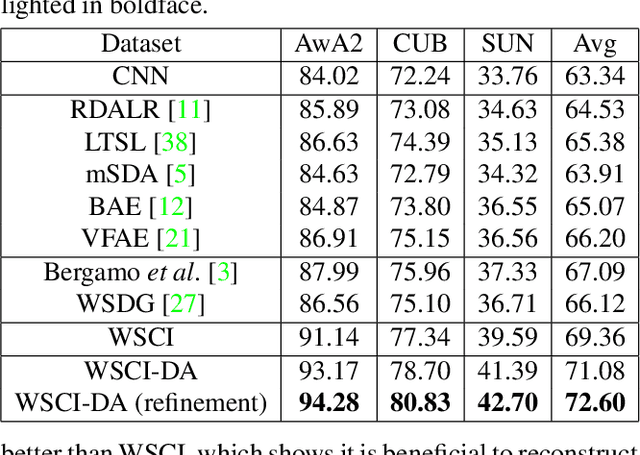
As tons of photos are being uploaded to public websites (e.g., Flickr, Bing, and Google) every day, learning from web data has become an increasingly popular research direction because of freely available web resources, which is also referred to as webly supervised learning. Nevertheless, the performance gap between webly supervised learning and traditional supervised learning is still very large, owning to the label noise of web data. To be exact, the labels of images crawled from public websites are very noisy and often inaccurate. Some existing works tend to facilitate learning from web data with the aid of extra information, such as augmenting or purifying web data by virtue of instance-level supervision, which is usually in demand of heavy manual annotation. Instead, we propose to tackle the label noise by leveraging more accessible category-level supervision. In particular, we build our method upon variational autoencoder (VAE), in which the classification network is attached on the hidden layer of VAE in a way that the classification network and VAE can jointly leverage the category-level hybrid semantic information. The effectiveness of our proposed method is clearly demonstrated by extensive experiments on three benchmark datasets.