 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Classification using Heterogeneous Web Data and Auxiliary Categories
Nov 19, 2018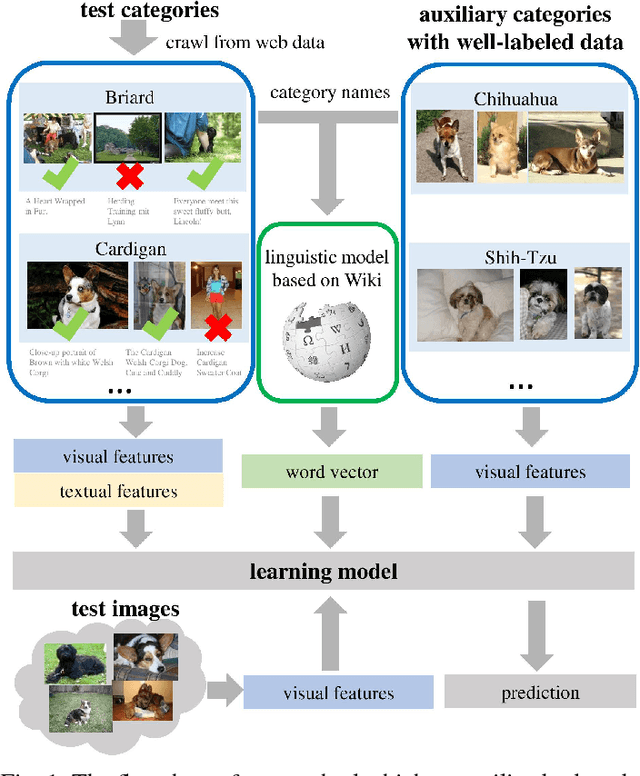

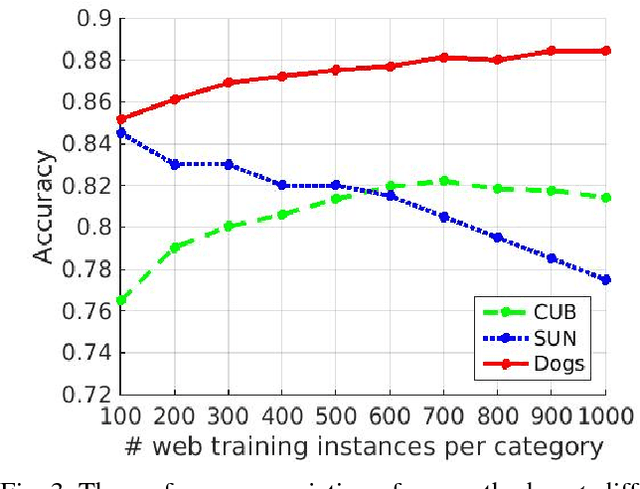

Fine-grained classification remains a very challenging problem, because of the absence of well-labeled training data caused by the high cost of annotating a large number of fine-grained categories. In the extreme case, given a set of test categories without any well-labeled training data, the majority of existing works can be grouped into the following two research directions: 1) crawl noisy labeled web data for the test categories as training data, which is dubbed as webly supervised learning; 2) transfer the knowledge from auxiliary categories with well-labeled training data to the test categories, which corresponds to zero-shot learning setting. Nevertheless, the above two research directions still have critical issues to be addressed. For the first direction, web data have noisy labels and considerably different data distribution from test data. For the second direction, zero-shot learning is struggling to achieve compelling results compared with conventional supervised learning. The issues of the above two directions motivate us to develop a novel approach which can jointly exploit both noisy web training data from test categories and well-labeled training data from auxiliary categories. In particular, on one hand, we crawl web data for test categories as noisy training data. On the other hand, we transfer the knowledge from auxiliary categories with well-labeled training data to test categories by virtue of free semantic information (e.g., word vector) of all categories. Moreover, given the fact that web data are generally associated with additional textual information (e.g., title and tag), we extend our method by using the surrounding textual information of web data as privileged information. Extensive experiments show the effectiveness of our proposed methods.
Learning from Noisy Web Data with Category-level Supervision
May 24, 2018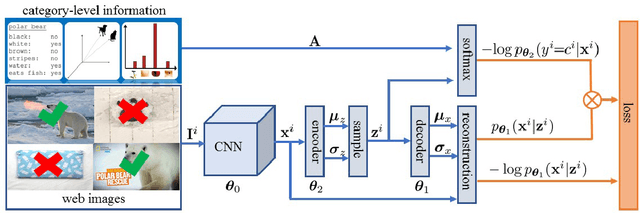
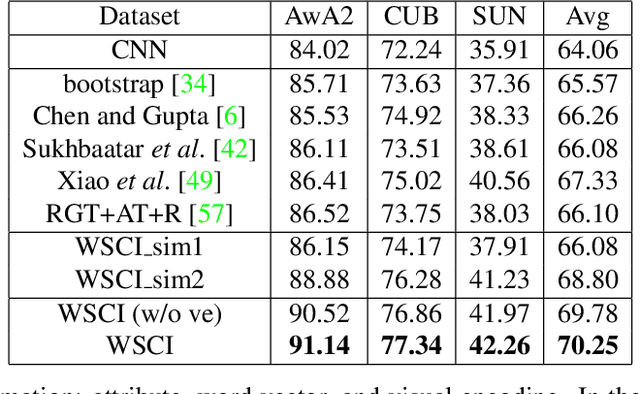

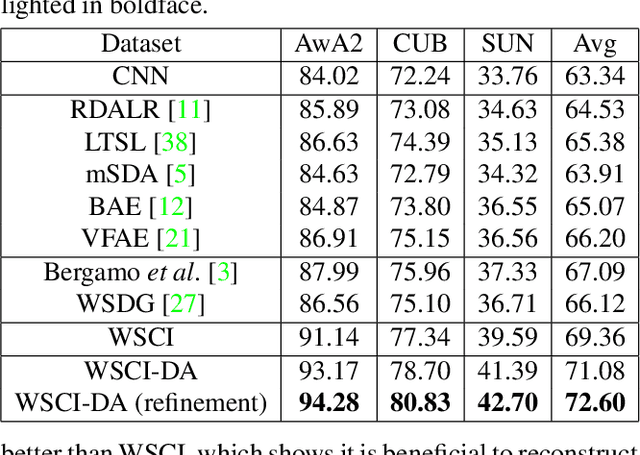
As tons of photos are being uploaded to public websites (e.g., Flickr, Bing, and Google) every day, learning from web data has become an increasingly popular research direction because of freely available web resources, which is also referred to as webly supervised learning. Nevertheless, the performance gap between webly supervised learning and traditional supervised learning is still very large, owning to the label noise of web data. To be exact, the labels of images crawled from public websites are very noisy and often inaccurate. Some existing works tend to facilitate learning from web data with the aid of extra information, such as augmenting or purifying web data by virtue of instance-level supervision, which is usually in demand of heavy manual annotation. Instead, we propose to tackle the label noise by leveraging more accessible category-level supervision. In particular, we build our method upon variational autoencoder (VAE), in which the classification network is attached on the hidden layer of VAE in a way that the classification network and VAE can jointly leverage the category-level hybrid semantic information. The effectiveness of our proposed method is clearly demonstrated by extensive experiments on three benchmark datasets.