 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModern Methods in Associative Memory
Jul 08, 2025Associative Memories like the famous Hopfield Networks are elegant models for describing fully recurrent neural networks whose fundamental job is to store and retrieve information. In the past few years they experienced a surge of interest due to novel theoretical results pertaining to their information storage capabilities, and their relationship with SOTA AI architectures, such as Transformers and Diffusion Models. These connections open up possibilities for interpreting the computation of traditional AI networks through the theoretical lens of Associative Memories. Additionally, novel Lagrangian formulations of these networks make it possible to design powerful distributed models that learn useful representations and inform the design of novel architectures. This tutorial provides an approachable introduction to Associative Memories, emphasizing the modern language and methods used in this area of research, with practical hands-on mathematical derivations and coding notebooks.
Memorization to Generalization: Emergence of Diffusion Models from Associative Memory
May 27, 2025



Hopfield networks are associative memory (AM) systems, designed for storing and retrieving patterns as local minima of an energy landscape. In the classical Hopfield model, an interesting phenomenon occurs when the amount of training data reaches its critical memory load $- spurious\,\,states$, or unintended stable points, emerge at the end of the retrieval dynamics, leading to incorrect recall. In this work, we examine diffusion models, commonly used in generative modeling, from the perspective of AMs. The training phase of diffusion model is conceptualized as memory encoding (training data is stored in the memory). The generation phase is viewed as an attempt of memory retrieval. In the small data regime the diffusion model exhibits a strong memorization phase, where the network creates distinct basins of attraction around each sample in the training set, akin to the Hopfield model below the critical memory load. In the large data regime, a different phase appears where an increase in the size of the training set fosters the creation of new attractor states that correspond to manifolds of the generated samples. Spurious states appear at the boundary of this transition and correspond to emergent attractor states, which are absent in the training set, but, at the same time, have distinct basins of attraction around them. Our findings provide: a novel perspective on the memorization-generalization phenomenon in diffusion models via the lens of AMs, theoretical prediction of existence of spurious states, empirical validation of this prediction in commonly-used diffusion models.
Losing dimensions: Geometric memorization in generative diffusion
Oct 11, 2024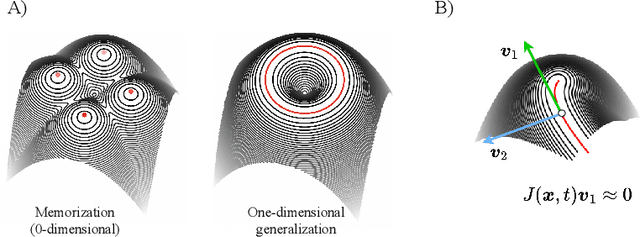

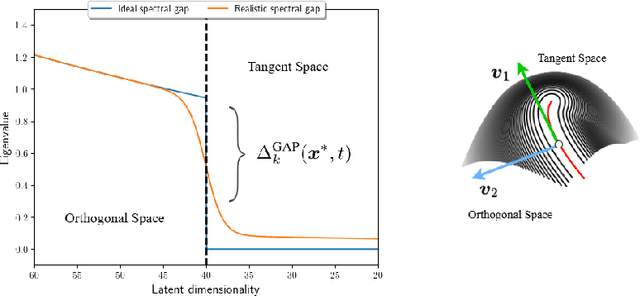
Generative diffusion processes are state-of-the-art machine learning models deeply connected with fundamental concepts in statistical physics. Depending on the dataset size and the capacity of the network, their behavior is known to transition from an associative memory regime to a generalization phase in a phenomenon that has been described as a glassy phase transition. Here, using statistical physics techniques, we extend the theory of memorization in generative diffusion to manifold-supported data. Our theoretical and experimental findings indicate that different tangent subspaces are lost due to memorization effects at different critical times and dataset sizes, which depend on the local variance of the data along their directions. Perhaps counterintuitively, we find that, under some conditions, subspaces of higher variance are lost first due to memorization effects. This leads to a selective loss of dimensionality where some prominent features of the data are memorized without a full collapse on any individual training point. We validate our theory with a comprehensive set of experiments on networks trained both in image datasets and on linear manifolds, which result in a remarkable qualitative agreement with the theoretical predictions.
Energy Transformer
Feb 14, 2023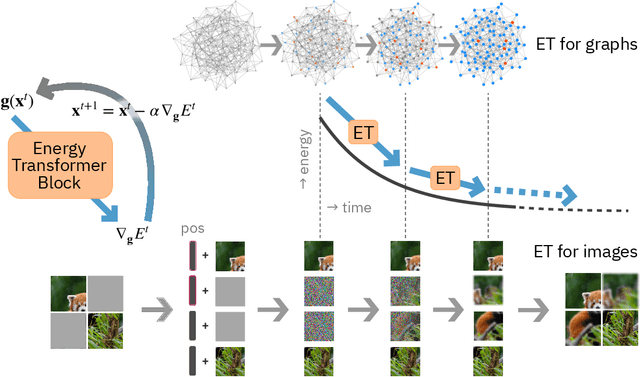
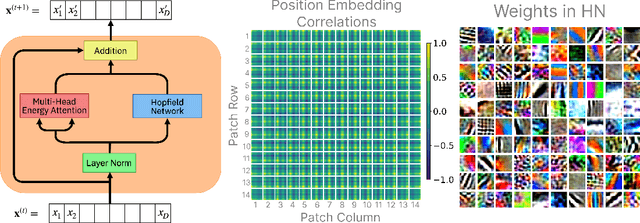

Transformers have become the de facto models of choice in machine learning, typically leading to impressive performance on many applications. At the same time, the architectural development in the transformer world is mostly driven by empirical findings, and the theoretical understanding of their architectural building blocks is rather limited. In contrast, Dense Associative Memory models or Modern Hopfield Networks have a well-established theoretical foundation, but have not yet demonstrated truly impressive practical results. We propose a transformer architecture that replaces the sequence of feedforward transformer blocks with a single large Associative Memory model. Our novel architecture, called Energy Transformer (or ET for short), has many of the familiar architectural primitives that are often used in the current generation of transformers. However, it is not identical to the existing architectures. The sequence of transformer layers in ET is purposely designed to minimize a specifically engineered energy function, which is responsible for representing the relationships between the tokens. As a consequence of this computational principle, the attention in ET is different from the conventional attention mechanism. In this work, we introduce the theoretical foundations of ET, explore it's empirical capabilities using the image completion task, and obtain strong quantitative results on the graph anomaly detection task.