 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Semantic Information Production in Generative Diffusion Models
Jun 12, 2025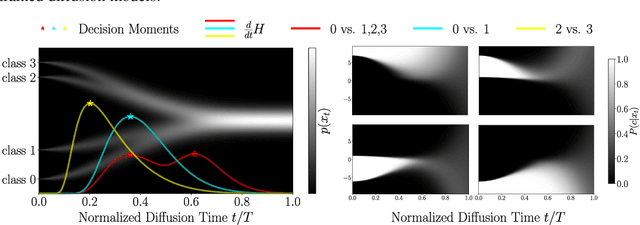


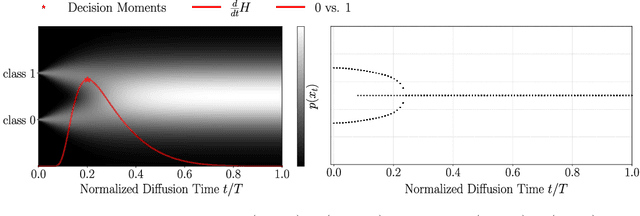
It is well known that semantic and structural features of the generated images emerge at different times during the reverse dynamics of diffusion, a phenomenon that has been connected to physical phase transitions in magnets and other materials. In this paper, we introduce a general information-theoretic approach to measure when these class-semantic "decisions" are made during the generative process. By using an online formula for the optimal Bayesian classifier, we estimate the conditional entropy of the class label given the noisy state. We then determine the time intervals corresponding to the highest information transfer between noisy states and class labels using the time derivative of the conditional entropy. We demonstrate our method on one-dimensional Gaussian mixture models and on DDPM models trained on the CIFAR10 dataset. As expected, we find that the semantic information transfer is highest in the intermediate stages of diffusion while vanishing during the final stages. However, we found sizable differences between the entropy rate profiles of different classes, suggesting that different "semantic decisions" are located at different intermediate times.
Memorization to Generalization: Emergence of Diffusion Models from Associative Memory
May 27, 2025



Hopfield networks are associative memory (AM) systems, designed for storing and retrieving patterns as local minima of an energy landscape. In the classical Hopfield model, an interesting phenomenon occurs when the amount of training data reaches its critical memory load $- spurious\,\,states$, or unintended stable points, emerge at the end of the retrieval dynamics, leading to incorrect recall. In this work, we examine diffusion models, commonly used in generative modeling, from the perspective of AMs. The training phase of diffusion model is conceptualized as memory encoding (training data is stored in the memory). The generation phase is viewed as an attempt of memory retrieval. In the small data regime the diffusion model exhibits a strong memorization phase, where the network creates distinct basins of attraction around each sample in the training set, akin to the Hopfield model below the critical memory load. In the large data regime, a different phase appears where an increase in the size of the training set fosters the creation of new attractor states that correspond to manifolds of the generated samples. Spurious states appear at the boundary of this transition and correspond to emergent attractor states, which are absent in the training set, but, at the same time, have distinct basins of attraction around them. Our findings provide: a novel perspective on the memorization-generalization phenomenon in diffusion models via the lens of AMs, theoretical prediction of existence of spurious states, empirical validation of this prediction in commonly-used diffusion models.
Dynamic Negative Guidance of Diffusion Models
Oct 18, 2024



Negative Prompting (NP) is widely utilized in diffusion models, particularly in text-to-image applications, to prevent the generation of undesired features. In this paper, we show that conventional NP is limited by the assumption of a constant guidance scale, which may lead to highly suboptimal results, or even complete failure, due to the non-stationarity and state-dependence of the reverse process. Based on this analysis, we derive a principled technique called Dynamic Negative Guidance, which relies on a near-optimal time and state dependent modulation of the guidance without requiring additional training. Unlike NP, negative guidance requires estimating the posterior class probability during the denoising process, which is achieved with limited additional computational overhead by tracking the discrete Markov Chain during the generative process. We evaluate the performance of DNG class-removal on MNIST and CIFAR10, where we show that DNG leads to higher safety, preservation of class balance and image quality when compared with baseline methods. Furthermore, we show that it is possible to use DNG with Stable Diffusion to obtain more accurate and less invasive guidance than NP.
Losing dimensions: Geometric memorization in generative diffusion
Oct 11, 2024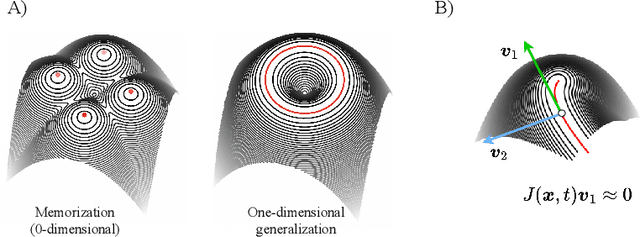

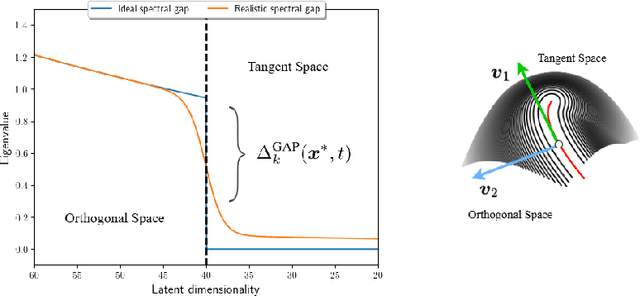
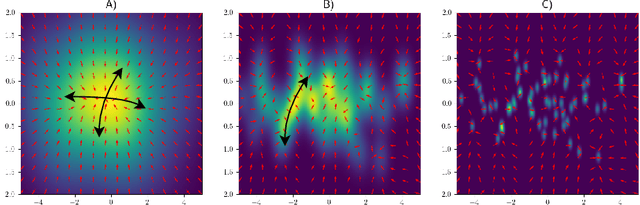
Generative diffusion processes are state-of-the-art machine learning models deeply connected with fundamental concepts in statistical physics. Depending on the dataset size and the capacity of the network, their behavior is known to transition from an associative memory regime to a generalization phase in a phenomenon that has been described as a glassy phase transition. Here, using statistical physics techniques, we extend the theory of memorization in generative diffusion to manifold-supported data. Our theoretical and experimental findings indicate that different tangent subspaces are lost due to memorization effects at different critical times and dataset sizes, which depend on the local variance of the data along their directions. Perhaps counterintuitively, we find that, under some conditions, subspaces of higher variance are lost first due to memorization effects. This leads to a selective loss of dimensionality where some prominent features of the data are memorized without a full collapse on any individual training point. We validate our theory with a comprehensive set of experiments on networks trained both in image datasets and on linear manifolds, which result in a remarkable qualitative agreement with the theoretical predictions.
Spontaneous symmetry breaking in generative diffusion models
Jun 01, 2023Generative diffusion models have recently emerged as a leading approach for generating high-dimensional data. In this paper, we show that the dynamics of these models exhibit a spontaneous symmetry breaking that divides the generative dynamics into two distinct phases: 1) A linear steady-state dynamics around a central fixed-point and 2) an attractor dynamics directed towards the data manifold. These two "phases" are separated by the change in stability of the central fixed-point, with the resulting window of instability being responsible for the diversity of the generated samples. Using both theoretical and empirical evidence, we show that an accurate simulation of the early dynamics does not significantly contribute to the final generation, since early fluctuations are reverted to the central fixed point. To leverage this insight, we propose a Gaussian late initialization scheme, which significantly improves model performance, achieving up to 3x FID improvements on fast samplers, while also increasing sample diversity (e.g., racial composition of generated CelebA images). Our work offers a new way to understand the generative dynamics of diffusion models that has the potential to bring about higher performance and less biased fast-samplers.