 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStar-Agents: Automatic Data Optimization with LLM Agents for Instruction Tuning
Nov 21, 2024
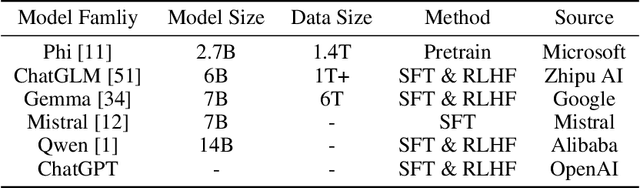

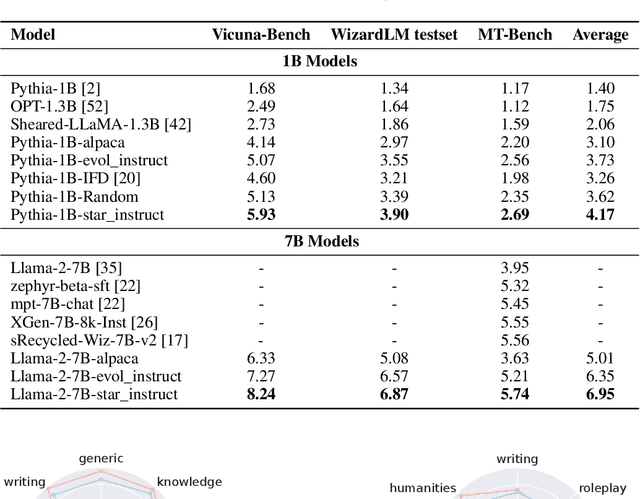
The efficacy of large language models (LLMs) on downstream tasks usually hinges on instruction tuning, which relies critically on the quality of training data. Unfortunately, collecting high-quality and diverse data is both expensive and time-consuming. To mitigate this issue, we propose a novel Star-Agents framework, which automates the enhancement of data quality across datasets through multi-agent collaboration and assessment. The framework adopts a three-pronged strategy. It initially generates diverse instruction data with multiple LLM agents through a bespoke sampling method. Subsequently, the generated data undergo a rigorous evaluation using a dual-model method that assesses both difficulty and quality. Finaly, the above process evolves in a dynamic refinement phase, where more effective LLMs are prioritized, enhancing the overall data quality. Our empirical studies, including instruction tuning experiments with models such as Pythia and LLaMA, demonstrate the effectiveness of the proposed framework. Optimized datasets have achieved substantial improvements, with an average increase of 12% and notable gains in specific metrics, such as a 40% improvement in Fermi, as evidenced by benchmarks like MT-bench, Vicuna bench, and WizardLM testset.
MemoryFormer: Minimize Transformer Computation by Removing Fully-Connected Layers
Nov 20, 2024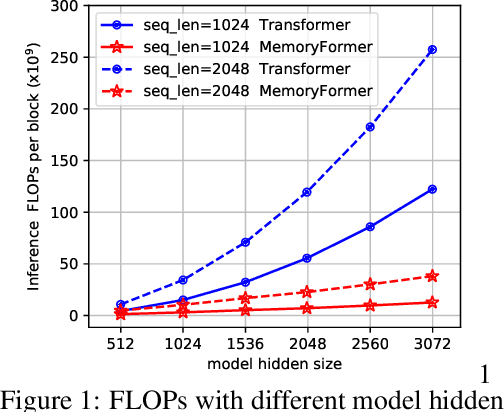
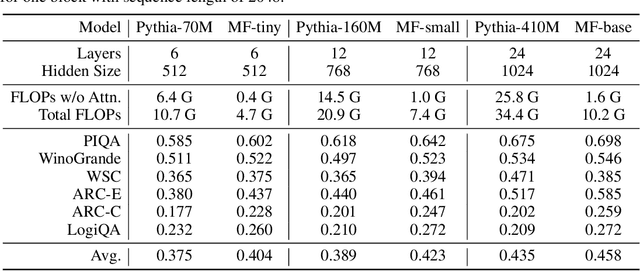
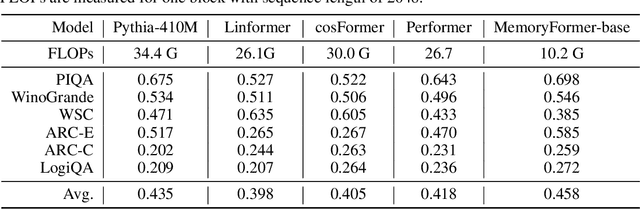
In order to reduce the computational complexity of large language models, great efforts have been made to to improve the efficiency of transformer models such as linear attention and flash-attention. However, the model size and corresponding computational complexity are constantly scaled up in pursuit of higher performance. In this work, we present MemoryFormer, a novel transformer architecture which significantly reduces the computational complexity (FLOPs) from a new perspective. We eliminate nearly all the computations of the transformer model except for the necessary computation required by the multi-head attention operation. This is made possible by utilizing an alternative method for feature transformation to replace the linear projection of fully-connected layers. Specifically, we first construct a group of in-memory lookup tables that store a large amount of discrete vectors to replace the weight matrix used in linear projection. We then use a hash algorithm to retrieve a correlated subset of vectors dynamically based on the input embedding. The retrieved vectors combined together will form the output embedding, which provides an estimation of the result of matrix multiplication operation in a fully-connected layer. Compared to conducting matrix multiplication, retrieving data blocks from memory is a much cheaper operation which requires little computations. We train MemoryFormer from scratch and conduct extensive experiments on various benchmarks to demonstrate the effectiveness of the proposed model.
A robust audio deepfake detection system via multi-view feature
Mar 04, 2024


With the advancement of generative modeling techniques, synthetic human speech becomes increasingly indistinguishable from real, and tricky challenges are elicited for the audio deepfake detection (ADD) system. In this paper, we exploit audio features to improve the generalizability of ADD systems. Investigation of the ADD task performance is conducted over a broad range of audio features, including various handcrafted features and learning-based features. Experiments show that learning-based audio features pretrained on a large amount of data generalize better than hand-crafted features on out-of-domain scenarios. Subsequently, we further improve the generalizability of the ADD system using proposed multi-feature approaches to incorporate complimentary information from features of different views. The model trained on ASV2019 data achieves an equal error rate of 24.27\% on the In-the-Wild dataset.