 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoryFormer: Minimize Transformer Computation by Removing Fully-Connected Layers
Nov 20, 2024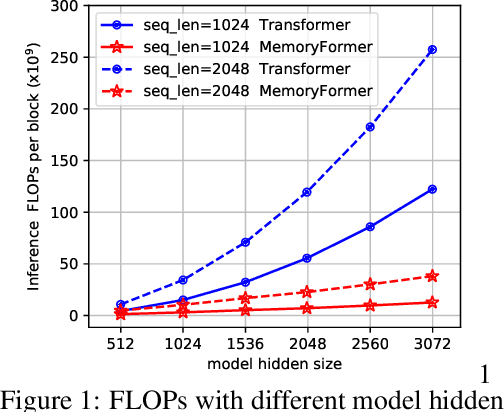
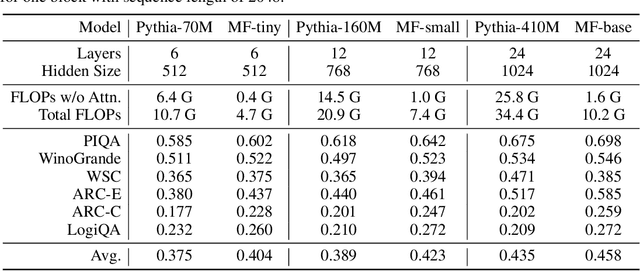
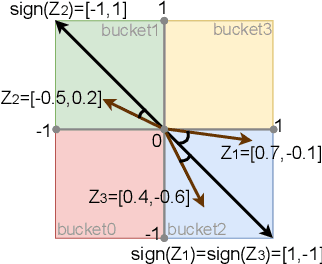
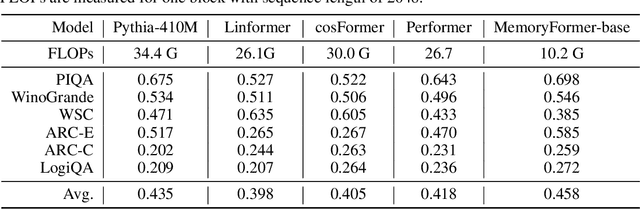
In order to reduce the computational complexity of large language models, great efforts have been made to to improve the efficiency of transformer models such as linear attention and flash-attention. However, the model size and corresponding computational complexity are constantly scaled up in pursuit of higher performance. In this work, we present MemoryFormer, a novel transformer architecture which significantly reduces the computational complexity (FLOPs) from a new perspective. We eliminate nearly all the computations of the transformer model except for the necessary computation required by the multi-head attention operation. This is made possible by utilizing an alternative method for feature transformation to replace the linear projection of fully-connected layers. Specifically, we first construct a group of in-memory lookup tables that store a large amount of discrete vectors to replace the weight matrix used in linear projection. We then use a hash algorithm to retrieve a correlated subset of vectors dynamically based on the input embedding. The retrieved vectors combined together will form the output embedding, which provides an estimation of the result of matrix multiplication operation in a fully-connected layer. Compared to conducting matrix multiplication, retrieving data blocks from memory is a much cheaper operation which requires little computations. We train MemoryFormer from scratch and conduct extensive experiments on various benchmarks to demonstrate the effectiveness of the proposed model.