 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiFloat4 Format for Language Model Inference
Feb 13, 2026This paper introduces HiFloat4 (HiF4), a block floating-point data format tailored for deep learning. Each HiF4 unit packs 64 4-bit elements with 32 bits of shared scaling metadata, averaging 4.5 bits per value. The metadata specifies a three-level scaling hierarchy, capturing inter- and intra-group dynamic range while improving the utilization of the representational space. In addition, the large 64-element group size enables matrix multiplications to be executed in a highly fixed-point manner, significantly reducing hardware area and power consumption. To evaluate the proposed format, we conducted inference experiments on several language models, including LLaMA, Qwen, Mistral, DeepSeek-V3.1 and LongCat. Results show that HiF4 achieves higher average accuracy than the state-of-the-art NVFP4 format across multiple models and diverse downstream tasks.
BAPS: A Fine-Grained Low-Precision Scheme for Softmax in Attention via Block-Aware Precision reScaling
Feb 02, 2026As the performance gains from accelerating quantized matrix multiplication plateau, the softmax operation becomes the critical bottleneck in Transformer inference. This bottleneck stems from two hardware limitations: (1) limited data bandwidth between matrix and vector compute cores, and (2) the significant area cost of high-precision (FP32/16) exponentiation units (EXP2). To address these issues, we introduce a novel low-precision workflow that employs a specific 8-bit floating-point format (HiF8) and block-aware precision rescaling for softmax. Crucially, our algorithmic innovations make low-precision softmax feasible without the significant model accuracy loss that hampers direct low-precision approaches. Specifically, our design (i) halves the required data movement bandwidth by enabling matrix multiplication outputs constrained to 8-bit, and (ii) substantially reduces the EXP2 unit area by computing exponentiations in low (8-bit) precision. Extensive evaluation on language models and multi-modal models confirms the validity of our method. By alleviating the vector computation bottleneck, our work paves the way for doubling end-to-end inference throughput without increasing chip area, and offers a concrete co-design path for future low-precision hardware and software.
Serving Large Language Models on Huawei CloudMatrix384
Jun 15, 2025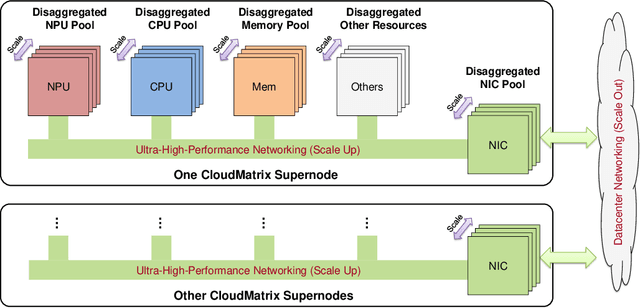
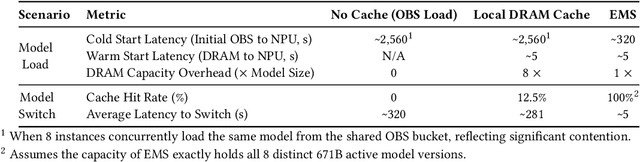
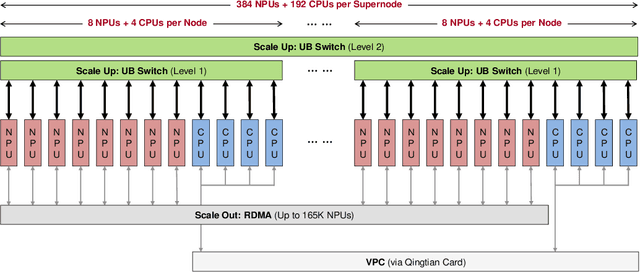
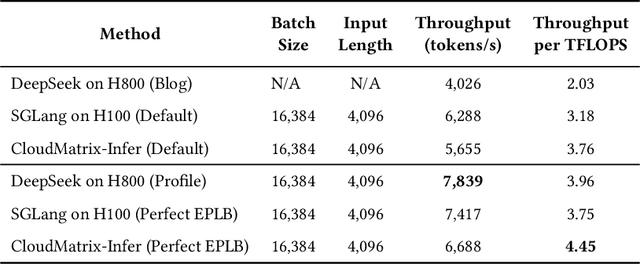
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
MemoryFormer: Minimize Transformer Computation by Removing Fully-Connected Layers
Nov 20, 2024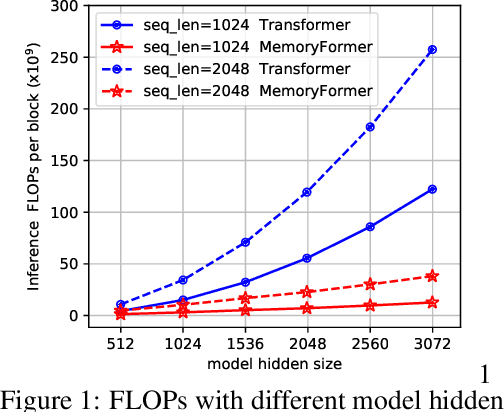
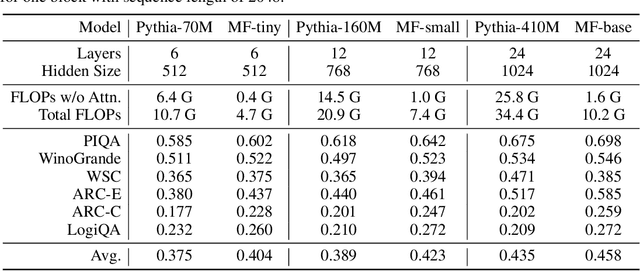
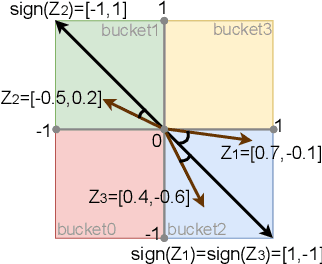
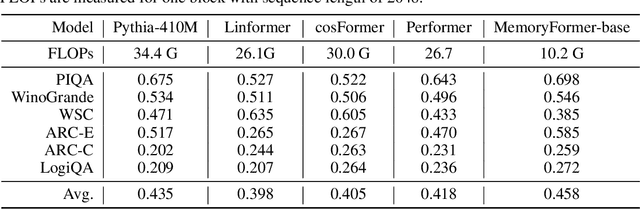
In order to reduce the computational complexity of large language models, great efforts have been made to to improve the efficiency of transformer models such as linear attention and flash-attention. However, the model size and corresponding computational complexity are constantly scaled up in pursuit of higher performance. In this work, we present MemoryFormer, a novel transformer architecture which significantly reduces the computational complexity (FLOPs) from a new perspective. We eliminate nearly all the computations of the transformer model except for the necessary computation required by the multi-head attention operation. This is made possible by utilizing an alternative method for feature transformation to replace the linear projection of fully-connected layers. Specifically, we first construct a group of in-memory lookup tables that store a large amount of discrete vectors to replace the weight matrix used in linear projection. We then use a hash algorithm to retrieve a correlated subset of vectors dynamically based on the input embedding. The retrieved vectors combined together will form the output embedding, which provides an estimation of the result of matrix multiplication operation in a fully-connected layer. Compared to conducting matrix multiplication, retrieving data blocks from memory is a much cheaper operation which requires little computations. We train MemoryFormer from scratch and conduct extensive experiments on various benchmarks to demonstrate the effectiveness of the proposed model.
LEGO-Prover: Neural Theorem Proving with Growing Libraries
Oct 12, 2023



Despite the success of large language models (LLMs), the task of theorem proving still remains one of the hardest reasoning tasks that is far from being fully solved. Prior methods using language models have demonstrated promising results, but they still struggle to prove even middle school level theorems. One common limitation of these methods is that they assume a fixed theorem library during the whole theorem proving process. However, as we all know, creating new useful theorems or even new theories is not only helpful but crucial and necessary for advancing mathematics and proving harder and deeper results. In this work, we present LEGO-Prover, which employs a growing skill library containing verified lemmas as skills to augment the capability of LLMs used in theorem proving. By constructing the proof modularly, LEGO-Prover enables LLMs to utilize existing skills retrieved from the library and to create new skills during the proving process. These skills are further evolved (by prompting an LLM) to enrich the library on another scale. Modular and reusable skills are constantly added to the library to enable tackling increasingly intricate mathematical problems. Moreover, the learned library further bridges the gap between human proofs and formal proofs by making it easier to impute missing steps. LEGO-Prover advances the state-of-the-art pass rate on miniF2F-valid (48.0% to 57.0%) and miniF2F-test (45.5% to 47.1%). During the proving process, LEGO-Prover also manages to generate over 20,000 skills (theorems/lemmas) and adds them to the growing library. Our ablation study indicates that these newly added skills are indeed helpful for proving theorems, resulting in an improvement from a success rate of 47.1% to 50.4%. We also release our code and all the generated skills.