 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightMoE: Reducing Mixture-of-Experts Redundancy through Expert Replacing
Mar 13, 2026Mixture-of-Experts (MoE) based Large Language Models (LLMs) have demonstrated impressive performance and computational efficiency. However, their deployment is often constrained by substantial memory demands, primarily due to the need to load numerous expert modules. While existing expert compression techniques like pruning or merging attempt to mitigate this, they often suffer from irreversible knowledge loss or high training overhead. In this paper, we propose a novel expert compression paradigm termed expert replacing, which replaces redundant experts with parameter-efficient modules and recovers their capabilities with low training costs. We find that even a straightforward baseline of this paradigm yields promising performance. Building on this foundation, we introduce LightMoE, a framework that enhances the paradigm by introducing adaptive expert selection, hierarchical expert construction, and an annealed recovery strategy. Experimental results show that LightMoE matches the performance of LoRA fine-tuning at a 30% compression ratio. Even under a more aggressive 50% compression rate, it outperforms existing methods and achieves average performance improvements of 5.6% across five diverse tasks. These findings demonstrate that LightMoE strikes a superior balance among memory efficiency, training efficiency, and model performance.
Streaming-dLLM: Accelerating Diffusion LLMs via Suffix Pruning and Dynamic Decoding
Jan 27, 2026Diffusion Large Language Models (dLLMs) offer a compelling paradigm for natural language generation, leveraging parallel decoding and bidirectional attention to achieve superior global coherence compared to autoregressive models. While recent works have accelerated inference via KV cache reuse or heuristic decoding, they overlook the intrinsic inefficiencies within the block-wise diffusion process. Specifically, they suffer from spatial redundancy by modeling informative-sparse suffix regions uniformly and temporal inefficiency by applying fixed denoising schedules across all the decoding process. To address this, we propose Streaming-dLLM, a training-free framework that streamlines inference across both spatial and temporal dimensions. Spatially, we introduce attenuation guided suffix modeling to approximate the full context by pruning redundant mask tokens. Temporally, we employ a dynamic confidence aware strategy with an early exit mechanism, allowing the model to skip unnecessary iterations for converged tokens. Extensive experiments show that Streaming-dLLM achieves up to 68.2X speedup while maintaining generation quality, highlighting its effectiveness in diffusion decoding. The code is available at https://github.com/xiaoshideta/Streaming-dLLM.
Low-Precision Training of Large Language Models: Methods, Challenges, and Opportunities
May 02, 2025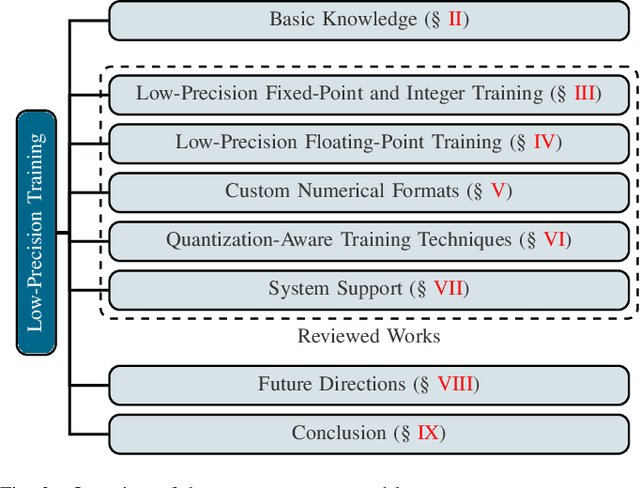
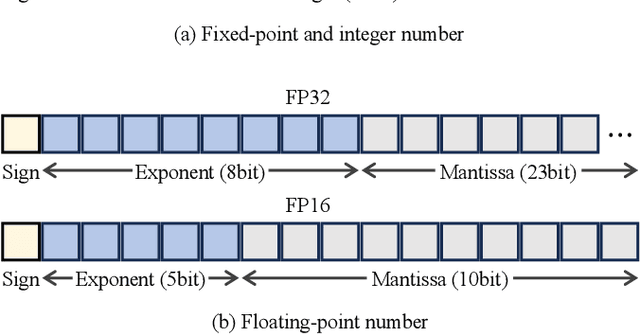
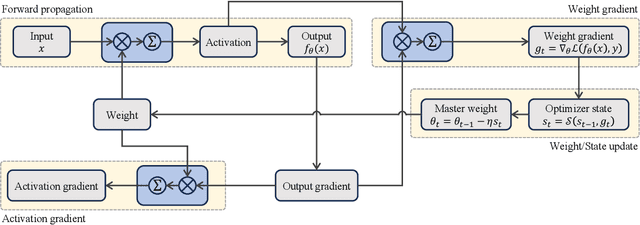
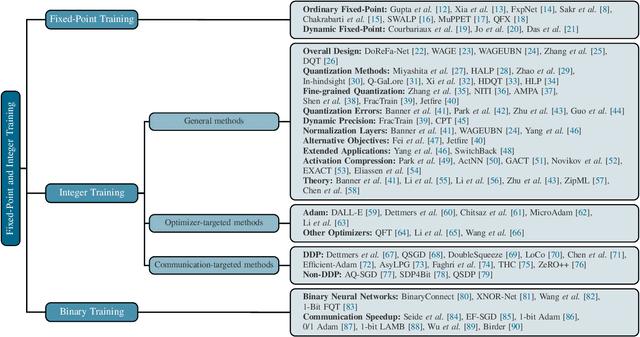
Large language models (LLMs) have achieved impressive performance across various domains. However, the substantial hardware resources required for their training present a significant barrier to efficiency and scalability. To mitigate this challenge, low-precision training techniques have been widely adopted, leading to notable advancements in training efficiency. Despite these gains, low-precision training involves several components$\unicode{x2013}$such as weights, activations, and gradients$\unicode{x2013}$each of which can be represented in different numerical formats. The resulting diversity has created a fragmented landscape in low-precision training research, making it difficult for researchers to gain a unified overview of the field. This survey provides a comprehensive review of existing low-precision training methods. To systematically organize these approaches, we categorize them into three primary groups based on their underlying numerical formats, which is a key factor influencing hardware compatibility, computational efficiency, and ease of reference for readers. The categories are: (1) fixed-point and integer-based methods, (2) floating-point-based methods, and (3) customized format-based methods. Additionally, we discuss quantization-aware training approaches, which share key similarities with low-precision training during forward propagation. Finally, we highlight several promising research directions to advance this field. A collection of papers discussed in this survey is provided in https://github.com/Hao840/Awesome-Low-Precision-Training.
ADEM-VL: Adaptive and Embedded Fusion for Efficient Vision-Language Tuning
Oct 23, 2024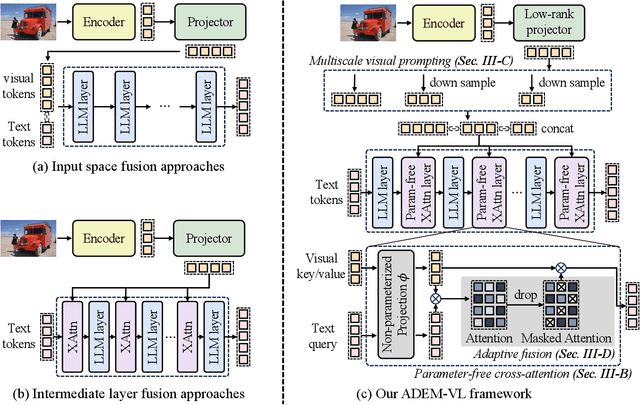


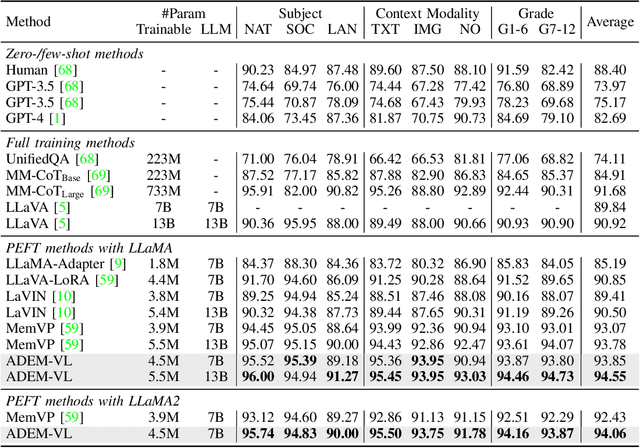
Recent advancements in multimodal fusion have witnessed the remarkable success of vision-language (VL) models, which excel in various multimodal applications such as image captioning and visual question answering. However, building VL models requires substantial hardware resources, where efficiency is restricted by two key factors: the extended input sequence of the language model with vision features demands more computational operations, and a large number of additional learnable parameters increase memory complexity. These challenges significantly restrict the broader applicability of such models. To bridge this gap, we propose ADEM-VL, an efficient vision-language method that tunes VL models based on pretrained large language models (LLMs) by adopting a parameter-free cross-attention mechanism for similarity measurements in multimodal fusion. This approach only requires embedding vision features into the language space, significantly reducing the number of trainable parameters and accelerating both training and inference speeds. To enhance representation learning in fusion module, we introduce an efficient multiscale feature generation scheme that requires only a single forward pass through the vision encoder. Moreover, we propose an adaptive fusion scheme that dynamically discards less relevant visual information for each text token based on its attention score. This ensures that the fusion process prioritizes the most pertinent visual features. With experiments on various tasks including visual question answering, image captioning, and instruction-following, we demonstrate that our framework outperforms existing approaches. Specifically, our method surpasses existing methods by an average accuracy of 0.77% on ScienceQA dataset, with reduced training and inference latency, demonstrating the superiority of our framework. The code is available at https://github.com/Hao840/ADEM-VL.
GhostNetV3: Exploring the Training Strategies for Compact Models
Apr 17, 2024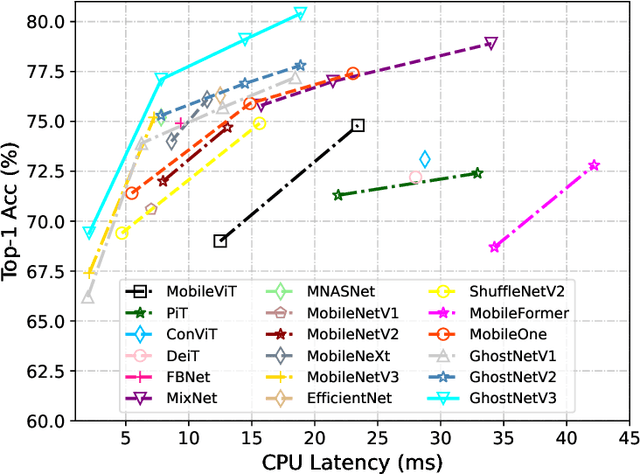

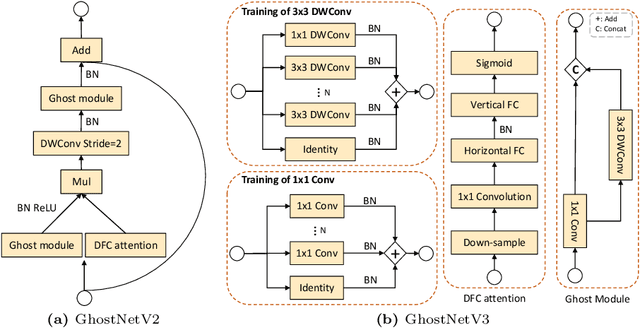
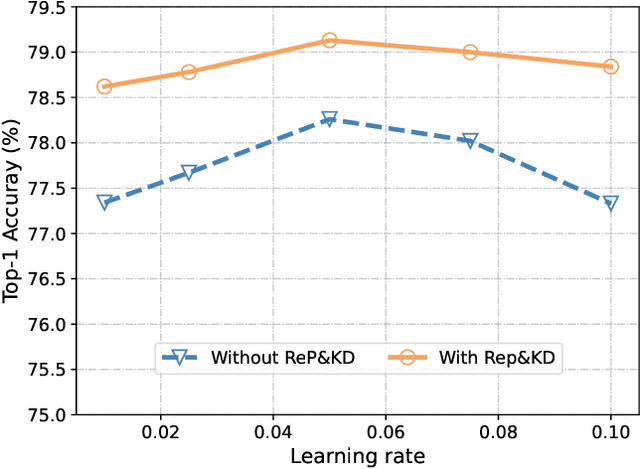
Compact neural networks are specially designed for applications on edge devices with faster inference speed yet modest performance. However, training strategies of compact models are borrowed from that of conventional models at present, which ignores their difference in model capacity and thus may impede the performance of compact models. In this paper, by systematically investigating the impact of different training ingredients, we introduce a strong training strategy for compact models. We find that the appropriate designs of re-parameterization and knowledge distillation are crucial for training high-performance compact models, while some commonly used data augmentations for training conventional models, such as Mixup and CutMix, lead to worse performance. Our experiments on ImageNet-1K dataset demonstrate that our specialized training strategy for compact models is applicable to various architectures, including GhostNetV2, MobileNetV2 and ShuffleNetV2. Specifically, equipped with our strategy, GhostNetV3 1.3$\times$ achieves a top-1 accuracy of 79.1% with only 269M FLOPs and a latency of 14.46ms on mobile devices, surpassing its ordinarily trained counterpart by a large margin. Moreover, our observation can also be extended to object detection scenarios. PyTorch code and checkpoints can be found at https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/ghostnetv3_pytorch.
SAM-DiffSR: Structure-Modulated Diffusion Model for Image Super-Resolution
Feb 27, 2024Diffusion-based super-resolution (SR) models have recently garnered significant attention due to their potent restoration capabilities. But conventional diffusion models perform noise sampling from a single distribution, constraining their ability to handle real-world scenes and complex textures across semantic regions. With the success of segment anything model (SAM), generating sufficiently fine-grained region masks can enhance the detail recovery of diffusion-based SR model. However, directly integrating SAM into SR models will result in much higher computational cost. In this paper, we propose the SAM-DiffSR model, which can utilize the fine-grained structure information from SAM in the process of sampling noise to improve the image quality without additional computational cost during inference. In the process of training, we encode structural position information into the segmentation mask from SAM. Then the encoded mask is integrated into the forward diffusion process by modulating it to the sampled noise. This adjustment allows us to independently adapt the noise mean within each corresponding segmentation area. The diffusion model is trained to estimate this modulated noise. Crucially, our proposed framework does NOT change the reverse diffusion process and does NOT require SAM at inference. Experimental results demonstrate the effectiveness of our proposed method, showcasing superior performance in suppressing artifacts, and surpassing existing diffusion-based methods by 0.74 dB at the maximum in terms of PSNR on DIV2K dataset. The code and dataset are available at https://github.com/lose4578/SAM-DiffSR.
Data-efficient Large Vision Models through Sequential Autoregression
Feb 07, 2024



Training general-purpose vision models on purely sequential visual data, eschewing linguistic inputs, has heralded a new frontier in visual understanding. These models are intended to not only comprehend but also seamlessly transit to out-of-domain tasks. However, current endeavors are hamstrung by an over-reliance on colossal models, exemplified by models with upwards of 3B parameters, and the necessity for an extensive corpus of visual data, often comprising a staggering 400B tokens. In this paper, we delve into the development of an efficient, autoregression-based vision model, innovatively architected to operate on a limited dataset. We meticulously demonstrate how this model achieves proficiency in a spectrum of visual tasks spanning both high-level and low-level semantic understanding during the testing phase. Our empirical evaluations underscore the model's agility in adapting to various tasks, heralding a significant reduction in the parameter footprint, and a marked decrease in training data requirements, thereby paving the way for more sustainable and accessible advancements in the field of generalist vision models. The code is available at https://github.com/ggjy/DeLVM.
One-for-All: Bridge the Gap Between Heterogeneous Architectures in Knowledge Distillation
Oct 30, 2023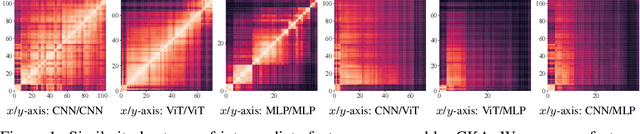
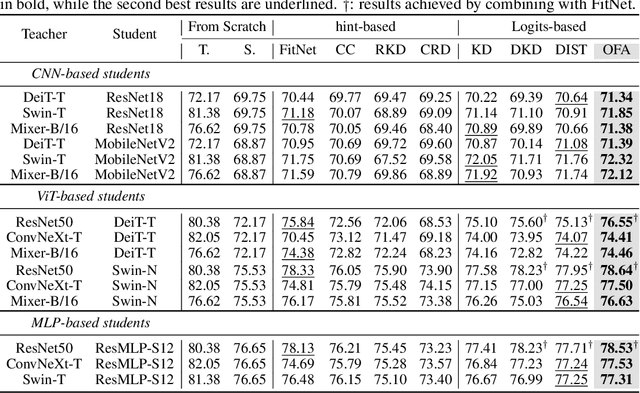
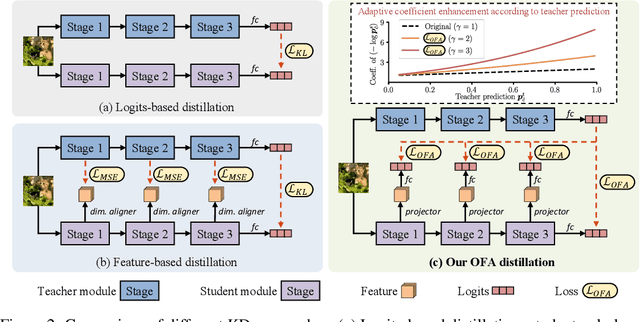
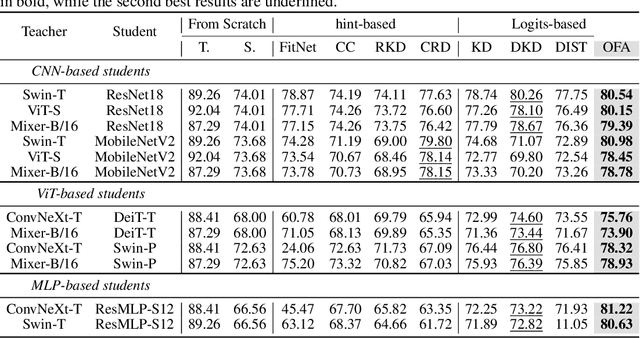
Knowledge distillation~(KD) has proven to be a highly effective approach for enhancing model performance through a teacher-student training scheme. However, most existing distillation methods are designed under the assumption that the teacher and student models belong to the same model family, particularly the hint-based approaches. By using centered kernel alignment (CKA) to compare the learned features between heterogeneous teacher and student models, we observe significant feature divergence. This divergence illustrates the ineffectiveness of previous hint-based methods in cross-architecture distillation. To tackle the challenge in distilling heterogeneous models, we propose a simple yet effective one-for-all KD framework called OFA-KD, which significantly improves the distillation performance between heterogeneous architectures. Specifically, we project intermediate features into an aligned latent space such as the logits space, where architecture-specific information is discarded. Additionally, we introduce an adaptive target enhancement scheme to prevent the student from being disturbed by irrelevant information. Extensive experiments with various architectures, including CNN, Transformer, and MLP, demonstrate the superiority of our OFA-KD framework in enabling distillation between heterogeneous architectures. Specifically, when equipped with our OFA-KD, the student models achieve notable performance improvements, with a maximum gain of 8.0% on the CIFAR-100 dataset and 0.7% on the ImageNet-1K dataset. PyTorch code and checkpoints can be found at https://github.com/Hao840/OFAKD.
DeViT: Decomposing Vision Transformers for Collaborative Inference in Edge Devices
Sep 10, 2023



Recent years have witnessed the great success of vision transformer (ViT), which has achieved state-of-the-art performance on multiple computer vision benchmarks. However, ViT models suffer from vast amounts of parameters and high computation cost, leading to difficult deployment on resource-constrained edge devices. Existing solutions mostly compress ViT models to a compact model but still cannot achieve real-time inference. To tackle this issue, we propose to explore the divisibility of transformer structure, and decompose the large ViT into multiple small models for collaborative inference at edge devices. Our objective is to achieve fast and energy-efficient collaborative inference while maintaining comparable accuracy compared with large ViTs. To this end, we first propose a collaborative inference framework termed DeViT to facilitate edge deployment by decomposing large ViTs. Subsequently, we design a decomposition-and-ensemble algorithm based on knowledge distillation, termed DEKD, to fuse multiple small decomposed models while dramatically reducing communication overheads, and handle heterogeneous models by developing a feature matching module to promote the imitations of decomposed models from the large ViT. Extensive experiments for three representative ViT backbones on four widely-used datasets demonstrate our method achieves efficient collaborative inference for ViTs and outperforms existing lightweight ViTs, striking a good trade-off between efficiency and accuracy. For example, our DeViTs improves end-to-end latency by 2.89$\times$ with only 1.65% accuracy sacrifice using CIFAR-100 compared to the large ViT, ViT-L/16, on the GPU server. DeDeiTs surpasses the recent efficient ViT, MobileViT-S, by 3.54% in accuracy on ImageNet-1K, while running 1.72$\times$ faster and requiring 55.28% lower energy consumption on the edge device.
VanillaKD: Revisit the Power of Vanilla Knowledge Distillation from Small Scale to Large Scale
May 25, 2023



The tremendous success of large models trained on extensive datasets demonstrates that scale is a key ingredient in achieving superior results. Therefore, the reflection on the rationality of designing knowledge distillation (KD) approaches for limited-capacity architectures solely based on small-scale datasets is now deemed imperative. In this paper, we identify the \emph{small data pitfall} that presents in previous KD methods, which results in the underestimation of the power of vanilla KD framework on large-scale datasets such as ImageNet-1K. Specifically, we show that employing stronger data augmentation techniques and using larger datasets can directly decrease the gap between vanilla KD and other meticulously designed KD variants. This highlights the necessity of designing and evaluating KD approaches in the context of practical scenarios, casting off the limitations of small-scale datasets. Our investigation of the vanilla KD and its variants in more complex schemes, including stronger training strategies and different model capacities, demonstrates that vanilla KD is elegantly simple but astonishingly effective in large-scale scenarios. Without bells and whistles, we obtain state-of-the-art ResNet-50, ViT-S, and ConvNeXtV2-T models for ImageNet, which achieve 83.1\%, 84.3\%, and 85.0\% top-1 accuracy, respectively. PyTorch code and checkpoints can be found at https://github.com/Hao840/vanillaKD.