 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADEM-VL: Adaptive and Embedded Fusion for Efficient Vision-Language Tuning
Paper and Code
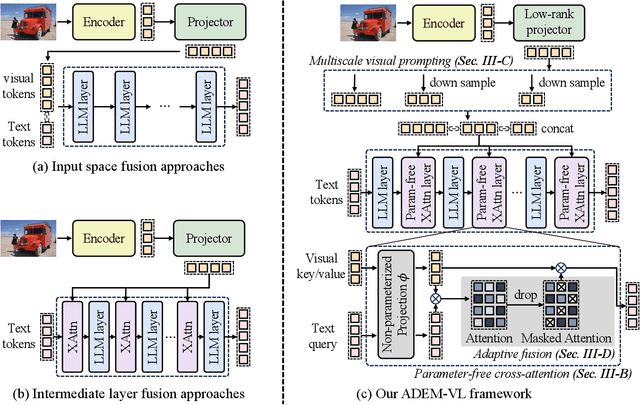


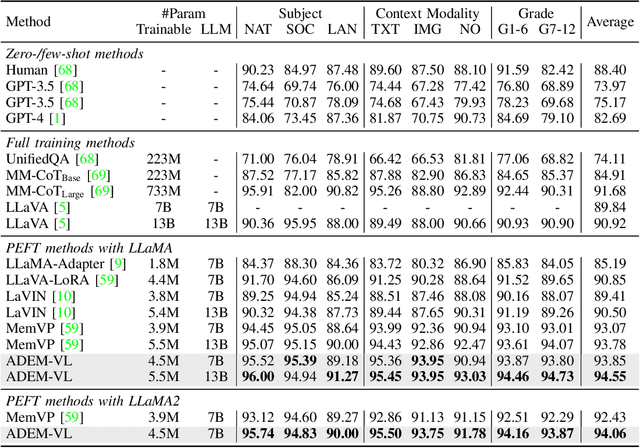
Recent advancements in multimodal fusion have witnessed the remarkable success of vision-language (VL) models, which excel in various multimodal applications such as image captioning and visual question answering. However, building VL models requires substantial hardware resources, where efficiency is restricted by two key factors: the extended input sequence of the language model with vision features demands more computational operations, and a large number of additional learnable parameters increase memory complexity. These challenges significantly restrict the broader applicability of such models. To bridge this gap, we propose ADEM-VL, an efficient vision-language method that tunes VL models based on pretrained large language models (LLMs) by adopting a parameter-free cross-attention mechanism for similarity measurements in multimodal fusion. This approach only requires embedding vision features into the language space, significantly reducing the number of trainable parameters and accelerating both training and inference speeds. To enhance representation learning in fusion module, we introduce an efficient multiscale feature generation scheme that requires only a single forward pass through the vision encoder. Moreover, we propose an adaptive fusion scheme that dynamically discards less relevant visual information for each text token based on its attention score. This ensures that the fusion process prioritizes the most pertinent visual features. With experiments on various tasks including visual question answering, image captioning, and instruction-following, we demonstrate that our framework outperforms existing approaches. Specifically, our method surpasses existing methods by an average accuracy of 0.77% on ScienceQA dataset, with reduced training and inference latency, demonstrating the superiority of our framework. The code is available at https://github.com/Hao840/ADEM-VL.