 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDFKD-MFS: Collaborative Data-free Knowledge Distillation via Multi-level Feature Sharing
Paper and Code
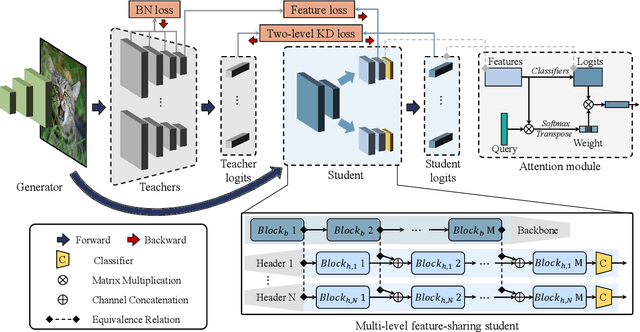


Recently, the compression and deployment of powerful deep neural networks (DNNs) on resource-limited edge devices to provide intelligent services have become attractive tasks. Although knowledge distillation (KD) is a feasible solution for compression, its requirement on the original dataset raises privacy concerns. In addition, it is common to integrate multiple pretrained models to achieve satisfactory performance. How to compress multiple models into a tiny model is challenging, especially when the original data are unavailable. To tackle this challenge, we propose a framework termed collaborative data-free knowledge distillation via multi-level feature sharing (CDFKD-MFS), which consists of a multi-header student module, an asymmetric adversarial data-free KD module, and an attention-based aggregation module. In this framework, the student model equipped with a multi-level feature-sharing structure learns from multiple teacher models and is trained together with a generator in an asymmetric adversarial manner. When some real samples are available, the attention module adaptively aggregates predictions of the student headers, which can further improve performance. We conduct extensive experiments on three popular computer visual datasets. In particular, compared with the most competitive alternative, the accuracy of the proposed framework is 1.18\% higher on the CIFAR-100 dataset, 1.67\% higher on the Caltech-101 dataset, and 2.99\% higher on the mini-ImageNet dataset.