 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly Deformable Proprioceptive Membrane for Real-Time 3D Shape Reconstruction
Jan 20, 2026Reconstructing the three-dimensional (3D) geometry of object surfaces is essential for robot perception, yet vision-based approaches are generally unreliable under low illumination or occlusion. This limitation motivates the design of a proprioceptive membrane that conforms to the surface of interest and infers 3D geometry by reconstructing its own deformation. Conventional shape-aware membranes typically rely on resistive, capacitive, or magneto-sensitive mechanisms. However, these methods often encounter challenges such as structural complexity, limited compliance during large-scale deformation, and susceptibility to electromagnetic interference. This work presents a soft, flexible, and stretchable proprioceptive silicone membrane based on optical waveguide sensing. The membrane sensor integrates edge-mounted LEDs and centrally distributed photodiodes (PDs), interconnected via liquid-metal traces embedded within a multilayer elastomeric composite. Rich deformation-dependent light intensity signals are decoded by a data-driven model to recover the membrane geometry as a 3D point cloud. On a customized 140 mm square membrane, real-time reconstruction of large-scale out-of-plane deformation is achieved at 90 Hz with an average reconstruction error of 1.3 mm, measured by Chamfer distance, while maintaining accuracy for indentations up to 25 mm. The proposed framework provides a scalable, robust, and low-profile solution for global shape perception in deformable robotic systems.
DeViT: Decomposing Vision Transformers for Collaborative Inference in Edge Devices
Sep 10, 2023



Recent years have witnessed the great success of vision transformer (ViT), which has achieved state-of-the-art performance on multiple computer vision benchmarks. However, ViT models suffer from vast amounts of parameters and high computation cost, leading to difficult deployment on resource-constrained edge devices. Existing solutions mostly compress ViT models to a compact model but still cannot achieve real-time inference. To tackle this issue, we propose to explore the divisibility of transformer structure, and decompose the large ViT into multiple small models for collaborative inference at edge devices. Our objective is to achieve fast and energy-efficient collaborative inference while maintaining comparable accuracy compared with large ViTs. To this end, we first propose a collaborative inference framework termed DeViT to facilitate edge deployment by decomposing large ViTs. Subsequently, we design a decomposition-and-ensemble algorithm based on knowledge distillation, termed DEKD, to fuse multiple small decomposed models while dramatically reducing communication overheads, and handle heterogeneous models by developing a feature matching module to promote the imitations of decomposed models from the large ViT. Extensive experiments for three representative ViT backbones on four widely-used datasets demonstrate our method achieves efficient collaborative inference for ViTs and outperforms existing lightweight ViTs, striking a good trade-off between efficiency and accuracy. For example, our DeViTs improves end-to-end latency by 2.89$\times$ with only 1.65% accuracy sacrifice using CIFAR-100 compared to the large ViT, ViT-L/16, on the GPU server. DeDeiTs surpasses the recent efficient ViT, MobileViT-S, by 3.54% in accuracy on ImageNet-1K, while running 1.72$\times$ faster and requiring 55.28% lower energy consumption on the edge device.
LGViT: Dynamic Early Exiting for Accelerating Vision Transformer
Aug 01, 2023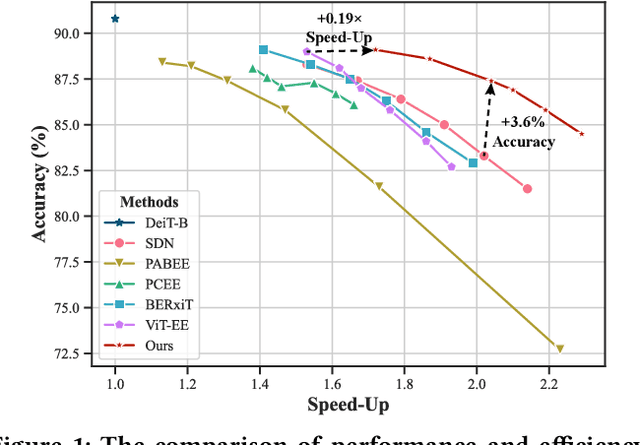
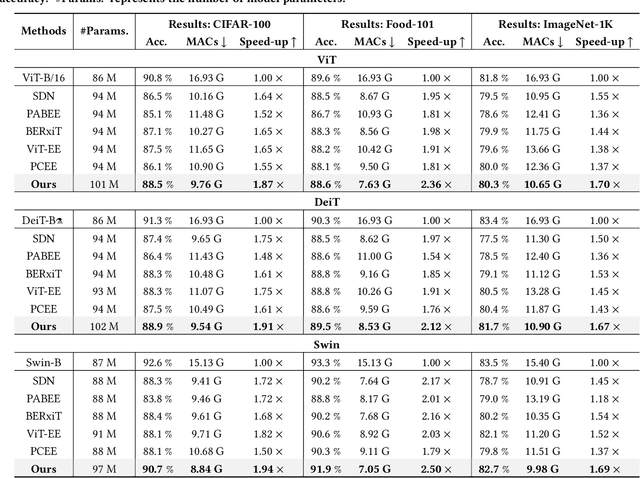
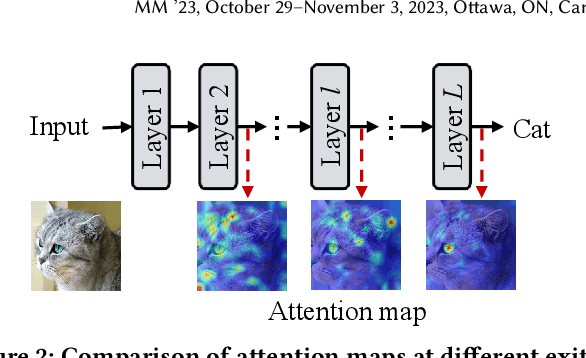

Recently, the efficient deployment and acceleration of powerful vision transformers (ViTs) on resource-limited edge devices for providing multimedia services have become attractive tasks. Although early exiting is a feasible solution for accelerating inference, most works focus on convolutional neural networks (CNNs) and transformer models in natural language processing (NLP).Moreover, the direct application of early exiting methods to ViTs may result in substantial performance degradation. To tackle this challenge, we systematically investigate the efficacy of early exiting in ViTs and point out that the insufficient feature representations in shallow internal classifiers and the limited ability to capture target semantic information in deep internal classifiers restrict the performance of these methods. We then propose an early exiting framework for general ViTs termed LGViT, which incorporates heterogeneous exiting heads, namely, local perception head and global aggregation head, to achieve an efficiency-accuracy trade-off. In particular, we develop a novel two-stage training scheme, including end-to-end training and self-distillation with the backbone frozen to generate early exiting ViTs, which facilitates the fusion of global and local information extracted by the two types of heads. We conduct extensive experiments using three popular ViT backbones on three vision datasets. Results demonstrate that our LGViT can achieve competitive performance with approximately 1.8 $\times$ speed-up.
Multi-Agent Collaborative Inference via DNN Decoupling: Intermediate Feature Compression and Edge Learning
May 24, 2022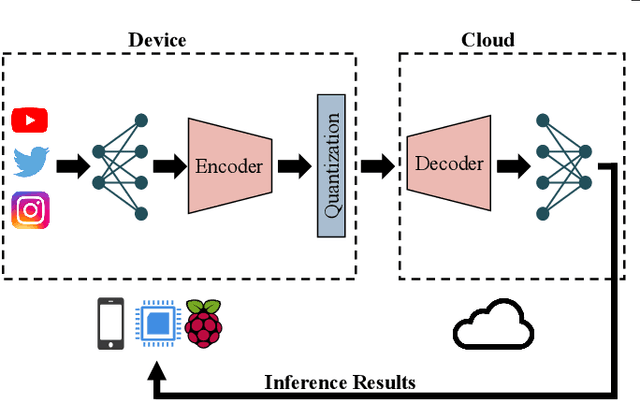

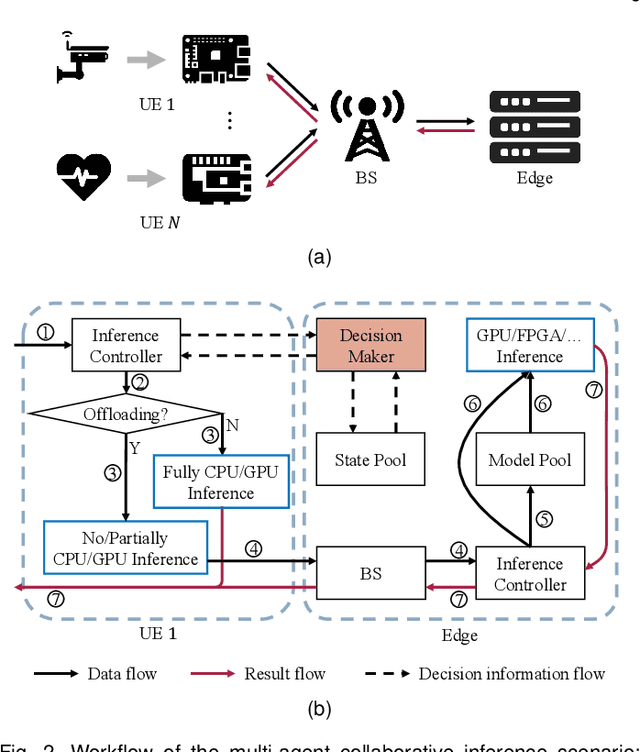
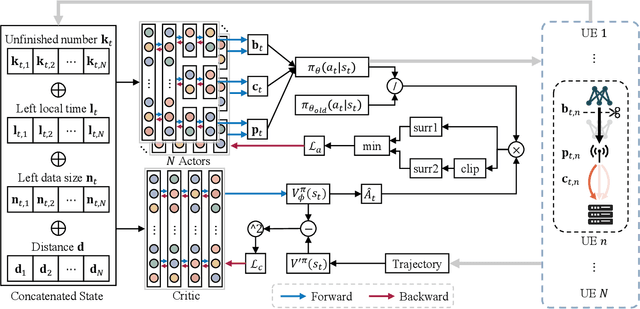
Recently, deploying deep neural network (DNN) models via collaborative inference, which splits a pre-trained model into two parts and executes them on user equipment (UE) and edge server respectively, becomes attractive. However, the large intermediate feature of DNN impedes flexible decoupling, and existing approaches either focus on the single UE scenario or simply define tasks considering the required CPU cycles, but ignore the indivisibility of a single DNN layer. In this paper, we study the multi-agent collaborative inference scenario, where a single edge server coordinates the inference of multiple UEs. Our goal is to achieve fast and energy-efficient inference for all UEs. To achieve this goal, we first design a lightweight autoencoder-based method to compress the large intermediate feature. Then we define tasks according to the inference overhead of DNNs and formulate the problem as a Markov decision process (MDP). Finally, we propose a multi-agent hybrid proximal policy optimization (MAHPPO) algorithm to solve the optimization problem with a hybrid action space. We conduct extensive experiments with different types of networks, and the results show that our method can reduce up to 56\% of inference latency and save up to 72\% of energy consumption.
DeepTracks: Geopositioning Maritime Vehicles in Video Acquired from a Moving Platform
Sep 02, 2021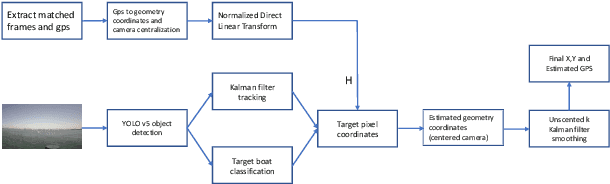
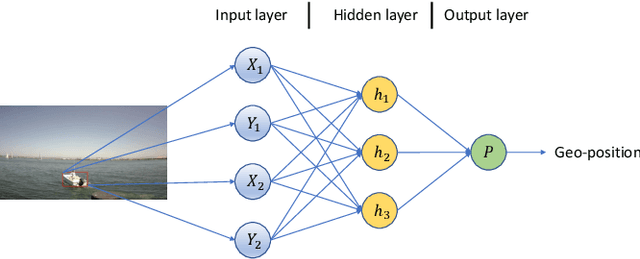
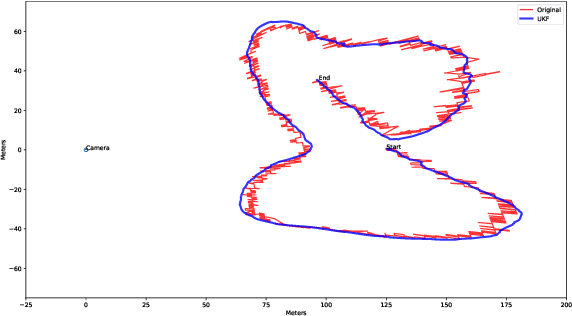
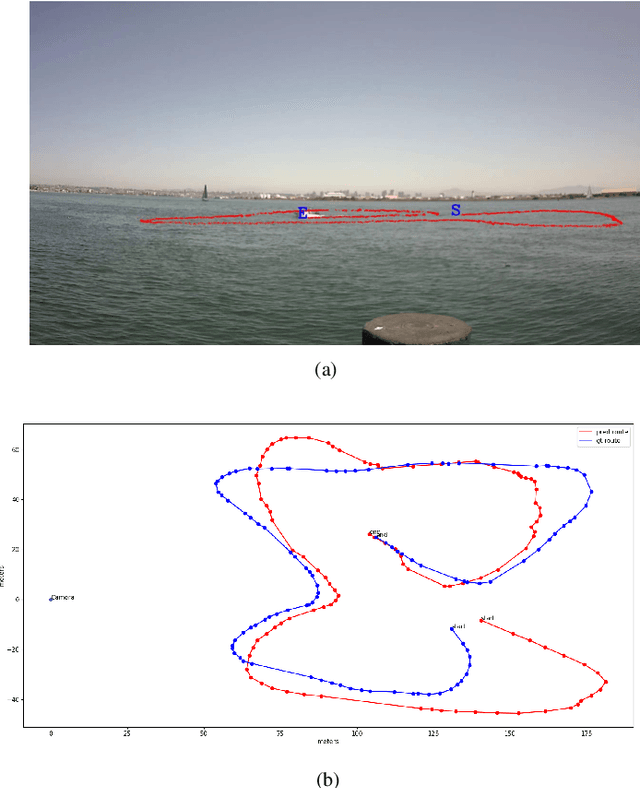
Geopositioning and tracking a moving boat at sea is a very challenging problem, requiring boat detection, matching and estimating its GPS location from imagery with no common features. The problem can be stated as follows: given imagery from a camera mounted on a moving platform with known GPS location as the only valid sensor, we predict the geoposition of a target boat visible in images. Our solution uses recent ML algorithms, the camera-scene geometry and Bayesian filtering. The proposed pipeline first detects and tracks the target boat's location in the image with the strategy of tracking by detection. This image location is then converted to geoposition to the local sea coordinates referenced to the camera GPS location using plane projective geometry. Finally, target boat local coordinates are transformed to global GPS coordinates to estimate the geoposition. To achieve a smooth geotrajectory, we apply unscented Kalman filter (UKF) which implicitly overcomes small detection errors in the early stages of the pipeline. We tested the performance of our approach using GPS ground truth and show the accuracy and speed of the estimated geopositions. Our code is publicly available at https://github.com/JianliWei1995/AI-Track-at-Sea.