 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLGViT: Dynamic Early Exiting for Accelerating Vision Transformer
Paper and Code
Aug 01, 2023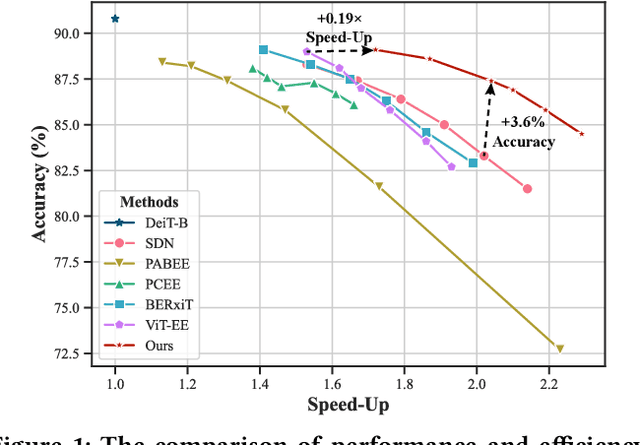
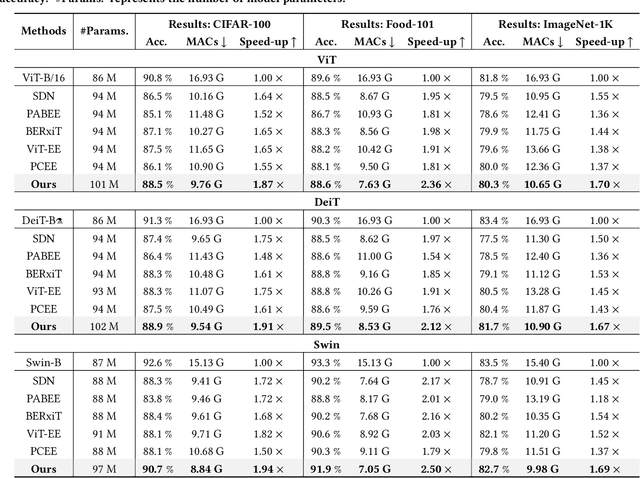
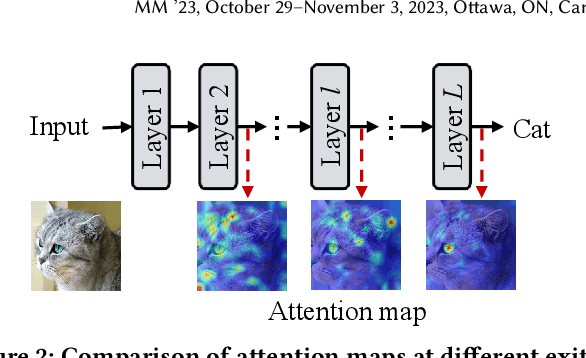

Recently, the efficient deployment and acceleration of powerful vision transformers (ViTs) on resource-limited edge devices for providing multimedia services have become attractive tasks. Although early exiting is a feasible solution for accelerating inference, most works focus on convolutional neural networks (CNNs) and transformer models in natural language processing (NLP).Moreover, the direct application of early exiting methods to ViTs may result in substantial performance degradation. To tackle this challenge, we systematically investigate the efficacy of early exiting in ViTs and point out that the insufficient feature representations in shallow internal classifiers and the limited ability to capture target semantic information in deep internal classifiers restrict the performance of these methods. We then propose an early exiting framework for general ViTs termed LGViT, which incorporates heterogeneous exiting heads, namely, local perception head and global aggregation head, to achieve an efficiency-accuracy trade-off. In particular, we develop a novel two-stage training scheme, including end-to-end training and self-distillation with the backbone frozen to generate early exiting ViTs, which facilitates the fusion of global and local information extracted by the two types of heads. We conduct extensive experiments using three popular ViT backbones on three vision datasets. Results demonstrate that our LGViT can achieve competitive performance with approximately 1.8 $\times$ speed-up.