 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnshackling Context Length: An Efficient Selective Attention Approach through Query-Key Compression
Paper and Code
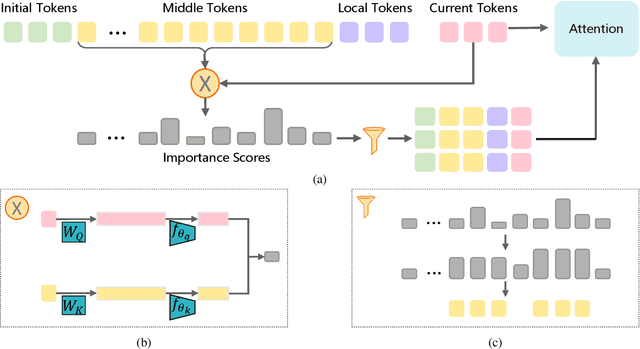
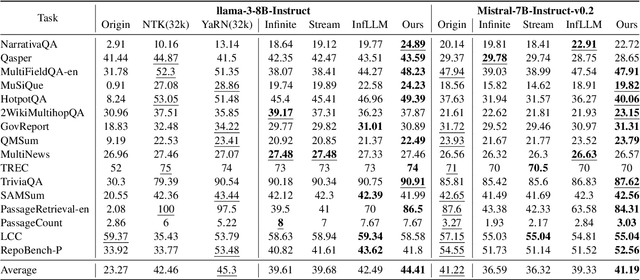
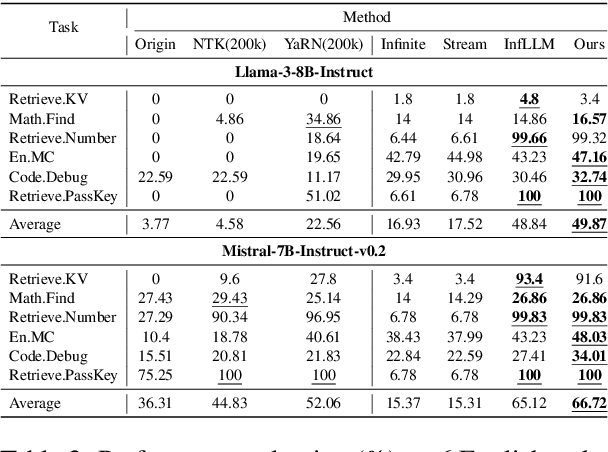
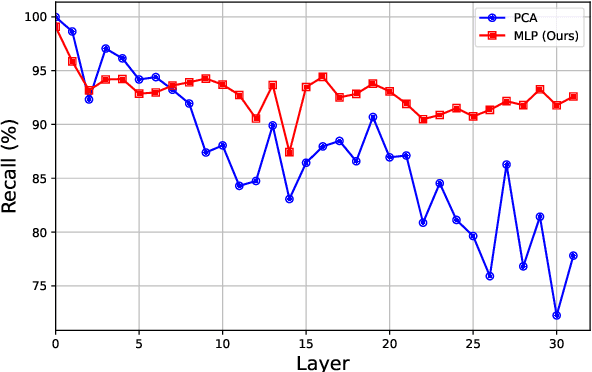
Handling long-context sequences efficiently remains a significant challenge in large language models (LLMs). Existing methods for token selection in sequence extrapolation either employ a permanent eviction strategy or select tokens by chunk, which may lead to the loss of critical information. We propose Efficient Selective Attention (ESA), a novel approach that extends context length by efficiently selecting the most critical tokens at the token level to compute attention. ESA reduces the computational complexity of token selection by compressing query and key vectors into lower-dimensional representations. We evaluate ESA on long sequence benchmarks with maximum lengths up to 256k using open-source LLMs with context lengths of 8k and 32k. ESA outperforms other selective attention methods, especially in tasks requiring the retrieval of multiple pieces of information, achieving comparable performance to full-attention extrapolation methods across various tasks, with superior results in certain tasks.