 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreventing Safety Drift in Large Language Models via Coupled Weight and Activation Constraints
Apr 14, 2026Safety alignment in Large Language Models (LLMs) remains highly fragile during fine-tuning, where even benign adaptation can degrade pre-trained refusal behaviors and enable harmful responses. Existing defenses typically constrain either weights or activations in isolation, without considering their coupled effects on safety. In this paper, we first theoretically demonstrate that constraining either weights or activations alone is insufficient for safety preservation. To robustly preserve safety alignment, we propose Coupled Weight and Activation Constraints (CWAC), a novel approach that simultaneously enforces a precomputed safety subspace on weight updates and applies targeted regularization to safety-critical features identified by sparse autoencoders. Extensive experiments across four widely used LLMs and diverse downstream tasks show that CWAC consistently achieves the lowest harmful scores with minimal impact on fine-tuning accuracy, substantially outperforming strong baselines even under high harmful data ratios.
Enhancing Chemical Reaction and Retrosynthesis Prediction with Large Language Model and Dual-task Learning
May 05, 2025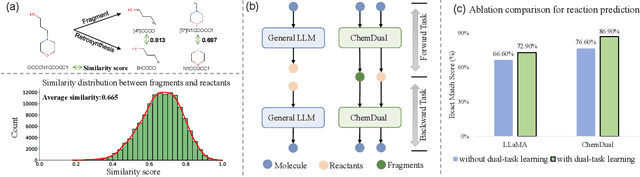
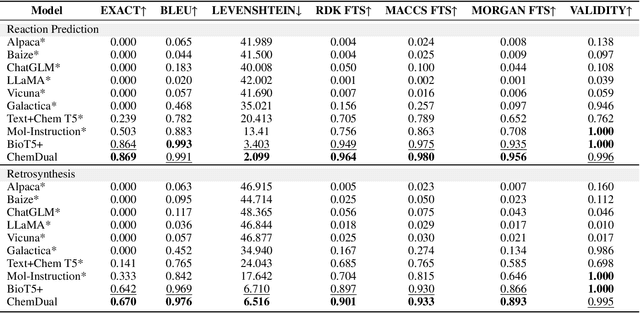


Chemical reaction and retrosynthesis prediction are fundamental tasks in drug discovery. Recently, large language models (LLMs) have shown potential in many domains. However, directly applying LLMs to these tasks faces two major challenges: (i) lacking a large-scale chemical synthesis-related instruction dataset; (ii) ignoring the close correlation between reaction and retrosynthesis prediction for the existing fine-tuning strategies. To address these challenges, we propose ChemDual, a novel LLM framework for accurate chemical synthesis. Specifically, considering the high cost of data acquisition for reaction and retrosynthesis, ChemDual regards the reaction-and-retrosynthesis of molecules as a related recombination-and-fragmentation process and constructs a large-scale of 4.4 million instruction dataset. Furthermore, ChemDual introduces an enhanced LLaMA, equipped with a multi-scale tokenizer and dual-task learning strategy, to jointly optimize the process of recombination and fragmentation as well as the tasks between reaction and retrosynthesis prediction. Extensive experiments on Mol-Instruction and USPTO-50K datasets demonstrate that ChemDual achieves state-of-the-art performance in both predictions of reaction and retrosynthesis, outperforming the existing conventional single-task approaches and the general open-source LLMs. Through molecular docking analysis, ChemDual generates compounds with diverse and strong protein binding affinity, further highlighting its strong potential in drug design.
Y-Mol: A Multiscale Biomedical Knowledge-Guided Large Language Model for Drug Development
Oct 15, 2024Large Language Models (LLMs) have recently demonstrated remarkable performance in general tasks across various fields. However, their effectiveness within specific domains such as drug development remains challenges. To solve these challenges, we introduce \textbf{Y-Mol}, forming a well-established LLM paradigm for the flow of drug development. Y-Mol is a multiscale biomedical knowledge-guided LLM designed to accomplish tasks across lead compound discovery, pre-clinic, and clinic prediction. By integrating millions of multiscale biomedical knowledge and using LLaMA2 as the base LLM, Y-Mol augments the reasoning capability in the biomedical domain by learning from a corpus of publications, knowledge graphs, and expert-designed synthetic data. The capability is further enriched with three types of drug-oriented instructions: description-based prompts from processed publications, semantic-based prompts for extracting associations from knowledge graphs, and template-based prompts for understanding expert knowledge from biomedical tools. Besides, Y-Mol offers a set of LLM paradigms that can autonomously execute the downstream tasks across the entire process of drug development, including virtual screening, drug design, pharmacological properties prediction, and drug-related interaction prediction. Our extensive evaluations of various biomedical sources demonstrate that Y-Mol significantly outperforms general-purpose LLMs in discovering lead compounds, predicting molecular properties, and identifying drug interaction events.
Whispers that Shake Foundations: Analyzing and Mitigating False Premise Hallucinations in Large Language Models
Feb 29, 2024Large Language Models (LLMs) have shown impressive capabilities but still suffer from the issue of hallucinations. A significant type of this issue is the false premise hallucination, which we define as the phenomenon when LLMs generate hallucinated text when confronted with false premise questions. In this paper, we perform a comprehensive analysis of the false premise hallucination and elucidate its internal working mechanism: a small subset of attention heads (which we designate as false premise heads) disturb the knowledge extraction process, leading to the occurrence of false premise hallucination. Based on our analysis, we propose \textbf{FAITH} (\textbf{F}alse premise \textbf{A}ttention head constra\textbf{I}ining for mi\textbf{T}igating \textbf{H}allucinations), a novel and effective method to mitigate false premise hallucinations. It constrains the false premise attention heads during the model inference process. Impressively, extensive experiments demonstrate that constraining only approximately $1\%$ of the attention heads in the model yields a notable increase of nearly $20\%$ of model performance.
Focus on Your Question! Interpreting and Mitigating Toxic CoT Problems in Commonsense Reasoning
Feb 28, 2024Large language models exhibit high-level commonsense reasoning abilities, especially with enhancement methods like Chain-of-Thought (CoT). However, we find these CoT-like methods lead to a considerable number of originally correct answers turning wrong, which we define as the Toxic CoT problem. To interpret and mitigate this problem, we first utilize attribution tracing and causal tracing methods to probe the internal working mechanism of the LLM during CoT reasoning. Through comparisons, we prove that the model exhibits information loss from the question over the shallow attention layers when generating rationales or answers. Based on the probing findings, we design a novel method called RIDERS (Residual decodIng and sERial-position Swap), which compensates for the information deficit in the model from both decoding and serial-position perspectives. Through extensive experiments on multiple commonsense reasoning benchmarks, we validate that this method not only significantly eliminates Toxic CoT problems (decreased by 23.6%), but also effectively improves the model's overall commonsense reasoning performance (increased by 5.5%).
Document-level Relation Extraction with Context Guided Mention Integration and Inter-pair Reasoning
Jan 13, 2022
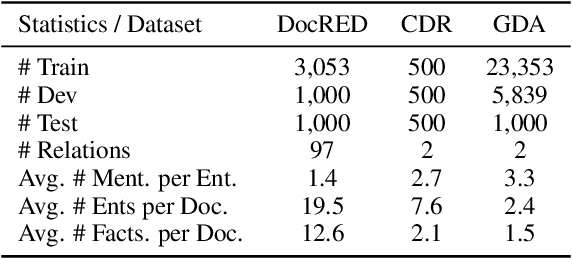

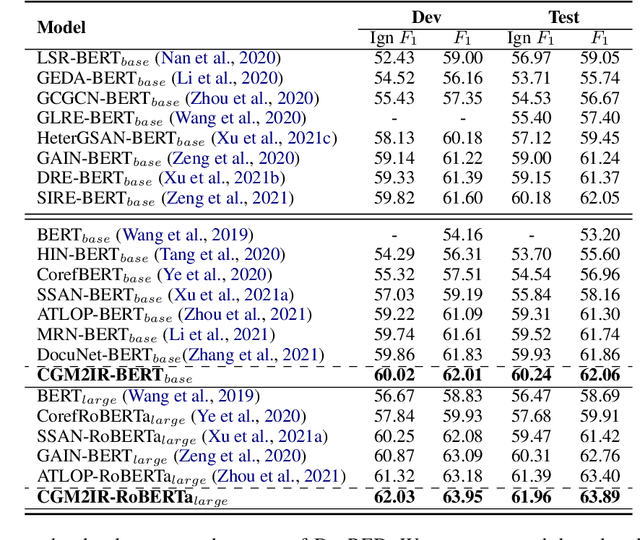
Document-level Relation Extraction (DRE) aims to recognize the relations between two entities. The entity may correspond to multiple mentions that span beyond sentence boundary. Few previous studies have investigated the mention integration, which may be problematic because coreferential mentions do not equally contribute to a specific relation. Moreover, prior efforts mainly focus on reasoning at entity-level rather than capturing the global interactions between entity pairs. In this paper, we propose two novel techniques, Context Guided Mention Integration and Inter-pair Reasoning (CGM2IR), to improve the DRE. Instead of simply applying average pooling, the contexts are utilized to guide the integration of coreferential mentions in a weighted sum manner. Additionally, inter-pair reasoning executes an iterative algorithm on the entity pair graph, so as to model the interdependency of relations. We evaluate our CGM2IR model on three widely used benchmark datasets, namely DocRED, CDR, and GDA. Experimental results show that our model outperforms previous state-of-the-art models.
Minimize Exposure Bias of Seq2Seq Models in Joint Entity and Relation Extraction
Oct 06, 2020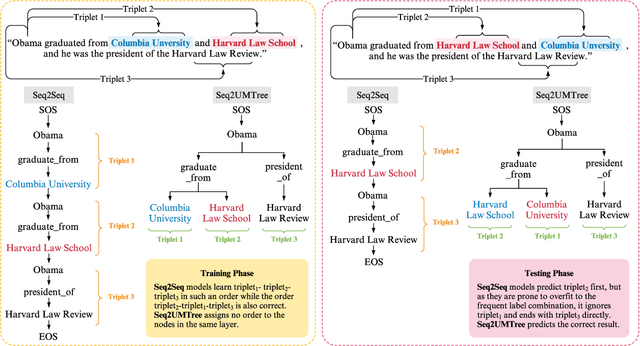
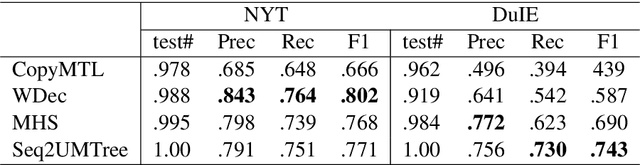
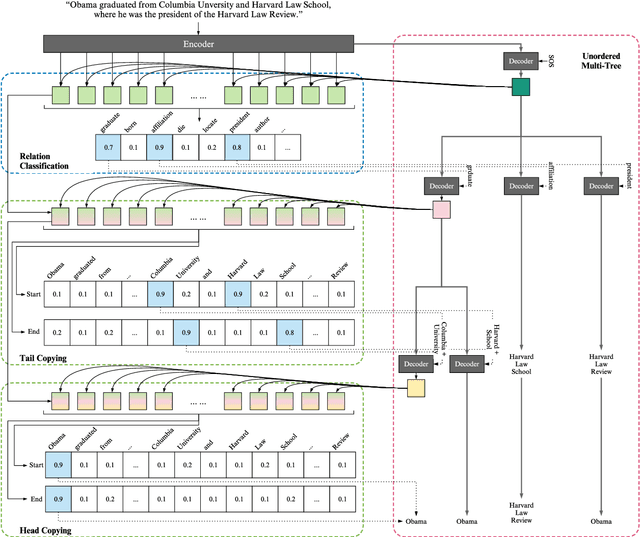
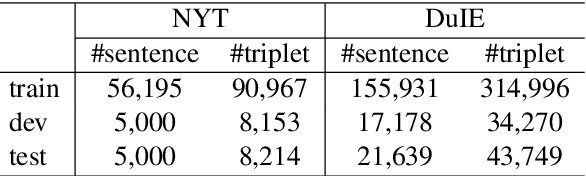
Joint entity and relation extraction aims to extract relation triplets from plain text directly. Prior work leverages Sequence-to-Sequence (Seq2Seq) models for triplet sequence generation. However, Seq2Seq enforces an unnecessary order on the unordered triplets and involves a large decoding length associated with error accumulation. These introduce exposure bias, which may cause the models overfit to the frequent label combination, thus deteriorating the generalization. We propose a novel Sequence-to-Unordered-Multi-Tree (Seq2UMTree) model to minimize the effects of exposure bias by limiting the decoding length to three within a triplet and removing the order among triplets. We evaluate our model on two datasets, DuIE and NYT, and systematically study how exposure bias alters the performance of Seq2Seq models. Experiments show that the state-of-the-art Seq2Seq model overfits to both datasets while Seq2UMTree shows significantly better generalization. Our code is available at https://github.com/WindChimeRan/OpenJERE .
CopyMTL: Copy Mechanism for Joint Extraction of Entities and Relations with Multi-Task Learning
Nov 24, 2019
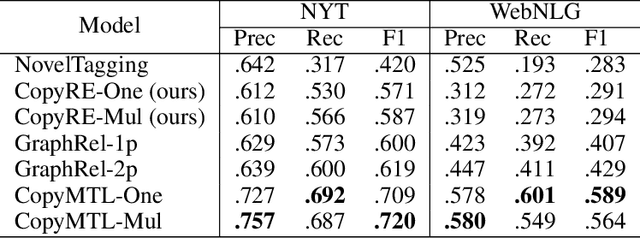
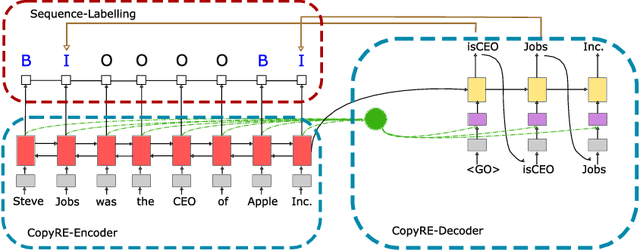
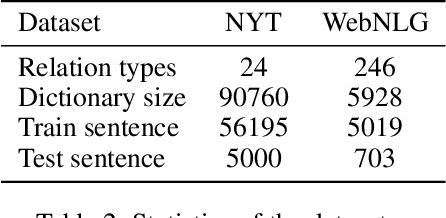
Joint extraction of entities and relations has received significant attention due to its potential of providing higher performance for both tasks. Among existing methods, CopyRE is effective and novel, which uses a sequence-to-sequence framework and copy mechanism to directly generate the relation triplets. However, it suffers from two fatal problems. The model is extremely weak at differing the head and tail entity, resulting in inaccurate entity extraction. It also cannot predict multi-token entities (e.g. \textit{Steven Jobs}). To address these problems, we give a detailed analysis of the reasons behind the inaccurate entity extraction problem, and then propose a simple but extremely effective model structure to solve this problem. In addition, we propose a multi-task learning framework equipped with copy mechanism, called CopyMTL, to allow the model to predict multi-token entities. Experiments reveal the problems of CopyRE and show that our model achieves significant improvement over the current state-of-the-art method by 9% in NYT and 16% in WebNLG (F1 score). Our code is available at https://github.com/WindChimeRan/CopyMTL