 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRULE: Reinforcement UnLEarning Achieves Forget-Retain Pareto Optimality
Jun 08, 2025The widespread deployment of Large Language Models (LLMs) trained on massive, uncurated corpora has raised growing concerns about the inclusion of sensitive, copyrighted, or illegal content. This has led to increasing interest in LLM unlearning: the task of selectively removing specific information from a model without retraining from scratch or degrading overall utility. However, existing methods often rely on large-scale forget and retain datasets, and suffer from unnatural responses, poor generalization, or catastrophic utility loss. In this work, we propose Reinforcement UnLearning (RULE), an efficient framework that formulates unlearning as a refusal boundary optimization problem. RULE is trained with a small portion of the forget set and synthesized boundary queries, using a verifiable reward function that encourages safe refusal on forget--related queries while preserving helpful responses on permissible inputs. We provide both theoretical and empirical evidence demonstrating the effectiveness of RULE in achieving targeted unlearning without compromising model utility. Experimental results show that, with only $12%$ forget set and $8%$ synthesized boundary data, RULE outperforms existing baselines by up to $17.5%$ forget quality and $16.3%$ naturalness response while maintaining general utility, achieving forget--retain Pareto optimality. Remarkably, we further observe that RULE improves the naturalness of model outputs, enhances training efficiency, and exhibits strong generalization ability, generalizing refusal behavior to semantically related but unseen queries.
MMR-V: What's Left Unsaid? A Benchmark for Multimodal Deep Reasoning in Videos
Jun 04, 2025The sequential structure of videos poses a challenge to the ability of multimodal large language models (MLLMs) to locate multi-frame evidence and conduct multimodal reasoning. However, existing video benchmarks mainly focus on understanding tasks, which only require models to match frames mentioned in the question (hereafter referred to as "question frame") and perceive a few adjacent frames. To address this gap, we propose MMR-V: A Benchmark for Multimodal Deep Reasoning in Videos. The benchmark is characterized by the following features. (1) Long-range, multi-frame reasoning: Models are required to infer and analyze evidence frames that may be far from the question frame. (2) Beyond perception: Questions cannot be answered through direct perception alone but require reasoning over hidden information. (3) Reliability: All tasks are manually annotated, referencing extensive real-world user understanding to align with common perceptions. (4) Confusability: Carefully designed distractor annotation strategies to reduce model shortcuts. MMR-V consists of 317 videos and 1,257 tasks. Our experiments reveal that current models still struggle with multi-modal reasoning; even the best-performing model, o4-mini, achieves only 52.5% accuracy. Additionally, current reasoning enhancement strategies (Chain-of-Thought and scaling test-time compute) bring limited gains. Further analysis indicates that the CoT demanded for multi-modal reasoning differs from it in textual reasoning, which partly explains the limited performance gains. We hope that MMR-V can inspire further research into enhancing multi-modal reasoning capabilities.
Establishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis
Jun 04, 2025The development of large language models (LLMs) depends on trustworthy evaluation. However, most current evaluations rely on public benchmarks, which are prone to data contamination issues that significantly compromise fairness. Previous researches have focused on constructing dynamic benchmarks to address contamination. However, continuously building new benchmarks is costly and cyclical. In this work, we aim to tackle contamination by analyzing the mechanisms of contaminated models themselves. Through our experiments, we discover that the overestimation of contaminated models is likely due to parameters acquiring shortcut solutions in training. We further propose a novel method for identifying shortcut neurons through comparative and causal analysis. Building on this, we introduce an evaluation method called shortcut neuron patching to suppress shortcut neurons. Experiments validate the effectiveness of our approach in mitigating contamination. Additionally, our evaluation results exhibit a strong linear correlation with MixEval, a recently released trustworthy benchmark, achieving a Spearman coefficient ($\rho$) exceeding 0.95. This high correlation indicates that our method closely reveals true capabilities of the models and is trustworthy. We conduct further experiments to demonstrate the generalizability of our method across various benchmarks and hyperparameter settings. Code: https://github.com/GaryStack/Trustworthy-Evaluation
FinRAGBench-V: A Benchmark for Multimodal RAG with Visual Citation in the Financial Domain
May 23, 2025Retrieval-Augmented Generation (RAG) plays a vital role in the financial domain, powering applications such as real-time market analysis, trend forecasting, and interest rate computation. However, most existing RAG research in finance focuses predominantly on textual data, overlooking the rich visual content in financial documents, resulting in the loss of key analytical insights. To bridge this gap, we present FinRAGBench-V, a comprehensive visual RAG benchmark tailored for finance which effectively integrates multimodal data and provides visual citation to ensure traceability. It includes a bilingual retrieval corpus with 60,780 Chinese and 51,219 English pages, along with a high-quality, human-annotated question-answering (QA) dataset spanning heterogeneous data types and seven question categories. Moreover, we introduce RGenCite, an RAG baseline that seamlessly integrates visual citation with generation. Furthermore, we propose an automatic citation evaluation method to systematically assess the visual citation capabilities of Multimodal Large Language Models (MLLMs). Extensive experiments on RGenCite underscore the challenging nature of FinRAGBench-V, providing valuable insights for the development of multimodal RAG systems in finance.
RAG-RewardBench: Benchmarking Reward Models in Retrieval Augmented Generation for Preference Alignment
Dec 18, 2024



Despite the significant progress made by existing retrieval augmented language models (RALMs) in providing trustworthy responses and grounding in reliable sources, they often overlook effective alignment with human preferences. In the alignment process, reward models (RMs) act as a crucial proxy for human values to guide optimization. However, it remains unclear how to evaluate and select a reliable RM for preference alignment in RALMs. To this end, we propose RAG-RewardBench, the first benchmark for evaluating RMs in RAG settings. First, we design four crucial and challenging RAG-specific scenarios to assess RMs, including multi-hop reasoning, fine-grained citation, appropriate abstain, and conflict robustness. Then, we incorporate 18 RAG subsets, six retrievers, and 24 RALMs to increase the diversity of data sources. Finally, we adopt an LLM-as-a-judge approach to improve preference annotation efficiency and effectiveness, exhibiting a strong correlation with human annotations. Based on the RAG-RewardBench, we conduct a comprehensive evaluation of 45 RMs and uncover their limitations in RAG scenarios. Additionally, we also reveal that existing trained RALMs show almost no improvement in preference alignment, highlighting the need for a shift towards preference-aligned training.We release our benchmark and code publicly at https://huggingface.co/datasets/jinzhuoran/RAG-RewardBench/ for future work.
One Mind, Many Tongues: A Deep Dive into Language-Agnostic Knowledge Neurons in Large Language Models
Nov 26, 2024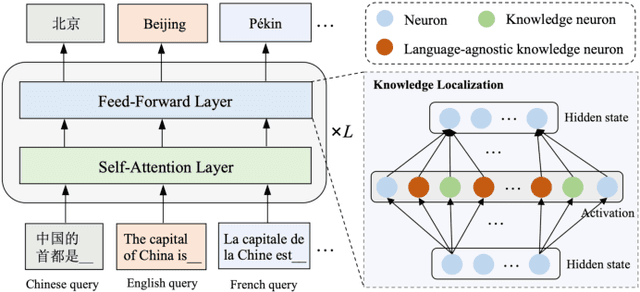
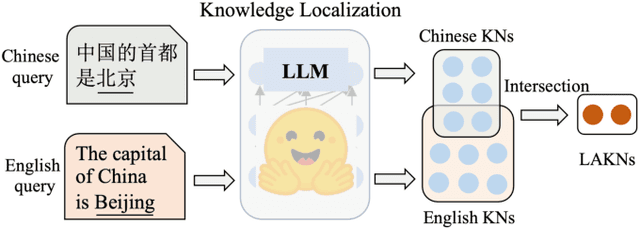
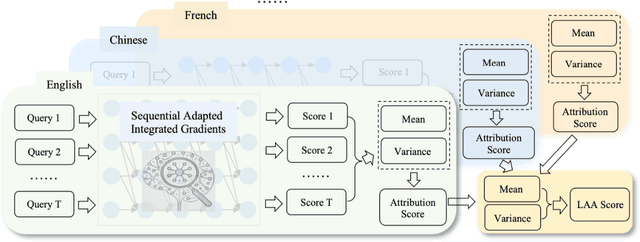
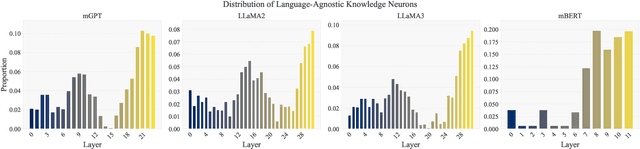
Large language models (LLMs) have learned vast amounts of factual knowledge through self-supervised pre-training on large-scale corpora. Meanwhile, LLMs have also demonstrated excellent multilingual capabilities, which can express the learned knowledge in multiple languages. However, the knowledge storage mechanism in LLMs still remains mysterious. Some researchers attempt to demystify the factual knowledge in LLMs from the perspective of knowledge neurons, and subsequently discover language-agnostic knowledge neurons that store factual knowledge in a form that transcends language barriers. However, the preliminary finding suffers from two limitations: 1) High Uncertainty in Localization Results. Existing study only uses a prompt-based probe to localize knowledge neurons for each fact, while LLMs cannot provide consistent answers for semantically equivalent queries. Thus, it leads to inaccurate localization results with high uncertainty. 2) Lack of Analysis in More Languages. The study only analyzes language-agnostic knowledge neurons on English and Chinese data, without exploring more language families and languages. Naturally, it limits the generalizability of the findings. To address aforementioned problems, we first construct a new benchmark called Rephrased Multilingual LAMA (RML-LAMA), which contains high-quality cloze-style multilingual parallel queries for each fact. Then, we propose a novel method named Multilingual Integrated Gradients with Uncertainty Estimation (MATRICE), which quantifies the uncertainty across queries and languages during knowledge localization. Extensive experiments show that our method can accurately localize language-agnostic knowledge neurons. We also further investigate the role of language-agnostic knowledge neurons in cross-lingual knowledge editing, knowledge enhancement and new knowledge injection.
DTELS: Towards Dynamic Granularity of Timeline Summarization
Nov 14, 2024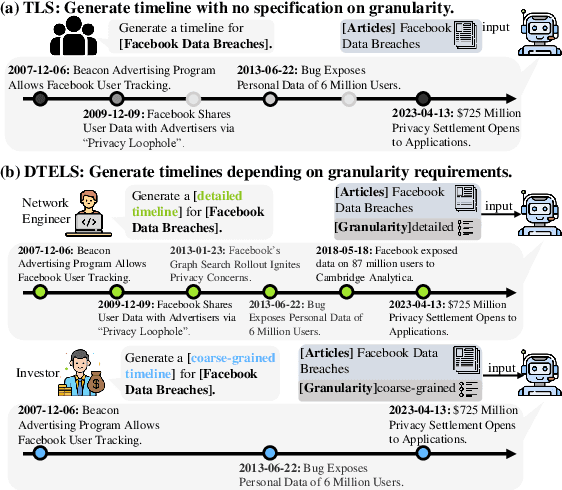
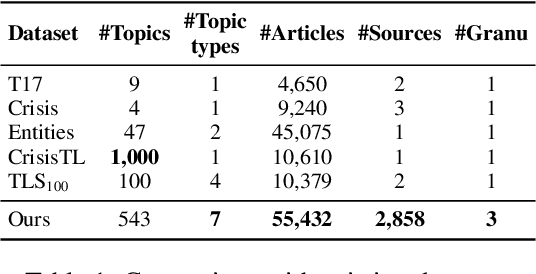
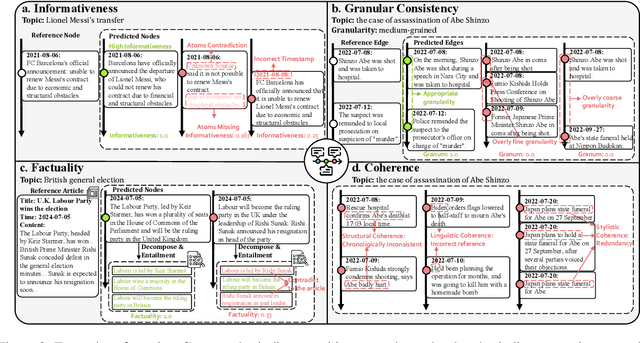

The rapid proliferation of online news has posed significant challenges in tracking the continuous development of news topics. Traditional timeline summarization constructs a chronological summary of the events but often lacks the flexibility to meet the diverse granularity needs. To overcome this limitation, we introduce a new paradigm, Dynamic-granularity TimELine Summarization, (DTELS), which aims to construct adaptive timelines based on user instructions or requirements. This paper establishes a comprehensive benchmark for DTLES that includes: (1) an evaluation framework grounded in journalistic standards to assess the timeline quality across four dimensions: Informativeness, Granular Consistency, Factuality, and Coherence; (2) a large-scale, multi-source dataset with multiple granularity timeline annotations based on a consensus process to facilitate authority; (3) extensive experiments and analysis with two proposed solutions based on Large Language Models (LLMs) and existing state-of-the-art TLS methods. The experimental results demonstrate the effectiveness of LLM-based solutions. However, even the most advanced LLMs struggle to consistently generate timelines that are both informative and granularly consistent, highlighting the challenges of the DTELS task.
A Troublemaker with Contagious Jailbreak Makes Chaos in Honest Towns
Oct 21, 2024With the development of large language models, they are widely used as agents in various fields. A key component of agents is memory, which stores vital information but is susceptible to jailbreak attacks. Existing research mainly focuses on single-agent attacks and shared memory attacks. However, real-world scenarios often involve independent memory. In this paper, we propose the Troublemaker Makes Chaos in Honest Town (TMCHT) task, a large-scale, multi-agent, multi-topology text-based attack evaluation framework. TMCHT involves one attacker agent attempting to mislead an entire society of agents. We identify two major challenges in multi-agent attacks: (1) Non-complete graph structure, (2) Large-scale systems. We attribute these challenges to a phenomenon we term toxicity disappearing. To address these issues, we propose an Adversarial Replication Contagious Jailbreak (ARCJ) method, which optimizes the retrieval suffix to make poisoned samples more easily retrieved and optimizes the replication suffix to make poisoned samples have contagious ability. We demonstrate the superiority of our approach in TMCHT, with 23.51%, 18.95%, and 52.93% improvements in line topology, star topology, and 100-agent settings. Encourage community attention to the security of multi-agent systems.
MIRAGE: Evaluating and Explaining Inductive Reasoning Process in Language Models
Oct 12, 2024



Inductive reasoning is an essential capability for large language models (LLMs) to achieve higher intelligence, which requires the model to generalize rules from observed facts and then apply them to unseen examples. We present {\scshape Mirage}, a synthetic dataset that addresses the limitations of previous work, specifically the lack of comprehensive evaluation and flexible test data. In it, we evaluate LLMs' capabilities in both the inductive and deductive stages, allowing for flexible variation in input distribution, task scenario, and task difficulty to analyze the factors influencing LLMs' inductive reasoning. Based on these multi-faceted evaluations, we demonstrate that the LLM is a poor rule-based reasoner. In many cases, when conducting inductive reasoning, they do not rely on a correct rule to answer the unseen case. From the perspectives of different prompting methods, observation numbers, and task forms, models tend to consistently conduct correct deduction without correct inductive rules. Besides, we find that LLMs are good neighbor-based reasoners. In the inductive reasoning process, the model tends to focus on observed facts that are close to the current test example in feature space. By leveraging these similar examples, the model maintains strong inductive capabilities within a localized region, significantly improving its deductive performance.
LINKED: Eliciting, Filtering and Integrating Knowledge in Large Language Model for Commonsense Reasoning
Oct 12, 2024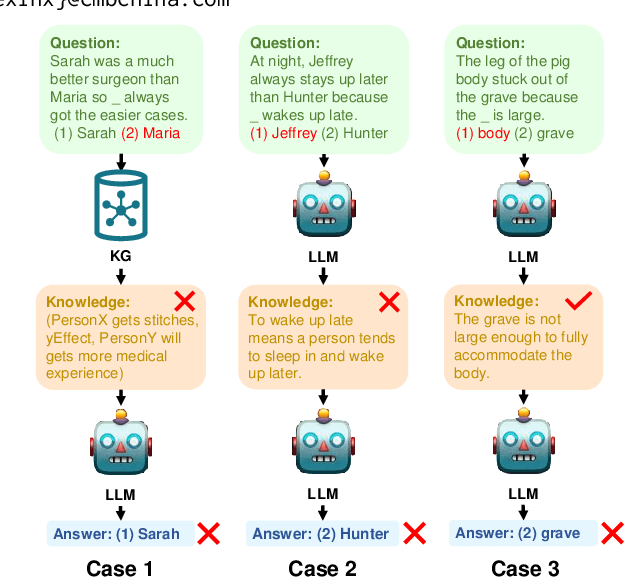

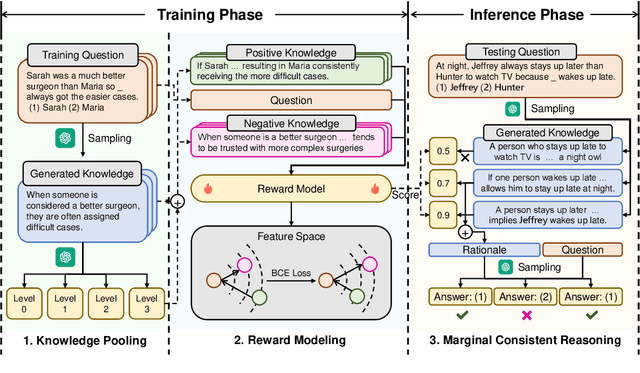

Large language models (LLMs) sometimes demonstrate poor performance on knowledge-intensive tasks, commonsense reasoning is one of them. Researchers typically address these issues by retrieving related knowledge from knowledge graphs or employing self-enhancement methods to elicit knowledge in LLMs. However, noisy knowledge and invalid reasoning issues hamper their ability to answer questions accurately. To this end, we propose a novel method named eliciting, filtering and integrating knowledge in large language model (LINKED). In it, we design a reward model to filter out the noisy knowledge and take the marginal consistent reasoning module to reduce invalid reasoning. With our comprehensive experiments on two complex commonsense reasoning benchmarks, our method outperforms SOTA baselines (up to 9.0% improvement of accuracy). Besides, to measure the positive and negative impact of the injected knowledge, we propose a new metric called effectiveness-preservation score for the knowledge enhancement works. Finally, through extensive experiments, we conduct an in-depth analysis and find many meaningful conclusions about LLMs in commonsense reasoning tasks.