 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplay What Matters: Off-Policy Replay for Efficient LLM Reinforcement Unlearning
Jun 13, 2026LLM unlearning has emerged as a cost-effective alternative to full retraining for removing hazardous knowledge from pretrained models while preserving general utility. Recent RL-based methods such as RULE reformulate unlearning as learning a refusal behavior, but their on-policy optimization repeatedly samples from the same forget and retain/boundary prompts throughout training. We identify a critical inefficiency in this process: easy cases quickly converge and provide little useful gradient signal, while hard cases near the forget/retain boundary continue to produce low-reward rollouts that are discarded after a single use. To address this issue, we propose ReRULE, an off-policy replay enhancement for reinforcement unlearning. ReRULE stores low-reward hard-case rollout groups in a replay buffer during early GRPO training and reuses them in later stages through importance-sampled off-policy updates, redirecting computation toward boundary cases that still require learning. Theoretically, we show that ReRULE yields a tighter hard-case convergence bound than pure on-policy RULE. Empirically, ReRULE improves MUSE-Books Retain Quality from 46.3 to 56.2 while adding only 5--11% training time across benchmarks. Its limited improvement on the simpler TOFU setting further supports the intended conditional behavior: replay is most beneficial when the hard/easy disparity is pronounced.
Agents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
SemEval-2026 Task 12: Abductive Event Reasoning: Towards Real-World Event Causal Inference for Large Language Models
Mar 23, 2026Understanding why real-world events occur is important for both natural language processing and practical decision-making, yet direct-cause inference remains underexplored in evidence-rich settings. To address this gap, we organized SemEval-2026 Task 12: Abductive Event Reasoning (AER).\footnote{The task data is available at https://github.com/sooo66/semeval2026-task12-dataset.git} The task asks systems to identify the most plausible direct cause of a target event from supporting evidence. We formulate AER as an evidence-grounded multiple-choice benchmark that captures key challenges of real-world causal reasoning, including distributed evidence, indirect background factors, and semantically related but non-causal distractors. The shared task attracted 122 participants and received 518 submissions. This paper presents the task formulation, dataset construction pipeline, evaluation setup, and system results. AER provides a focused benchmark for abductive reasoning over real-world events and highlights challenges for future work on causal reasoning and multi-document understanding.
MMR-Life: Piecing Together Real-life Scenes for Multimodal Multi-image Reasoning
Mar 02, 2026Recent progress in the reasoning capabilities of multimodal large language models (MLLMs) has empowered them to address more complex tasks such as scientific analysis and mathematical reasoning. Despite their promise, MLLMs' reasoning abilities across different scenarios in real life remain largely unexplored and lack standardized benchmarks for evaluation. To address this gap, we introduce MMR-Life, a comprehensive benchmark designed to evaluate the diverse multimodal multi-image reasoning capabilities of MLLMs across real-life scenarios. MMR-Life consists of 2,646 multiple-choice questions based on 19,108 images primarily sourced from real-world contexts, comprehensively covering seven reasoning types: abductive, analogical, causal, deductive, inductive, spatial, and temporal. Unlike existing reasoning benchmarks, MMR-Life does not rely on domain-specific expertise but instead requires models to integrate information across multiple images and apply diverse reasoning abilities. The evaluation of 37 advanced models highlights the substantial challenge posed by MMR-Life. Even top models like GPT-5 achieve only 58% accuracy and display considerable variance in performance across reasoning types. Moreover, we analyze the reasoning paradigms of existing MLLMs, exploring how factors such as thinking length, reasoning method, and reasoning type affect their performance. In summary, MMR-Life establishes a comprehensive foundation for evaluating, analyzing, and improving the next generation of multimodal reasoning systems.
Dual-View Disentangled Multi-Intent Learning for Enhanced Collaborative Filtering
Jun 13, 2025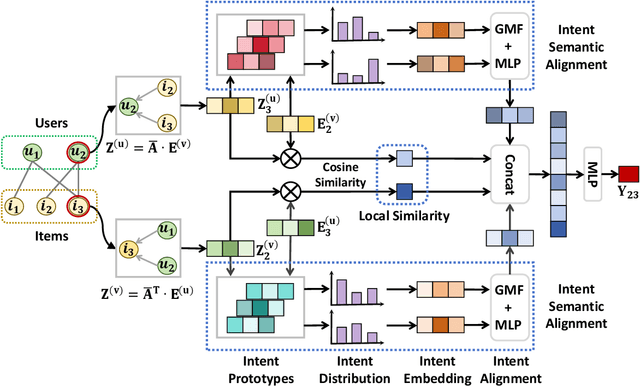
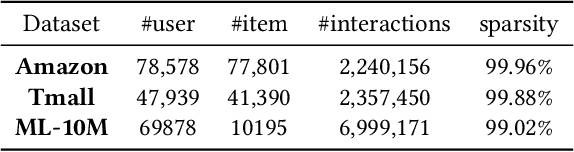
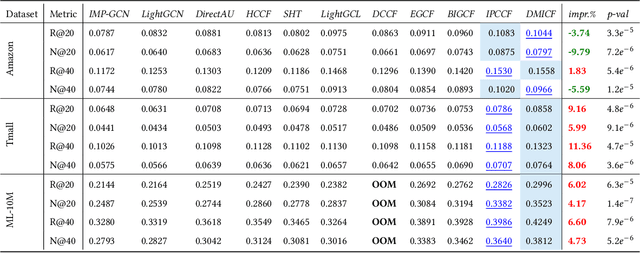
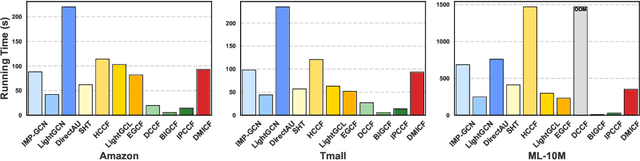
Disentangling user intentions from implicit feedback has become a promising strategy to enhance recommendation accuracy and interpretability. Prior methods often model intentions independently and lack explicit supervision, thus failing to capture the joint semantics that drive user-item interactions. To address these limitations, we propose DMICF, a unified framework that explicitly models interaction-level intent alignment while leveraging structural signals from both user and item perspectives. DMICF adopts a dual-view architecture that jointly encodes user-item interaction graphs from both sides, enabling bidirectional information fusion. This design enhances robustness under data sparsity by allowing the structural redundancy of one view to compensate for the limitations of the other. To model fine-grained user-item compatibility, DMICF introduces an intent interaction encoder that performs sub-intent alignment within each view, uncovering shared semantic structures that underlie user decisions. This localized alignment enables adaptive refinement of intent embeddings based on interaction context, thus improving the model's generalization and expressiveness, particularly in long-tail scenarios. Furthermore, DMICF integrates an intent-aware scoring mechanism that aggregates compatibility signals from matched intent pairs across user and item subspaces, enabling personalized prediction grounded in semantic congruence rather than entangled representations. To facilitate semantic disentanglement, we design a discriminative training signal via multi-negative sampling and softmax normalization, which pulls together semantically aligned intent pairs while pushing apart irrelevant or noisy ones. Extensive experiments demonstrate that DMICF consistently delivers robust performance across datasets with diverse interaction distributions.
RULE: Reinforcement UnLEarning Achieves Forget-Retain Pareto Optimality
Jun 08, 2025The widespread deployment of Large Language Models (LLMs) trained on massive, uncurated corpora has raised growing concerns about the inclusion of sensitive, copyrighted, or illegal content. This has led to increasing interest in LLM unlearning: the task of selectively removing specific information from a model without retraining from scratch or degrading overall utility. However, existing methods often rely on large-scale forget and retain datasets, and suffer from unnatural responses, poor generalization, or catastrophic utility loss. In this work, we propose Reinforcement UnLearning (RULE), an efficient framework that formulates unlearning as a refusal boundary optimization problem. RULE is trained with a small portion of the forget set and synthesized boundary queries, using a verifiable reward function that encourages safe refusal on forget--related queries while preserving helpful responses on permissible inputs. We provide both theoretical and empirical evidence demonstrating the effectiveness of RULE in achieving targeted unlearning without compromising model utility. Experimental results show that, with only $12%$ forget set and $8%$ synthesized boundary data, RULE outperforms existing baselines by up to $17.5%$ forget quality and $16.3%$ naturalness response while maintaining general utility, achieving forget--retain Pareto optimality. Remarkably, we further observe that RULE improves the naturalness of model outputs, enhances training efficiency, and exhibits strong generalization ability, generalizing refusal behavior to semantically related but unseen queries.
DTELS: Towards Dynamic Granularity of Timeline Summarization
Nov 14, 2024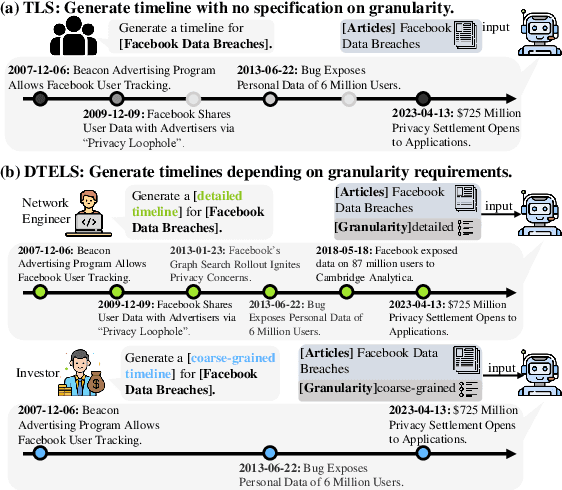
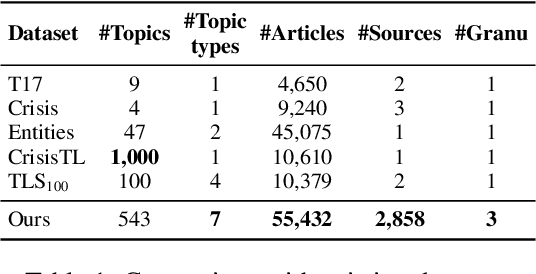
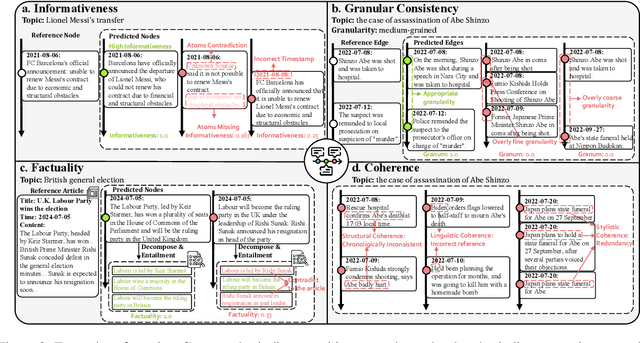

The rapid proliferation of online news has posed significant challenges in tracking the continuous development of news topics. Traditional timeline summarization constructs a chronological summary of the events but often lacks the flexibility to meet the diverse granularity needs. To overcome this limitation, we introduce a new paradigm, Dynamic-granularity TimELine Summarization, (DTELS), which aims to construct adaptive timelines based on user instructions or requirements. This paper establishes a comprehensive benchmark for DTLES that includes: (1) an evaluation framework grounded in journalistic standards to assess the timeline quality across four dimensions: Informativeness, Granular Consistency, Factuality, and Coherence; (2) a large-scale, multi-source dataset with multiple granularity timeline annotations based on a consensus process to facilitate authority; (3) extensive experiments and analysis with two proposed solutions based on Large Language Models (LLMs) and existing state-of-the-art TLS methods. The experimental results demonstrate the effectiveness of LLM-based solutions. However, even the most advanced LLMs struggle to consistently generate timelines that are both informative and granularly consistent, highlighting the challenges of the DTELS task.
Continual Few-shot Event Detection via Hierarchical Augmentation Networks
Mar 26, 2024Traditional continual event detection relies on abundant labeled data for training, which is often impractical to obtain in real-world applications. In this paper, we introduce continual few-shot event detection (CFED), a more commonly encountered scenario when a substantial number of labeled samples are not accessible. The CFED task is challenging as it involves memorizing previous event types and learning new event types with few-shot samples. To mitigate these challenges, we propose a memory-based framework: Hierarchical Augmentation Networks (HANet). To memorize previous event types with limited memory, we incorporate prototypical augmentation into the memory set. For the issue of learning new event types in few-shot scenarios, we propose a contrastive augmentation module for token representations. Despite comparing with previous state-of-the-art methods, we also conduct comparisons with ChatGPT. Experiment results demonstrate that our method significantly outperforms all of these methods in multiple continual few-shot event detection tasks.