 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Performance Maximizing Ensembles with Explainability Guarantees
Dec 22, 2023In this paper we propose a method for the optimal allocation of observations between an intrinsically explainable glass box model and a black box model. An optimal allocation being defined as one which, for any given explainability level (i.e. the proportion of observations for which the explainable model is the prediction function), maximizes the performance of the ensemble on the underlying task, and maximizes performance of the explainable model on the observations allocated to it, subject to the maximal ensemble performance condition. The proposed method is shown to produce such explainability optimal allocations on a benchmark suite of tabular datasets across a variety of explainable and black box model types. These learned allocations are found to consistently maintain ensemble performance at very high explainability levels (explaining $74\%$ of observations on average), and in some cases even outperforming both the component explainable and black box models while improving explainability.
Epsilon Consistent Mixup: An Adaptive Consistency-Interpolation Tradeoff
Apr 19, 2021
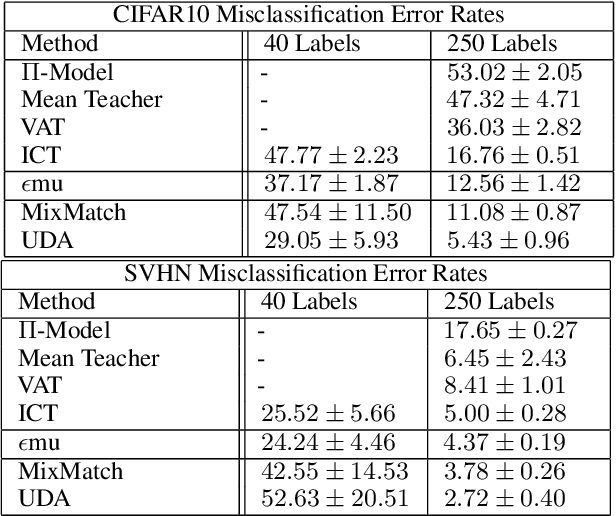

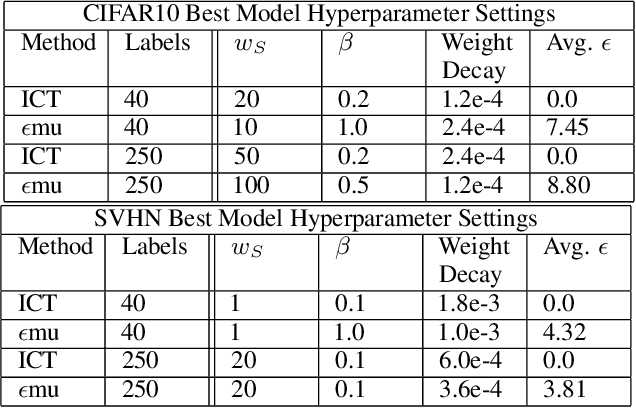
In this paper we propose $\epsilon$-Consistent Mixup ($\epsilon$mu). $\epsilon$mu is a data-based structural regularization technique that combines Mixup's linear interpolation with consistency regularization in the Mixup direction, by compelling a simple adaptive tradeoff between the two. This learnable combination of consistency and interpolation induces a more flexible structure on the evolution of the response across the feature space and is shown to improve semi-supervised classification accuracy on the SVHN and CIFAR10 benchmark datasets, yielding the largest gains in the most challenging low label-availability scenarios. Empirical studies comparing $\epsilon$mu and Mixup are presented and provide insight into the mechanisms behind $\epsilon$mu's effectiveness. In particular, $\epsilon$mu is found to produce more accurate synthetic labels and more confident predictions than Mixup.
Semi-Supervised Cervical Dysplasia Classification With Learnable Graph Convolutional Network
Apr 01, 2020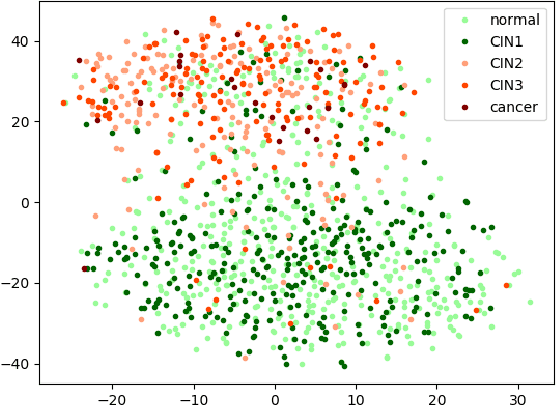

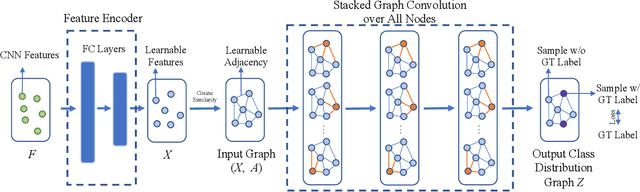
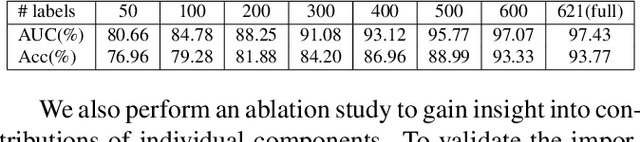
Cervical cancer is the second most prevalent cancer affecting women today. As the early detection of cervical carcinoma relies heavily upon screening and pre-clinical testing, digital cervicography has great potential as a primary or auxiliary screening tool, especially in low-resource regions due to its low cost and easy access. Although an automated cervical dysplasia detection system has been desirable, traditional fully-supervised training of such systems requires large amounts of annotated data which are often labor-intensive to collect. To alleviate the need for much manual annotation, we propose a novel graph convolutional network (GCN) based semi-supervised classification model that can be trained with fewer annotations. In existing GCNs, graphs are constructed with fixed features and can not be updated during the learning process. This limits their ability to exploit new features learned during graph convolution. In this paper, we propose a novel and more flexible GCN model with a feature encoder that adaptively updates the adjacency matrix during learning and demonstrate that this model design leads to improved performance. Our experimental results on a cervical dysplasia classification dataset show that the proposed framework outperforms previous methods under a semi-supervised setting, especially when the labeled samples are scarce.