 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Kronecker-Structured Graphs from Smooth Signals
May 14, 2025Graph learning, or network inference, is a prominent problem in graph signal processing (GSP). GSP generalizes the Fourier transform to non-Euclidean domains, and graph learning is pivotal to applying GSP when these domains are unknown. With the recent prevalence of multi-way data, there has been growing interest in product graphs that naturally factorize dependencies across different ways. However, the types of graph products that can be learned are still limited for modeling diverse dependency structures. In this paper, we study the problem of learning a Kronecker-structured product graph from smooth signals. Unlike the more commonly used Cartesian product, the Kronecker product models dependencies in a more intricate, non-separable way, but posits harder constraints on the graph learning problem. To tackle this non-convex problem, we propose an alternating scheme to optimize each factor graph and provide theoretical guarantees for its asymptotic convergence. The proposed algorithm is also modified to learn factor graphs of the strong product. We conduct experiments on synthetic and real-world graphs and demonstrate our approach's efficacy and superior performance compared to existing methods.
Learning Cartesian Product Graphs with Laplacian Constraints
Feb 12, 2024Graph Laplacian learning, also known as network topology inference, is a problem of great interest to multiple communities. In Gaussian graphical models (GM), graph learning amounts to endowing covariance selection with the Laplacian structure. In graph signal processing (GSP), it is essential to infer the unobserved graph from the outputs of a filtering system. In this paper, we study the problem of learning Cartesian product graphs under Laplacian constraints. The Cartesian graph product is a natural way for modeling higher-order conditional dependencies and is also the key for generalizing GSP to multi-way tensors. We establish statistical consistency for the penalized maximum likelihood estimation (MLE) of a Cartesian product Laplacian, and propose an efficient algorithm to solve the problem. We also extend our method for efficient joint graph learning and imputation in the presence of structural missing values. Experiments on synthetic and real-world datasets demonstrate that our method is superior to previous GSP and GM methods.
Graph Laplacian Learning with Exponential Family Noise
Jun 14, 2023



A common challenge in applying graph machine learning methods is that the underlying graph of a system is often unknown. Although different graph inference methods have been proposed for continuous graph signals, inferring the graph structure underlying other types of data, such as discrete counts, is under-explored. In this paper, we generalize a graph signal processing (GSP) framework for learning a graph from smooth graph signals to the exponential family noise distribution to model various data types. We propose an alternating algorithm that estimates the graph Laplacian as well as the unobserved smooth representation from the noisy signals. We demonstrate in synthetic and real-world data that our new algorithm outperforms competing Laplacian estimation methods under noise model mismatch.
Exploring Compositional Visual Generation with Latent Classifier Guidance
Apr 25, 2023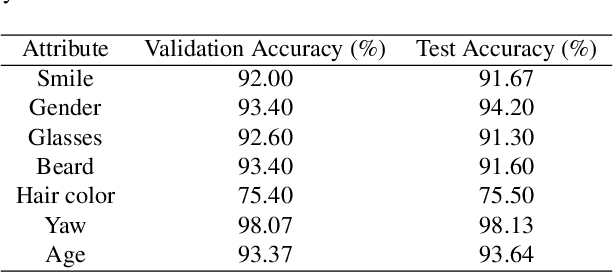



Diffusion probabilistic models have achieved enormous success in the field of image generation and manipulation. In this paper, we explore a novel paradigm of using the diffusion model and classifier guidance in the latent semantic space for compositional visual tasks. linear fashion. Specifically, we train latent diffusion models and auxiliary latent classifiers to facilitate non-linear navigation of latent representation generation for any pre-trained generative model with a semantic latent space. We demonstrate that such conditional generation achieved by latent classifier guidance provably maximizes a lower bound of the conditional log probability during training. To maintain the original semantics during manipulation, we introduce a new guidance term, which we show is crucial for achieving compositionality. With additional assumptions, we show that the non-linear manipulation reduces to a simple latent arithmetic approach. We show that this paradigm based on latent classifier guidance is agnostic to pre-trained generative models, and present competitive results for both image generation and sequential manipulation of real and synthetic images. Our findings suggest that latent classifier guidance is a promising approach that merits further exploration, even in the presence of other strong competing methods.
Conditional Image-to-Video Generation with Latent Flow Diffusion Models
Mar 24, 2023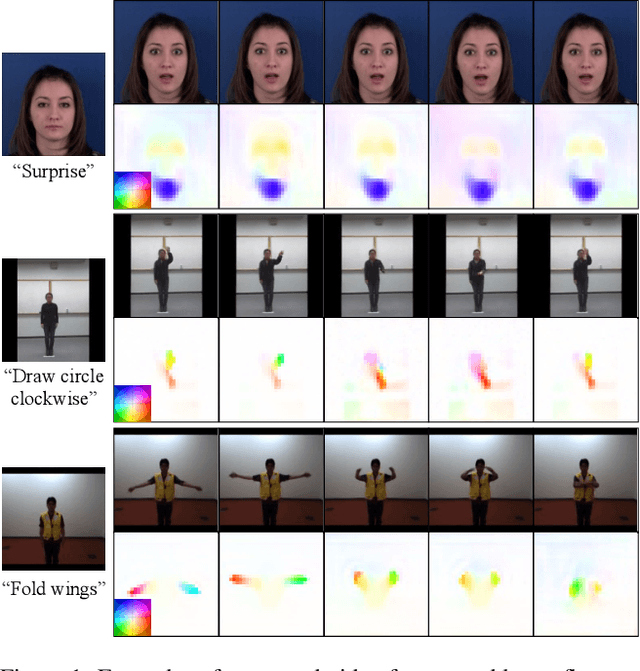

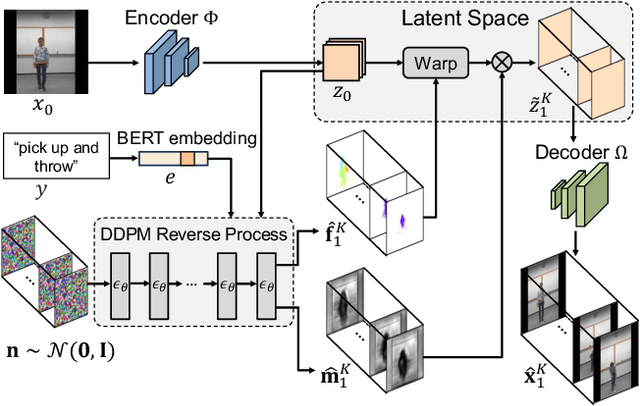

Conditional image-to-video (cI2V) generation aims to synthesize a new plausible video starting from an image (e.g., a person's face) and a condition (e.g., an action class label like smile). The key challenge of the cI2V task lies in the simultaneous generation of realistic spatial appearance and temporal dynamics corresponding to the given image and condition. In this paper, we propose an approach for cI2V using novel latent flow diffusion models (LFDM) that synthesize an optical flow sequence in the latent space based on the given condition to warp the given image. Compared to previous direct-synthesis-based works, our proposed LFDM can better synthesize spatial details and temporal motion by fully utilizing the spatial content of the given image and warping it in the latent space according to the generated temporally-coherent flow. The training of LFDM consists of two separate stages: (1) an unsupervised learning stage to train a latent flow auto-encoder for spatial content generation, including a flow predictor to estimate latent flow between pairs of video frames, and (2) a conditional learning stage to train a 3D-UNet-based diffusion model (DM) for temporal latent flow generation. Unlike previous DMs operating in pixel space or latent feature space that couples spatial and temporal information, the DM in our LFDM only needs to learn a low-dimensional latent flow space for motion generation, thus being more computationally efficient. We conduct comprehensive experiments on multiple datasets, where LFDM consistently outperforms prior arts. Furthermore, we show that LFDM can be easily adapted to new domains by simply finetuning the image decoder. Our code is available at https://github.com/nihaomiao/CVPR23_LFDM.
CropDefender: deep watermark which is more convenient to train and more robust against cropping
Sep 12, 2021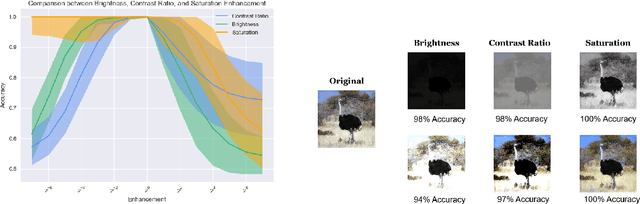
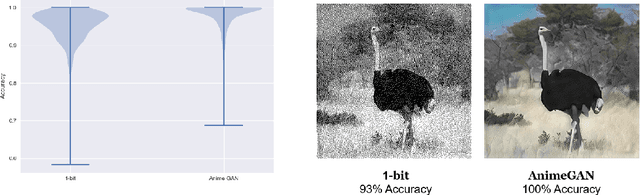

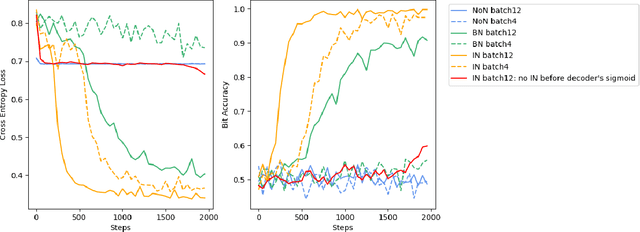
Digital image watermarking, which is a technique for invisibly embedding information into an image, is used in fields such as property rights protection. In recent years, some research has proposed the use of neural networks to add watermarks to natural images. We take StegaStamp as an example for our research. Whether facing traditional image editing methods, such as brightness, contrast, saturation adjustment, or style change like 1-bit conversion, GAN, StegaStamp has robustness far beyond traditional watermarking techniques, but it still has two drawbacks: it is vulnerable to cropping and is hard to train. We found that the causes of vulnerability to cropping is not the loss of information on the edge, but the movement of watermark position. By explicitly introducing the perturbation of cropping into the training, the cropping resistance is significantly improved. For the problem of difficult training, we introduce instance normalization to solve the vanishing gradient, set losses' weights as learnable parameters to reduce the number of hyperparameters, and use sigmoid to restrict pixel values of the generated image.
Online Adversarial Purification based on Self-Supervision
Jan 23, 2021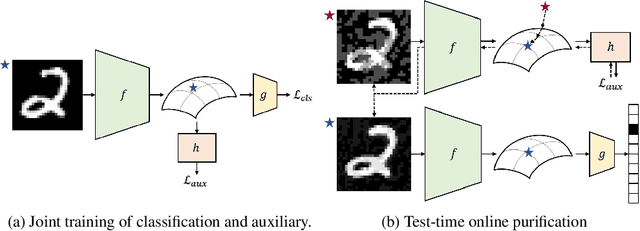
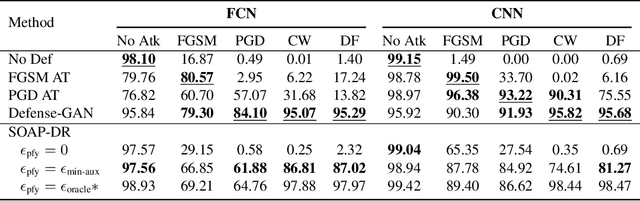

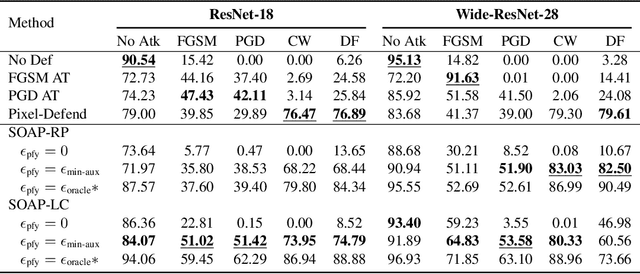
Deep neural networks are known to be vulnerable to adversarial examples, where a perturbation in the input space leads to an amplified shift in the latent network representation. In this paper, we combine canonical supervised learning with self-supervised representation learning, and present Self-supervised Online Adversarial Purification (SOAP), a novel defense strategy that uses a self-supervised loss to purify adversarial examples at test-time. Our approach leverages the label-independent nature of self-supervised signals and counters the adversarial perturbation with respect to the self-supervised tasks. SOAP yields competitive robust accuracy against state-of-the-art adversarial training and purification methods, with considerably less training complexity. In addition, our approach is robust even when adversaries are given knowledge of the purification defense strategy. To the best of our knowledge, our paper is the first that generalizes the idea of using self-supervised signals to perform online test-time purification.