 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Graph-Based Semi-Supervised Learning via $p$-Conductances
Feb 13, 2025We study the problem of semi-supervised learning on graphs in the regime where data labels are scarce or possibly corrupted. We propose an approach called $p$-conductance learning that generalizes the $p$-Laplace and Poisson learning methods by introducing an objective reminiscent of $p$-Laplacian regularization and an affine relaxation of the label constraints. This leads to a family of probability measure mincut programs that balance sparse edge removal with accurate distribution separation. Our theoretical analysis connects these programs to well-known variational and probabilistic problems on graphs (including randomized cuts, effective resistance, and Wasserstein distance) and provides motivation for robustness when labels are diffused via the heat kernel. Computationally, we develop a semismooth Newton-conjugate gradient algorithm and extend it to incorporate class-size estimates when converting the continuous solutions into label assignments. Empirical results on computer vision and citation datasets demonstrate that our approach achieves state-of-the-art accuracy in low label-rate, corrupted-label, and partial-label regimes.
On Robustness and Generalization of ML-Based Congestion Predictors to Valid and Imperceptible Perturbations
Feb 29, 2024
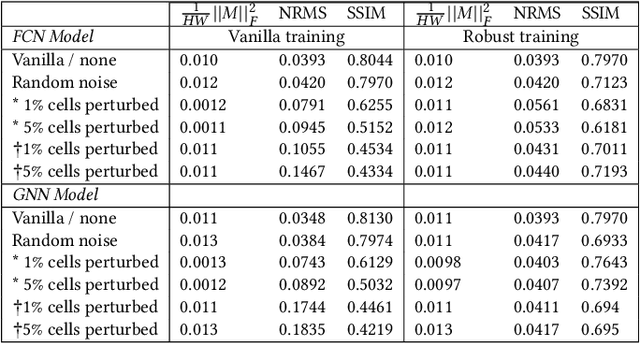


There is substantial interest in the use of machine learning (ML)-based techniques throughout the electronic computer-aided design (CAD) flow, particularly methods based on deep learning. However, while deep learning methods have achieved state-of-the-art performance in several applications, recent work has demonstrated that neural networks are generally vulnerable to small, carefully chosen perturbations of their input (e.g. a single pixel change in an image). In this work, we investigate robustness in the context of ML-based EDA tools -- particularly for congestion prediction. As far as we are aware, we are the first to explore this concept in the context of ML-based EDA. We first describe a novel notion of imperceptibility designed specifically for VLSI layout problems defined on netlists and cell placements. Our definition of imperceptibility is characterized by a guarantee that a perturbation to a layout will not alter its global routing. We then demonstrate that state-of-the-art CNN and GNN-based congestion models exhibit brittleness to imperceptible perturbations. Namely, we show that when a small number of cells (e.g. 1%-5% of cells) have their positions shifted such that a measure of global congestion is guaranteed to remain unaffected (e.g. 1% of the design adversarially shifted by 0.001% of the layout space results in a predicted decrease in congestion of up to 90%, while no change in congestion is implied by the perturbation). In other words, the quality of a predictor can be made arbitrarily poor (i.e. can be made to predict that a design is "congestion-free") for an arbitrary input layout. Next, we describe a simple technique to train predictors that improves robustness to these perturbations. Our work indicates that CAD engineers should be cautious when integrating neural network-based mechanisms in EDA flows to ensure robust and high-quality results.
Semi-Supervised Laplacian Learning on Stiefel Manifolds
Jul 31, 2023Motivated by the need to address the degeneracy of canonical Laplace learning algorithms in low label rates, we propose to reformulate graph-based semi-supervised learning as a nonconvex generalization of a \emph{Trust-Region Subproblem} (TRS). This reformulation is motivated by the well-posedness of Laplacian eigenvectors in the limit of infinite unlabeled data. To solve this problem, we first show that a first-order condition implies the solution of a manifold alignment problem and that solutions to the classical \emph{Orthogonal Procrustes} problem can be used to efficiently find good classifiers that are amenable to further refinement. Next, we address the criticality of selecting supervised samples at low-label rates. We characterize informative samples with a novel measure of centrality derived from the principal eigenvectors of a certain submatrix of the graph Laplacian. We demonstrate that our framework achieves lower classification error compared to recent state-of-the-art and classical semi-supervised learning methods at extremely low, medium, and high label rates. Our code is available on github\footnote{anonymized for submission}.
Evaluating Disentanglement in Generative Models Without Knowledge of Latent Factors
Oct 04, 2022

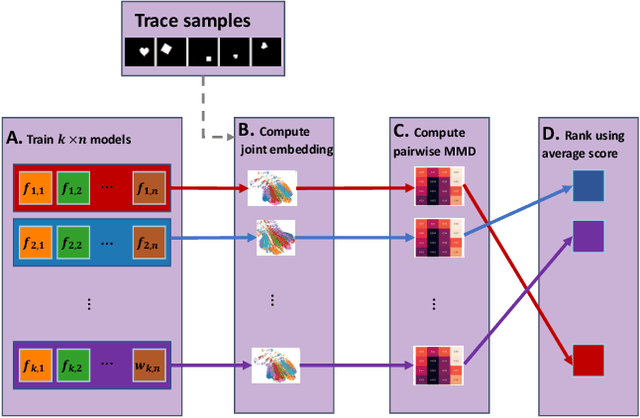

Probabilistic generative models provide a flexible and systematic framework for learning the underlying geometry of data. However, model selection in this setting is challenging, particularly when selecting for ill-defined qualities such as disentanglement or interpretability. In this work, we address this gap by introducing a method for ranking generative models based on the training dynamics exhibited during learning. Inspired by recent theoretical characterizations of disentanglement, our method does not require supervision of the underlying latent factors. We evaluate our approach by demonstrating the need for disentanglement metrics which do not require labels\textemdash the underlying generative factors. We additionally demonstrate that our approach correlates with baseline supervised methods for evaluating disentanglement. Finally, we show that our method can be used as an unsupervised indicator for downstream performance on reinforcement learning and fairness-classification problems.
Online Adversarial Purification based on Self-Supervision
Jan 23, 2021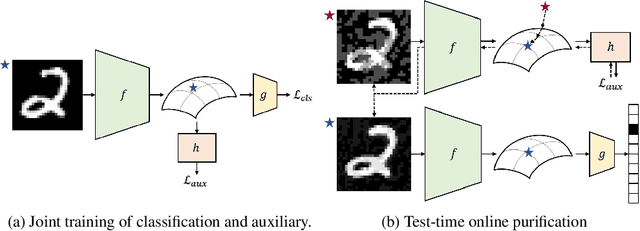
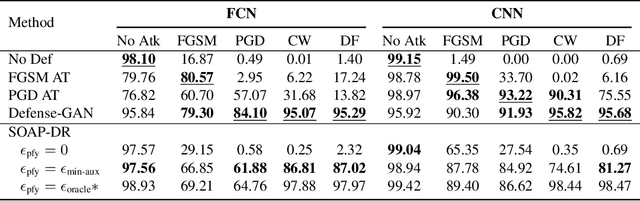

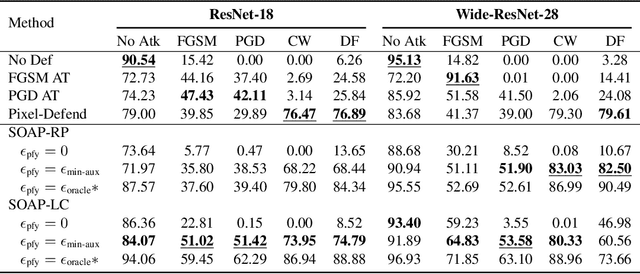
Deep neural networks are known to be vulnerable to adversarial examples, where a perturbation in the input space leads to an amplified shift in the latent network representation. In this paper, we combine canonical supervised learning with self-supervised representation learning, and present Self-supervised Online Adversarial Purification (SOAP), a novel defense strategy that uses a self-supervised loss to purify adversarial examples at test-time. Our approach leverages the label-independent nature of self-supervised signals and counters the adversarial perturbation with respect to the self-supervised tasks. SOAP yields competitive robust accuracy against state-of-the-art adversarial training and purification methods, with considerably less training complexity. In addition, our approach is robust even when adversaries are given knowledge of the purification defense strategy. To the best of our knowledge, our paper is the first that generalizes the idea of using self-supervised signals to perform online test-time purification.