 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning Client Pruning for Noisy Labels
Nov 11, 2024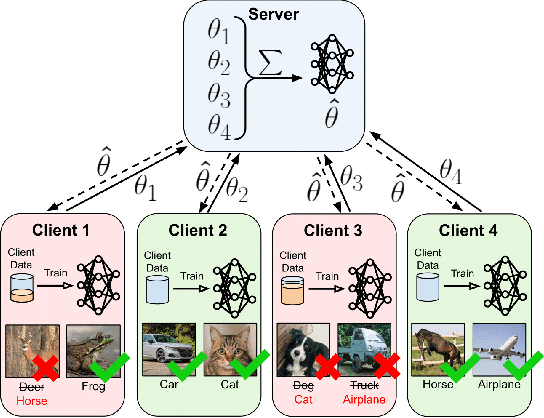
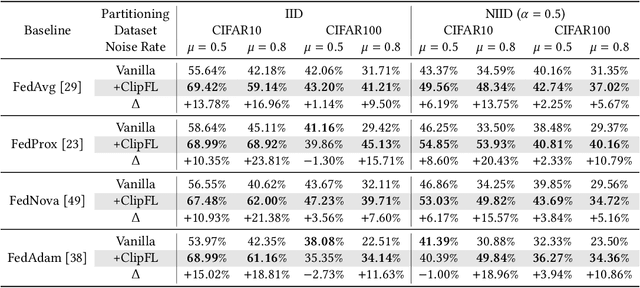
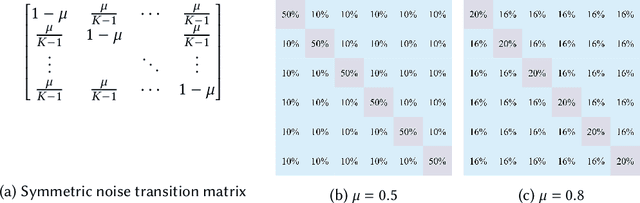

Federated Learning (FL) enables collaborative model training across decentralized edge devices while preserving data privacy. However, existing FL methods often assume clean annotated datasets, impractical for resource-constrained edge devices. In reality, noisy labels are prevalent, posing significant challenges to FL performance. Prior approaches attempt label correction and robust training techniques but exhibit limited efficacy, particularly under high noise levels. This paper introduces ClipFL (Federated Learning Client Pruning), a novel framework addressing noisy labels from a fresh perspective. ClipFL identifies and excludes noisy clients based on their performance on a clean validation dataset, tracked using a Noise Candidacy Score (NCS). The framework comprises three phases: pre-client pruning to identify potential noisy clients and calculate their NCS, client pruning to exclude a percentage of clients with the highest NCS, and post-client pruning for fine-tuning the global model with standard FL on clean clients. Empirical evaluation demonstrates ClipFL's efficacy across diverse datasets and noise levels, achieving accurate noisy client identification, superior performance, faster convergence, and reduced communication costs compared to state-of-the-art FL methods. Our code is available at https://github.com/MMorafah/ClipFL.
Towards Diverse Device Heterogeneous Federated Learning via Task Arithmetic Knowledge Integration
Sep 27, 2024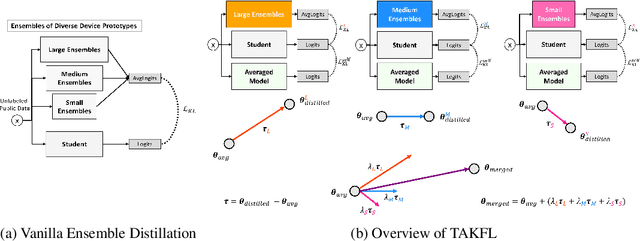



Federated Learning has emerged as a promising paradigm for collaborative machine learning, while preserving user data privacy. Despite its potential, standard FL lacks support for diverse heterogeneous device prototypes, which vary significantly in model and dataset sizes -- from small IoT devices to large workstations. This limitation is only partially addressed by existing knowledge distillation techniques, which often fail to transfer knowledge effectively across a broad spectrum of device prototypes with varied capabilities. This failure primarily stems from two issues: the dilution of informative logits from more capable devices by those from less capable ones, and the use of a single integrated logits as the distillation target across all devices, which neglects their individual learning capacities and and the unique contributions of each. To address these challenges, we introduce TAKFL, a novel KD-based framework that treats the knowledge transfer from each device prototype's ensemble as a separate task, independently distilling each to preserve its unique contributions and avoid dilution. TAKFL also incorporates a KD-based self-regularization technique to mitigate the issues related to the noisy and unsupervised ensemble distillation process. To integrate the separately distilled knowledge, we introduce an adaptive task arithmetic knowledge integration process, allowing each student model to customize the knowledge integration for optimal performance. Additionally, we present theoretical results demonstrating the effectiveness of task arithmetic in transferring knowledge across heterogeneous devices with varying capacities. Comprehensive evaluations of our method across both CV and NLP tasks demonstrate that TAKFL achieves SOTA results in a variety of datasets and settings, significantly outperforming existing KD-based methods. Code is released at https://github.com/MMorafah/TAKFL
MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series
May 29, 2024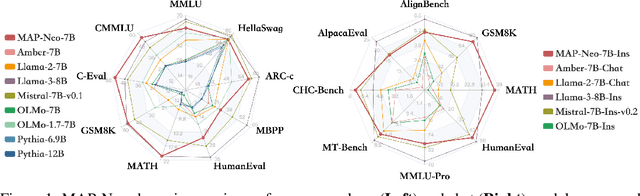

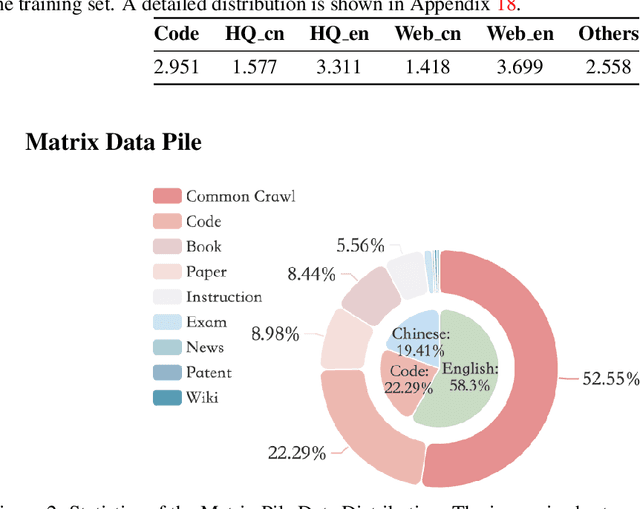
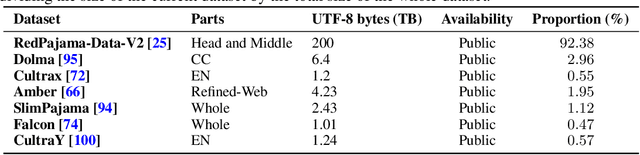
Large Language Models (LLMs) have made great strides in recent years to achieve unprecedented performance across different tasks. However, due to commercial interest, the most competitive models like GPT, Gemini, and Claude have been gated behind proprietary interfaces without disclosing the training details. Recently, many institutions have open-sourced several strong LLMs like LLaMA-3, comparable to existing closed-source LLMs. However, only the model's weights are provided with most details (e.g., intermediate checkpoints, pre-training corpus, and training code, etc.) being undisclosed. To improve the transparency of LLMs, the research community has formed to open-source truly open LLMs (e.g., Pythia, Amber, OLMo), where more details (e.g., pre-training corpus and training code) are being provided. These models have greatly advanced the scientific study of these large models including their strengths, weaknesses, biases and risks. However, we observe that the existing truly open LLMs on reasoning, knowledge, and coding tasks are still inferior to existing state-of-the-art LLMs with similar model sizes. To this end, we open-source MAP-Neo, a highly capable and transparent bilingual language model with 7B parameters trained from scratch on 4.5T high-quality tokens. Our MAP-Neo is the first fully open-sourced bilingual LLM with comparable performance compared to existing state-of-the-art LLMs. Moreover, we open-source all details to reproduce our MAP-Neo, where the cleaned pre-training corpus, data cleaning pipeline, checkpoints, and well-optimized training/evaluation framework are provided. Finally, we hope our MAP-Neo will enhance and strengthen the open research community and inspire more innovations and creativities to facilitate the further improvements of LLMs.
Stable Diffusion-based Data Augmentation for Federated Learning with Non-IID Data
May 13, 2024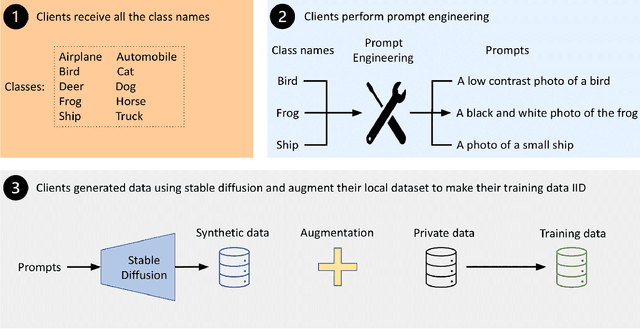

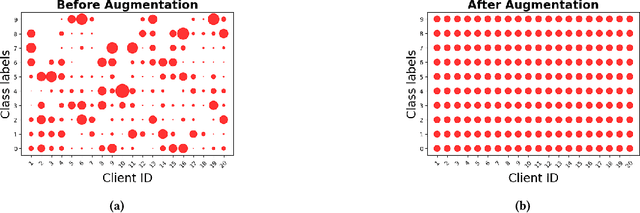

The proliferation of edge devices has brought Federated Learning (FL) to the forefront as a promising paradigm for decentralized and collaborative model training while preserving the privacy of clients' data. However, FL struggles with a significant performance reduction and poor convergence when confronted with Non-Independent and Identically Distributed (Non-IID) data distributions among participating clients. While previous efforts, such as client drift mitigation and advanced server-side model fusion techniques, have shown some success in addressing this challenge, they often overlook the root cause of the performance reduction - the absence of identical data accurately mirroring the global data distribution among clients. In this paper, we introduce Gen-FedSD, a novel approach that harnesses the powerful capability of state-of-the-art text-to-image foundation models to bridge the significant Non-IID performance gaps in FL. In Gen-FedSD, each client constructs textual prompts for each class label and leverages an off-the-shelf state-of-the-art pre-trained Stable Diffusion model to synthesize high-quality data samples. The generated synthetic data is tailored to each client's unique local data gaps and distribution disparities, effectively making the final augmented local data IID. Through extensive experimentation, we demonstrate that Gen-FedSD achieves state-of-the-art performance and significant communication cost savings across various datasets and Non-IID settings.
On Robustness and Generalization of ML-Based Congestion Predictors to Valid and Imperceptible Perturbations
Feb 29, 2024
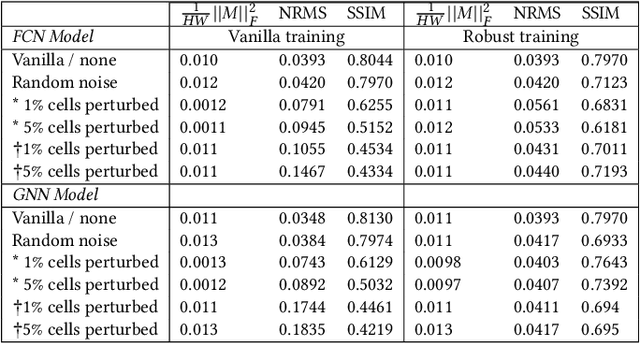


There is substantial interest in the use of machine learning (ML)-based techniques throughout the electronic computer-aided design (CAD) flow, particularly methods based on deep learning. However, while deep learning methods have achieved state-of-the-art performance in several applications, recent work has demonstrated that neural networks are generally vulnerable to small, carefully chosen perturbations of their input (e.g. a single pixel change in an image). In this work, we investigate robustness in the context of ML-based EDA tools -- particularly for congestion prediction. As far as we are aware, we are the first to explore this concept in the context of ML-based EDA. We first describe a novel notion of imperceptibility designed specifically for VLSI layout problems defined on netlists and cell placements. Our definition of imperceptibility is characterized by a guarantee that a perturbation to a layout will not alter its global routing. We then demonstrate that state-of-the-art CNN and GNN-based congestion models exhibit brittleness to imperceptible perturbations. Namely, we show that when a small number of cells (e.g. 1%-5% of cells) have their positions shifted such that a measure of global congestion is guaranteed to remain unaffected (e.g. 1% of the design adversarially shifted by 0.001% of the layout space results in a predicted decrease in congestion of up to 90%, while no change in congestion is implied by the perturbation). In other words, the quality of a predictor can be made arbitrarily poor (i.e. can be made to predict that a design is "congestion-free") for an arbitrary input layout. Next, we describe a simple technique to train predictors that improves robustness to these perturbations. Our work indicates that CAD engineers should be cautious when integrating neural network-based mechanisms in EDA flows to ensure robust and high-quality results.
Monolithic Silicon-Photonics Linear-Algebra Accelerators Enabling Next-Gen Massive MIMO
Feb 13, 2024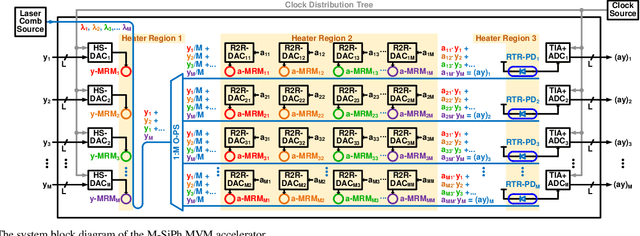
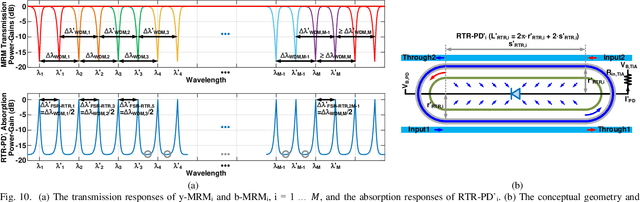
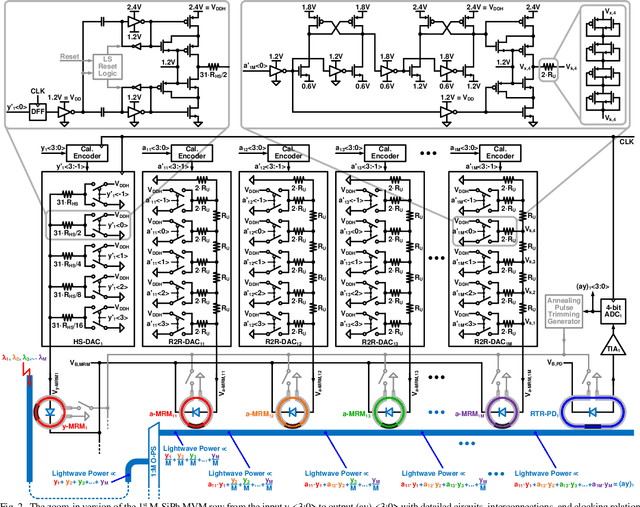
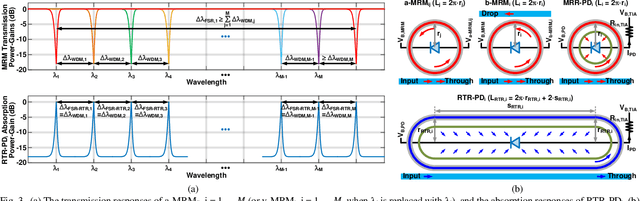
A system-on-chip (SoC) photonic-electronic linear-algebra accelerator with the features of wavelength-division-multiplexing (WDM) based broadband photodetections and high-dimensional matrix-inversion operations fabricated in advanced monolithic silicon-photonics (M-SiPh) semiconductor process technology is proposed to achieve substantial leaps in computation density and energy efficiency, including realistic considerations of energy/area overhead due to electronic/photonic on-chip conversions, integrations, and calibrations through holistic co-design methodologies to support linear-detection based massive multiple-input multiple-output (MIMO) decoding technology requiring the inversion of channel matrices and other emergent applications limited by linear-algebra computation capacities.
A Practical Recipe for Federated Learning Under Statistical Heterogeneity Experimental Design
Jul 28, 2023


Federated Learning (FL) has been an area of active research in recent years. There have been numerous studies in FL to make it more successful in the presence of data heterogeneity. However, despite the existence of many publications, the state of progress in the field is unknown. Many of the works use inconsistent experimental settings and there are no comprehensive studies on the effect of FL-specific experimental variables on the results and practical insights for a more comparable and consistent FL experimental setup. Furthermore, the existence of several benchmarks and confounding variables has further complicated the issue of inconsistency and ambiguity. In this work, we present the first comprehensive study on the effect of FL-specific experimental variables in relation to each other and performance results, bringing several insights and recommendations for designing a meaningful and well-incentivized FL experimental setup. We further aid the community by releasing FedZoo-Bench, an open-source library based on PyTorch with pre-implementation of 22 state-of-the-art methods, and a broad set of standardized and customizable features available at https://github.com/MMorafah/FedZoo-Bench. We also provide a comprehensive comparison of several state-of-the-art (SOTA) methods to better understand the current state of the field and existing limitations.
When Do Curricula Work in Federated Learning?
Dec 24, 2022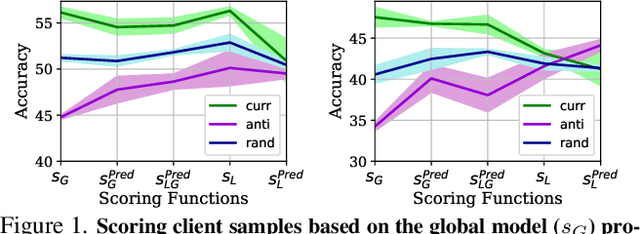

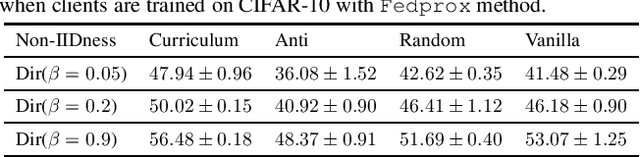
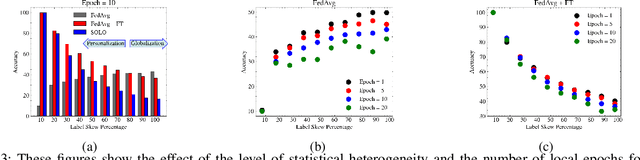
An oft-cited open problem of federated learning is the existence of data heterogeneity at the clients. One pathway to understanding the drastic accuracy drop in federated learning is by scrutinizing the behavior of the clients' deep models on data with different levels of "difficulty", which has been left unaddressed. In this paper, we investigate a different and rarely studied dimension of FL: ordered learning. Specifically, we aim to investigate how ordered learning principles can contribute to alleviating the heterogeneity effects in FL. We present theoretical analysis and conduct extensive empirical studies on the efficacy of orderings spanning three kinds of learning: curriculum, anti-curriculum, and random curriculum. We find that curriculum learning largely alleviates non-IIDness. Interestingly, the more disparate the data distributions across clients the more they benefit from ordered learning. We provide analysis explaining this phenomenon, specifically indicating how curriculum training appears to make the objective landscape progressively less convex, suggesting fast converging iterations at the beginning of the training procedure. We derive quantitative results of convergence for both convex and nonconvex objectives by modeling the curriculum training on federated devices as local SGD with locally biased stochastic gradients. Also, inspired by ordered learning, we propose a novel client selection technique that benefits from the real-world disparity in the clients. Our proposed approach to client selection has a synergic effect when applied together with ordered learning in FL.
Neural Routing in Meta Learning
Oct 14, 2022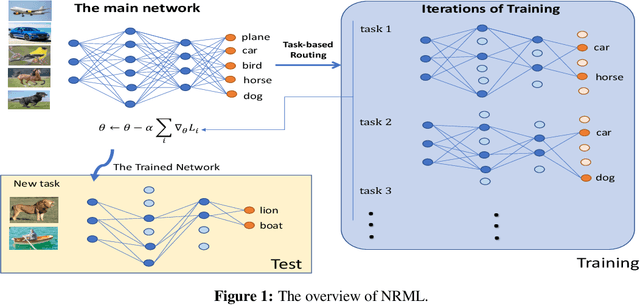

Meta-learning often referred to as learning-to-learn is a promising notion raised to mimic human learning by exploiting the knowledge of prior tasks but being able to adapt quickly to novel tasks. A plethora of models has emerged in this context and improved the learning efficiency, robustness, etc. The question that arises here is can we emulate other aspects of human learning and incorporate them into the existing meta learning algorithms? Inspired by the widely recognized finding in neuroscience that distinct parts of the brain are highly specialized for different types of tasks, we aim to improve the model performance of the current meta learning algorithms by selectively using only parts of the model conditioned on the input tasks. In this work, we describe an approach that investigates task-dependent dynamic neuron selection in deep convolutional neural networks (CNNs) by leveraging the scaling factor in the batch normalization (BN) layer associated with each convolutional layer. The problem is intriguing because the idea of helping different parts of the model to learn from different types of tasks may help us train better filters in CNNs, and improve the model generalization performance. We find that the proposed approach, neural routing in meta learning (NRML), outperforms one of the well-known existing meta learning baselines on few-shot classification tasks on the most widely used benchmark datasets.
Rethinking Data Heterogeneity in Federated Learning: Introducing a New Notion and Standard Benchmarks
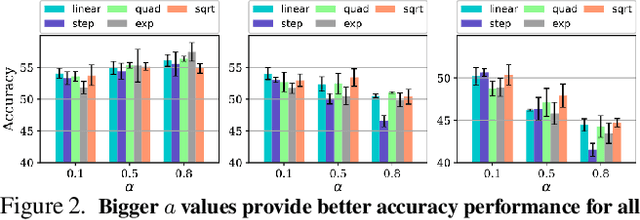
Sep 30, 2022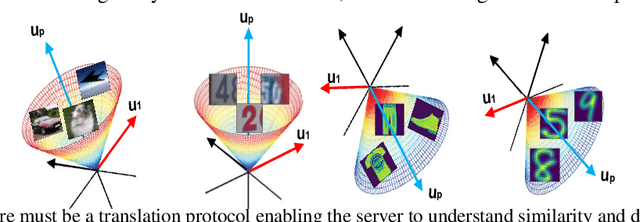


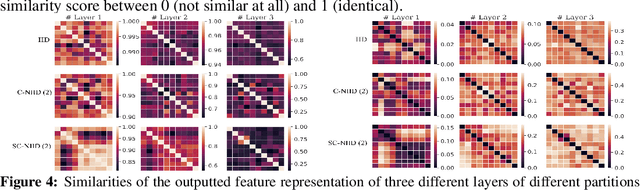
Though successful, federated learning presents new challenges for machine learning, especially when the issue of data heterogeneity, also known as Non-IID data, arises. To cope with the statistical heterogeneity, previous works incorporated a proximal term in local optimization or modified the model aggregation scheme at the server side or advocated clustered federated learning approaches where the central server groups agent population into clusters with jointly trainable data distributions to take the advantage of a certain level of personalization. While effective, they lack a deep elaboration on what kind of data heterogeneity and how the data heterogeneity impacts the accuracy performance of the participating clients. In contrast to many of the prior federated learning approaches, we demonstrate not only the issue of data heterogeneity in current setups is not necessarily a problem but also in fact it can be beneficial for the FL participants. Our observations are intuitive: (1) Dissimilar labels of clients (label skew) are not necessarily considered data heterogeneity, and (2) the principal angle between the agents' data subspaces spanned by their corresponding principal vectors of data is a better estimate of the data heterogeneity. Our code is available at https://github.com/MMorafah/FL-SC-NIID.