 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning Client Pruning for Noisy Labels
Nov 11, 2024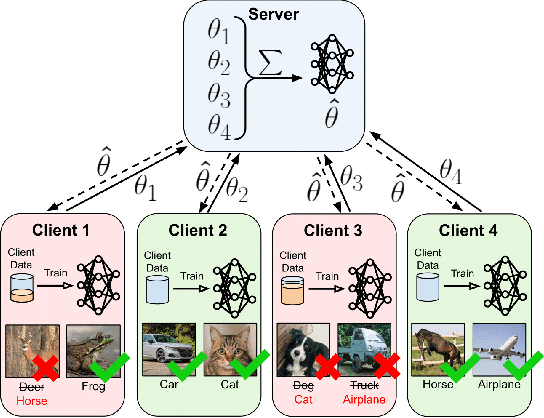
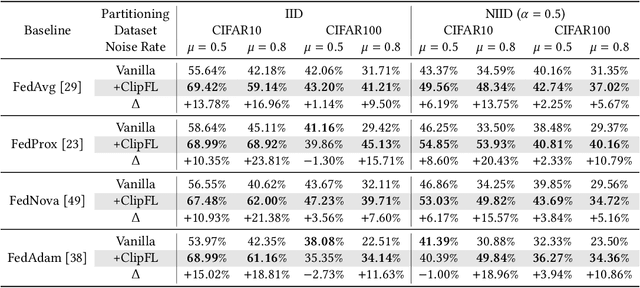
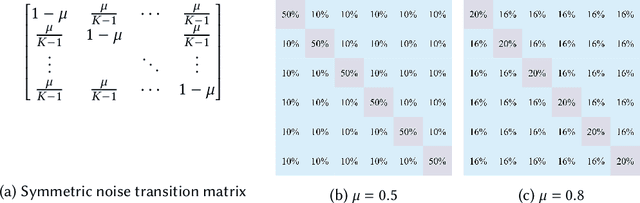

Federated Learning (FL) enables collaborative model training across decentralized edge devices while preserving data privacy. However, existing FL methods often assume clean annotated datasets, impractical for resource-constrained edge devices. In reality, noisy labels are prevalent, posing significant challenges to FL performance. Prior approaches attempt label correction and robust training techniques but exhibit limited efficacy, particularly under high noise levels. This paper introduces ClipFL (Federated Learning Client Pruning), a novel framework addressing noisy labels from a fresh perspective. ClipFL identifies and excludes noisy clients based on their performance on a clean validation dataset, tracked using a Noise Candidacy Score (NCS). The framework comprises three phases: pre-client pruning to identify potential noisy clients and calculate their NCS, client pruning to exclude a percentage of clients with the highest NCS, and post-client pruning for fine-tuning the global model with standard FL on clean clients. Empirical evaluation demonstrates ClipFL's efficacy across diverse datasets and noise levels, achieving accurate noisy client identification, superior performance, faster convergence, and reduced communication costs compared to state-of-the-art FL methods. Our code is available at https://github.com/MMorafah/ClipFL.
Towards Diverse Device Heterogeneous Federated Learning via Task Arithmetic Knowledge Integration
Sep 27, 2024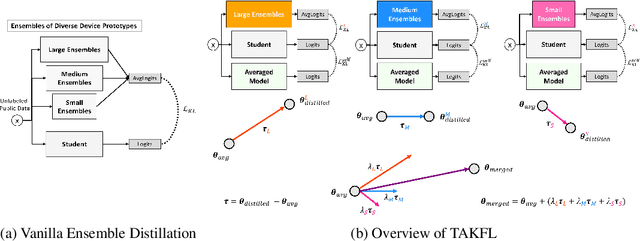



Federated Learning has emerged as a promising paradigm for collaborative machine learning, while preserving user data privacy. Despite its potential, standard FL lacks support for diverse heterogeneous device prototypes, which vary significantly in model and dataset sizes -- from small IoT devices to large workstations. This limitation is only partially addressed by existing knowledge distillation techniques, which often fail to transfer knowledge effectively across a broad spectrum of device prototypes with varied capabilities. This failure primarily stems from two issues: the dilution of informative logits from more capable devices by those from less capable ones, and the use of a single integrated logits as the distillation target across all devices, which neglects their individual learning capacities and and the unique contributions of each. To address these challenges, we introduce TAKFL, a novel KD-based framework that treats the knowledge transfer from each device prototype's ensemble as a separate task, independently distilling each to preserve its unique contributions and avoid dilution. TAKFL also incorporates a KD-based self-regularization technique to mitigate the issues related to the noisy and unsupervised ensemble distillation process. To integrate the separately distilled knowledge, we introduce an adaptive task arithmetic knowledge integration process, allowing each student model to customize the knowledge integration for optimal performance. Additionally, we present theoretical results demonstrating the effectiveness of task arithmetic in transferring knowledge across heterogeneous devices with varying capacities. Comprehensive evaluations of our method across both CV and NLP tasks demonstrate that TAKFL achieves SOTA results in a variety of datasets and settings, significantly outperforming existing KD-based methods. Code is released at https://github.com/MMorafah/TAKFL