 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAVE: Spectral-Shift-Aware Adaptation of Image Diffusion Models for Text-guided Video Editing
May 30, 2023
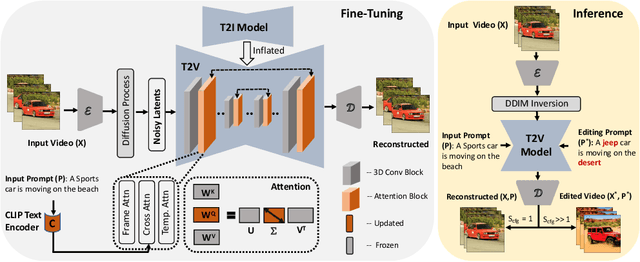

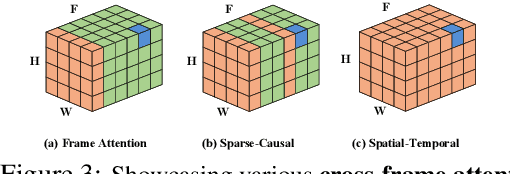
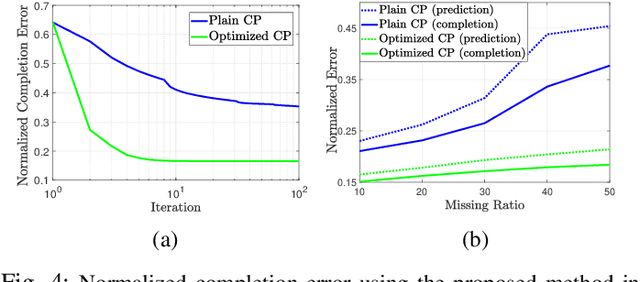
Text-to-Image (T2I) diffusion models have achieved remarkable success in synthesizing high-quality images conditioned on text prompts. Recent methods have tried to replicate the success by either training text-to-video (T2V) models on a very large number of text-video pairs or adapting T2I models on text-video pairs independently. Although the latter is computationally less expensive, it still takes a significant amount of time for per-video adaption. To address this issue, we propose SAVE, a novel spectral-shift-aware adaptation framework, in which we fine-tune the spectral shift of the parameter space instead of the parameters themselves. Specifically, we take the spectral decomposition of the pre-trained T2I weights and only control the change in the corresponding singular values, i.e. spectral shift, while freezing the corresponding singular vectors. To avoid drastic drift from the original T2I weights, we introduce a spectral shift regularizer that confines the spectral shift to be more restricted for large singular values and more relaxed for small singular values. Since we are only dealing with spectral shifts, the proposed method reduces the adaptation time significantly (approx. 10 times) and has fewer resource constrains for training. Such attributes posit SAVE to be more suitable for real-world applications, e.g. editing undesirable content during video streaming. We validate the effectiveness of SAVE with an extensive experimental evaluation under different settings, e.g. style transfer, object replacement, privacy preservation, etc.
Neural Routing in Meta Learning
Oct 14, 2022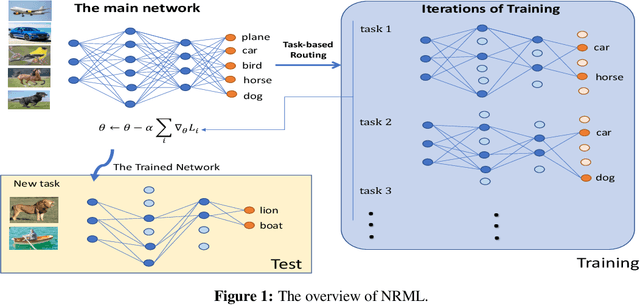

Meta-learning often referred to as learning-to-learn is a promising notion raised to mimic human learning by exploiting the knowledge of prior tasks but being able to adapt quickly to novel tasks. A plethora of models has emerged in this context and improved the learning efficiency, robustness, etc. The question that arises here is can we emulate other aspects of human learning and incorporate them into the existing meta learning algorithms? Inspired by the widely recognized finding in neuroscience that distinct parts of the brain are highly specialized for different types of tasks, we aim to improve the model performance of the current meta learning algorithms by selectively using only parts of the model conditioned on the input tasks. In this work, we describe an approach that investigates task-dependent dynamic neuron selection in deep convolutional neural networks (CNNs) by leveraging the scaling factor in the batch normalization (BN) layer associated with each convolutional layer. The problem is intriguing because the idea of helping different parts of the model to learn from different types of tasks may help us train better filters in CNNs, and improve the model generalization performance. We find that the proposed approach, neural routing in meta learning (NRML), outperforms one of the well-known existing meta learning baselines on few-shot classification tasks on the most widely used benchmark datasets.
Two-way Spectrum Pursuit for CUR Decomposition and Its Application in Joint Column/Row Subset Selection
Jun 13, 2021
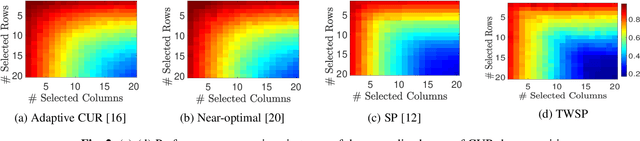
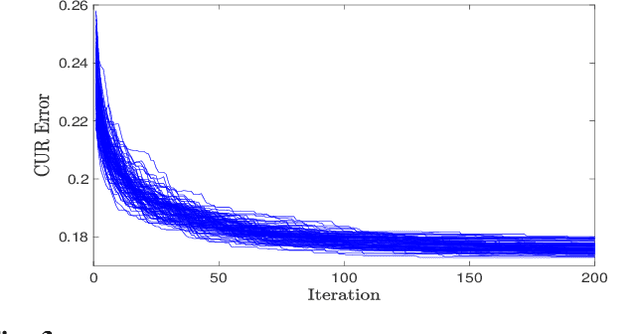
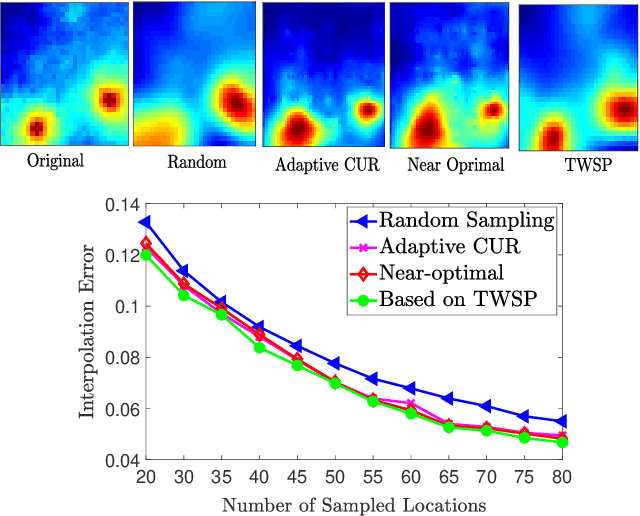
The problem of simultaneous column and row subset selection is addressed in this paper. The column space and row space of a matrix are spanned by its left and right singular vectors, respectively. However, the singular vectors are not within actual columns/rows of the matrix. In this paper, an iterative approach is proposed to capture the most structural information of columns/rows via selecting a subset of actual columns/rows. This algorithm is referred to as two-way spectrum pursuit (TWSP) which provides us with an accurate solution for the CUR matrix decomposition. TWSP is applicable in a wide range of applications since it enjoys a linear complexity w.r.t. number of original columns/rows. We demonstrated the application of TWSP for joint channel and sensor selection in cognitive radio networks, informative users and contents detection, and efficient supervised data reduction.
AI-enabled Blockchain: An Outlier-aware Consensus Protocol for Blockchain-based IoT Networks
Aug 09, 2019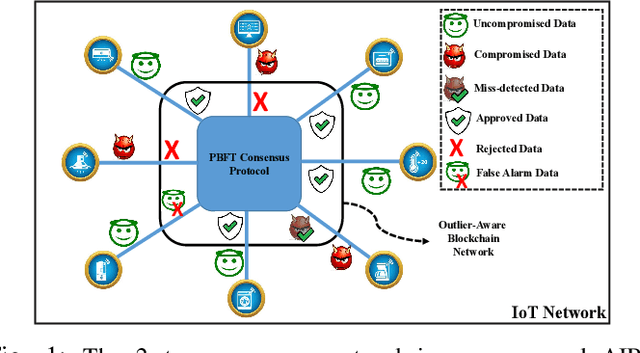
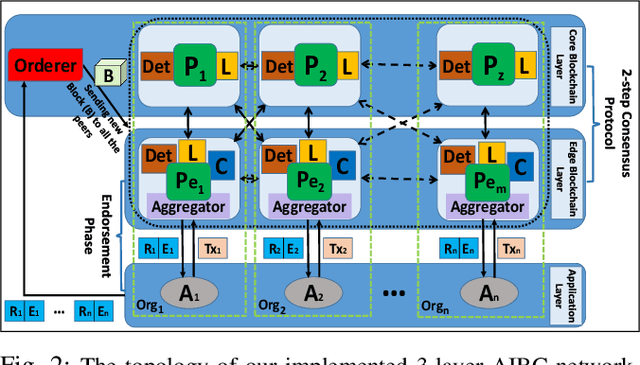
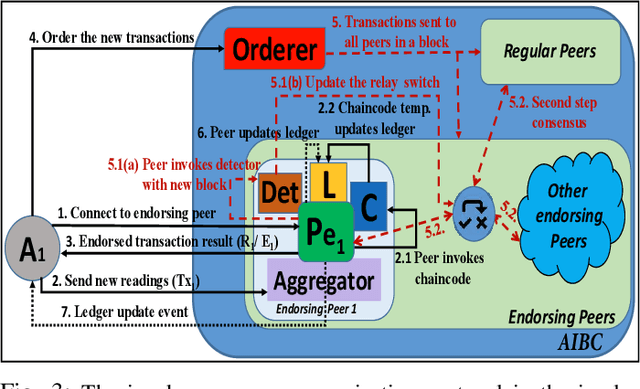
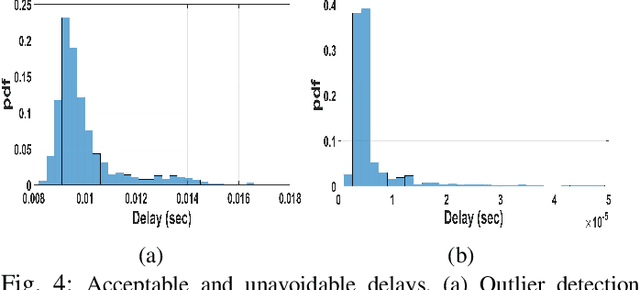
A new framework for a secure and robust consensus in blockchain-based IoT networks is proposed using machine learning. Hyperledger fabric, which is a blockchain platform developed as part of the Hyperledger project, though looks very apt for IoT applications, has comparatively low tolerance for malicious activities in an untrustworthy environment. To that end, we propose AI-enabled blockchain (AIBC) with a 2-step consensus protocol that uses an outlier detection algorithm for consensus in an IoT network implemented on hyperledger fabric platform. The outlier-aware consensus protocol exploits a supervised machine learning algorithm which detects anomaly activities via a learned detector in the first step. Then, the data goes through the inherent Practical Byzantine Fault Tolerance (PBFT) consensus protocol in the hyperledger fabric for ledger update. We measure and report the performance of our framework with respect to the various delay components. Results reveal that our implemented AIBC network (2-step consensus protocol) improves hyperledger fabric performance in terms of fault tolerance by marginally compromising the delay performance.
Large-Scale Spectrum Occupancy Learning via Tensor Decomposition and LSTM Networks
May 10, 2019
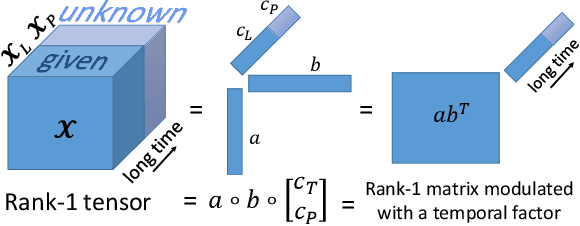
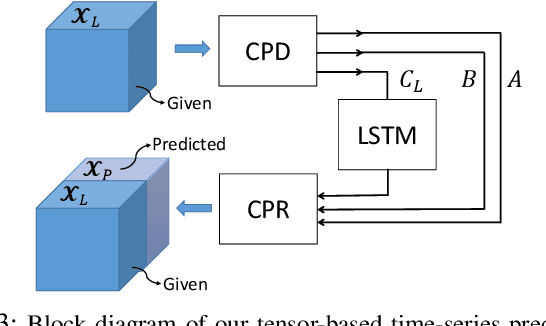
A new paradigm for large-scale spectrum occupancy learning based on long short-term memory (LSTM) recurrent neural networks is proposed. Studies have shown that spectrum usage is a highly correlated time series. Moreover, there is a correlation for occupancy of spectrum between different frequency channels. Therefore, revealing all these correlations using learning and prediction of one-dimensional time series is not a trivial task. In this paper, we introduce a new framework for representing the spectrum measurements in a tensor format. Next, a time-series prediction method based on CANDECOMP/PARFAC (CP) tensor decomposition and LSTM recurrent neural networks is proposed. The proposed method is computationally efficient and is able to capture different types of correlation within the measured spectrum. Moreover, it is robust against noise and missing entries of sensed spectrum. The superiority of the proposed method is evaluated over a large-scale synthetic dataset in terms of prediction accuracy and computational efficiency.
Iterative Projection and Matching: Finding Structure-preserving Representatives and Its Application to Computer Vision
Nov 29, 2018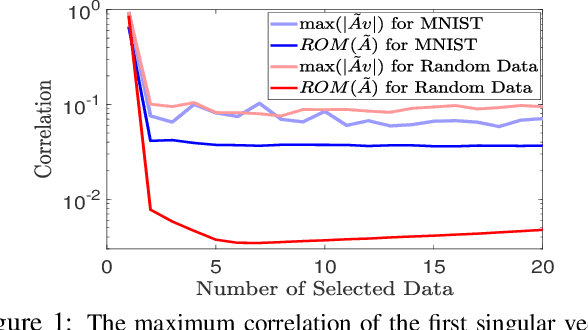
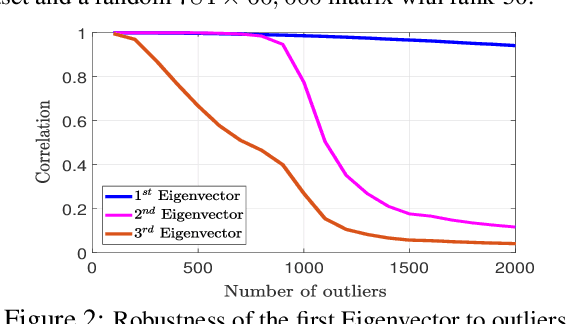

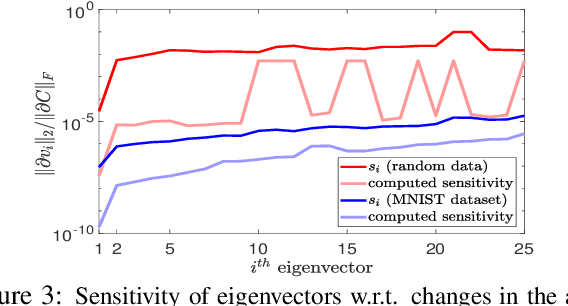
The goal of data selection is to capture the most structural information from a set of data. This paper presents a fast and accurate data selection method, in which the selected samples are optimized to span the subspace of all data. We propose a new selection algorithm, referred to as iterative projection and matching (IPM), with linear complexity w.r.t. the number of data, and without any parameter to be tuned. In our algorithm, at each iteration, the maximum information from the structure of the data is captured by one selected sample, and the captured information is neglected in the next iterations by projection on the null-space of previously selected samples. The computational efficiency and the selection accuracy of our proposed algorithm outperform those of the conventional methods. Furthermore, the superiority of the proposed algorithm is shown on active learning for video action recognition dataset on UCF-101; learning using representatives on ImageNet; training a generative adversarial network (GAN) to generate multi-view images from a single-view input on CMU Multi-PIE dataset; and video summarization on UTE Egocentric dataset.
Joint Dictionary Learning for Example-based Image Super-resolution
Jan 12, 2017
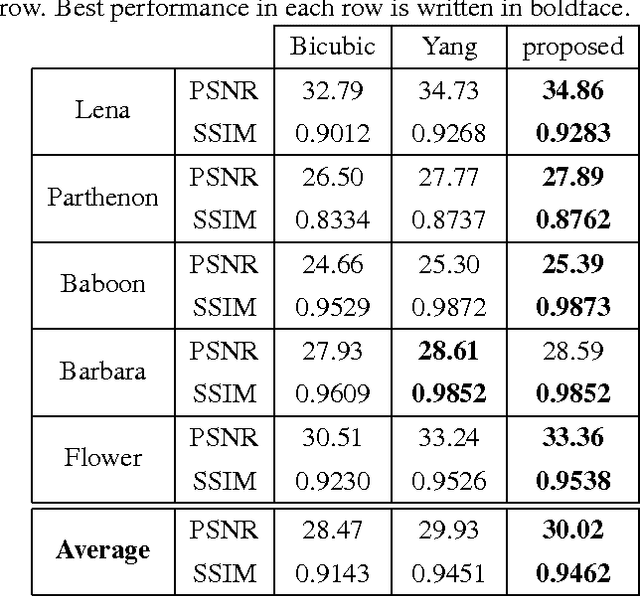
In this paper, we propose a new joint dictionary learning method for example-based image super-resolution (SR), using sparse representation. The low-resolution (LR) dictionary is trained from a set of LR sample image patches. Using the sparse representation coefficients of these LR patches over the LR dictionary, the high-resolution (HR) dictionary is trained by minimizing the reconstruction error of HR sample patches. The error criterion used here is the mean square error. In this way we guarantee that the HR patches have the same sparse representation over HR dictionary as the LR patches over the LR dictionary, and at the same time, these sparse representations can well reconstruct the HR patches. Simulation results show the effectiveness of our method compared to the state-of-art SR algorithms.
Union of Low-Rank Subspaces Detector
Feb 16, 2016
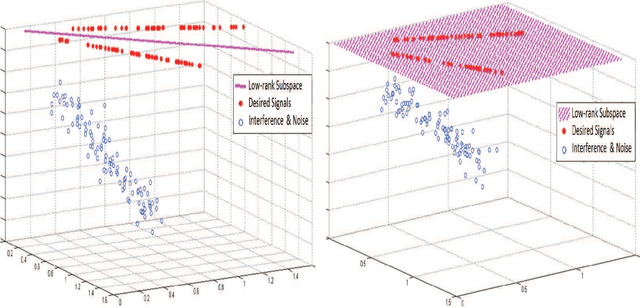
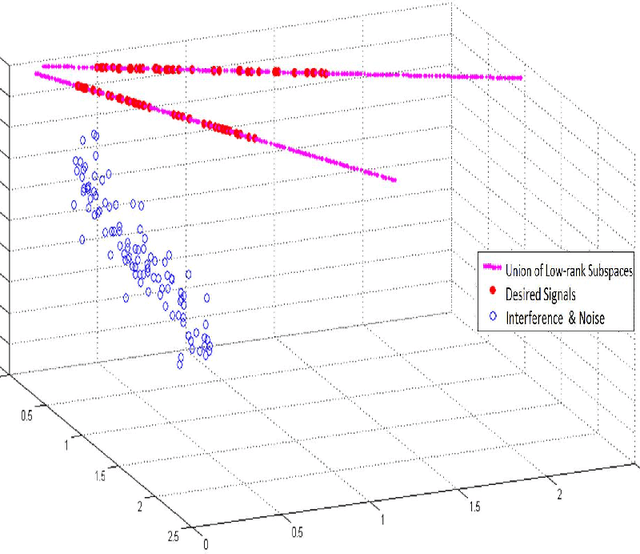

The problem of signal detection using a flexible and general model is considered. Due to applicability and flexibility of sparse signal representation and approximation, it has attracted a lot of attention in many signal processing areas. In this paper, we propose a new detection method based on sparse decomposition in a union of subspaces (UoS) model. Our proposed detector uses a dictionary that can be interpreted as a bank of matched subspaces. This improves the performance of signal detection, as it is a generalization for detectors. Low-rank assumption for the desired signals implies that the representations of these signals in terms of some proper bases would be sparse. Our proposed detector exploits sparsity in its decision rule. We demonstrate the high efficiency of our method in the cases of voice activity detection in speech processing.
Sparse Auto-Regressive: Robust Estimation of AR Parameters
Aug 18, 2015
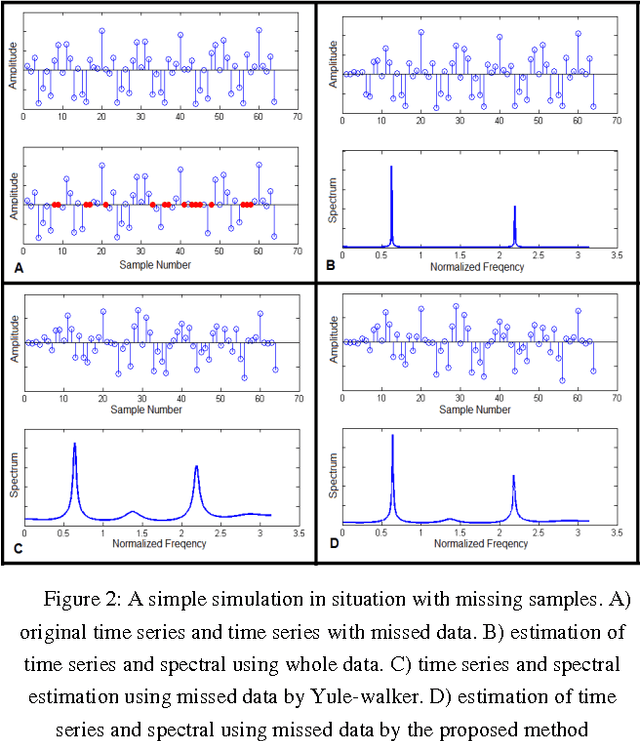


In this paper I present a new approach for regression of time series using their own samples. This is a celebrated problem known as Auto-Regression. Dealing with outlier or missed samples in a time series makes the problem of estimation difficult, so it should be robust against them. Moreover for coding purposes I will show that it is desired the residual of auto-regression be sparse. To these aims, I first assume a multivariate Gaussian prior on the residual and then obtain the estimation. Two simple simulations have been done on spectrum estimation and speech coding.
A Study on Clustering for Clustering Based Image De-Noising
Jan 06, 2015



In this paper, the problem of de-noising of an image contaminated with Additive White Gaussian Noise (AWGN) is studied. This subject is an open problem in signal processing for more than 50 years. Local methods suggested in recent years, have obtained better results than global methods. However by more intelligent training in such a way that first, important data is more effective for training, second, clustering in such way that training blocks lie in low-rank subspaces, we can design a dictionary applicable for image de-noising and obtain results near the state of the art local methods. In the present paper, we suggest a method based on global clustering of image constructing blocks. As the type of clustering plays an important role in clustering-based de-noising methods, we address two questions about the clustering. The first, which parts of the data should be considered for clustering? and the second, what data clustering method is suitable for de-noising.? Then clustering is exploited to learn an over complete dictionary. By obtaining sparse decomposition of the noisy image blocks in terms of the dictionary atoms, the de-noised version is achieved. In addition to our framework, 7 popular dictionary learning methods are simulated and compared. The results are compared based on two major factors: (1) de-noising performance and (2) execution time. Experimental results show that our dictionary learning framework outperforms its competitors in terms of both factors.
* 9 pages, 8 figures, Journal of Information Systems and Telecommunications (JIST)