 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic MRI Reconstruction Via Dual Deep Priors and Low-Rank Plus Sparse Modeling
May 18, 2026Dynamic MRI reconstruction from undersampled measurements is a challenging inverse problem that requires preserving both spatial reconstruction quality and temporal consistency across the frames of the cine series. While recent learning-based approaches achieve strong performance, they heavily rely on large training, mostly fully sampled, datasets, and may otherwise generalize poorly. In contrast, training-data-free methods such as deep image prior (DIP) adapt directly to individual scans but often fail to fully exploit temporal structure and are prone to overfitting. They are particularly attractive for dynamic MRI due to the limited large, public, high-quality datasets. In this work, we propose a structured DIP framework for dynamic MRI reconstruction that explicitly models spatiotemporal correlations through a low-rank plus sparse (L+S) decomposition. Instead of directly reconstructing the cine image series, we parameterize the low-rank background and sparse dynamic components using two DIP untrained convolutional neural networks, jointly optimized using accelerated extrapolated ADMM (eADMM). This formulation combines the implicit regularization of DIP with the interpretability of classical L+S regularization. We provide a convergence analysis for the proposed eADMM algorithm in the presence of DIP-based nonconvex parameterizations. In particular, we establish a sufficient descent property and show that every cluster point of the generated sequence is a critical point of the associated Lyapunov function. Across various acceleration factors, our numerical results demonstrate that the proposed method consistently outperforms classical reconstruction and existing supervised and unsupervised MRI reconstruction techniques.
ForcingDAS: Unified and Robust Data Assimilation via Diffusion Forcing
May 14, 2026Data assimilation (DA) estimates the state of an evolving dynamical system from noisy, partial observations, and is widely used in scientific simulation as well as weather and climate science. In practice, filtering methods rely on frame-to-frame transition models. However, these models are fragile when observations are non-Markovian (when they form only a partial slice of a higher-dimensional latent state as in real-world weather data): they tend to accumulate errors over long horizons. At the same time, learned DA methods typically commit to a single regime, either filtering (nowcasting, real-time forecasting) or smoothing (retrospective reanalysis), which splits what should be a shared prior across application-specific pipelines. To address both issues, we introduce ForcingDAS, a unified and robust DA framework. Built on Diffusion Forcing with an independent noise level assigned to each frame, ForcingDAS learns a joint-trajectory prior instead of frame-to-frame transitions. This allows it to capture long-horizon temporal dependencies and reduce error accumulation. In addition, the same trained model spans the full filtering to smoothing spectrum at inference time. Specifically, nowcasting, fixed-lag smoothing, and batch reanalysis are selected through the inference schedule alone, without retraining. We evaluate ForcingDAS on 2D Navier-Stokes vorticity, precipitation nowcasting, and global atmospheric state estimation. Across all settings, a single model is competitive with or outperforms both learned and classical baselines that are specialized for individual regimes, with the largest gains observed on real-world weather benchmarks.
GaloisSAT: Differentiable Boolean Satisfiability Solving via Finite Field Algebra
Mar 25, 2026Boolean satisfiability (SAT) problem, the first problem proven to be NP-complete, has become a fundamental challenge in computational complexity, with widespread applications in optimization and verification across many domains. Despite significant algorithmic advances over the past two decades, the performance of SAT solvers has improved at a limited pace. Notably, the 2025 competition winner shows only about a 2X improvement over the 2006 winner in SAT Competition performance after nearly 20 years of effort. This paper introduces GaloisSAT, a novel hybrid GPU-CPU SAT solver that integrates a differentiable SAT solving engine powered by modern machine learning infrastructure on GPUs, followed by a traditional CDCL-based SAT solving stage on CPUs. GaloisSAT is benchmarked against the latest versions of state-of-the-art solvers, Kissat and CaDiCaL, using the SAT Competition 2024 benchmark suite. Results demonstrate substantial improvements in the official SAT Competition metric PAR-2 (penalized average runtime with a timeout of 5,000 seconds and a penalty factor of 2). Specifically, GaloisSAT achieves an 8.41X speedup in the satisfiable category and a 1.29X speedup in the unsatisfiable category compared to the strongest baselines.
NERD: Network-Regularized Diffusion Sampling For 3D Computed Tomography
Nov 18, 2025Numerous diffusion model (DM)-based methods have been proposed for solving inverse imaging problems. Among these, a recent line of work has demonstrated strong performance by formulating sampling as an optimization procedure that enforces measurement consistency, forward diffusion consistency, and both step-wise and backward diffusion consistency. However, these methods have only considered 2D reconstruction tasks and do not directly extend to 3D image reconstruction problems, such as in Computed Tomography (CT). To bridge this gap, we propose NEtwork-Regularized diffusion sampling for 3D CT (NERD) by incorporating an L1 regularization into the optimization objective. This regularizer encourages spatial continuity across adjacent slices, reducing inter-slice artifacts and promoting coherent volumetric reconstructions. Additionally, we introduce two efficient optimization strategies to solve the resulting objective: one based on the Alternating Direction Method of Multipliers (ADMM) and another based on the Primal-Dual Hybrid Gradient (PDHG) method. Experiments on medical 3D CT data demonstrate that our approach achieves either state-of-the-art or highly competitive results.
A Dataless Reinforcement Learning Approach to Rounding Hyperplane Optimization for Max-Cut
May 19, 2025



The Maximum Cut (MaxCut) problem is NP-Complete, and obtaining its optimal solution is NP-hard in the worst case. As a result, heuristic-based algorithms are commonly used, though their design often requires significant domain expertise. More recently, learning-based methods trained on large (un)labeled datasets have been proposed; however, these approaches often struggle with generalizability and scalability. A well-known approximation algorithm for MaxCut is the Goemans-Williamson (GW) algorithm, which relaxes the Quadratic Unconstrained Binary Optimization (QUBO) formulation into a semidefinite program (SDP). The GW algorithm then applies hyperplane rounding by uniformly sampling a random hyperplane to convert the SDP solution into binary node assignments. In this paper, we propose a training-data-free approach based on a non-episodic reinforcement learning formulation, in which an agent learns to select improved rounding hyperplanes that yield better cuts than those produced by the GW algorithm. By optimizing over a Markov Decision Process (MDP), our method consistently achieves better cuts across large-scale graphs with varying densities and degree distributions.
Understanding Untrained Deep Models for Inverse Problems: Algorithms and Theory
Feb 25, 2025


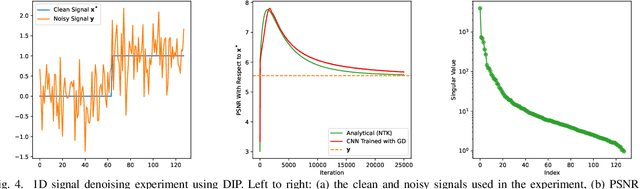
In recent years, deep learning methods have been extensively developed for inverse imaging problems (IIPs), encompassing supervised, self-supervised, and generative approaches. Most of these methods require large amounts of labeled or unlabeled training data to learn effective models. However, in many practical applications, such as medical image reconstruction, extensive training datasets are often unavailable or limited. A significant milestone in addressing this challenge came in 2018 with the work of Ulyanov et al., which introduced the Deep Image Prior (DIP)--the first training-data-free neural network method for IIPs. Unlike conventional deep learning approaches, DIP requires only a convolutional neural network, the noisy measurements, and a forward operator. By leveraging the implicit regularization of deep networks initialized with random noise, DIP can learn and restore image structures without relying on external datasets. However, a well-known limitation of DIP is its susceptibility to overfitting, primarily due to the over-parameterization of the network. In this tutorial paper, we provide a comprehensive review of DIP, including a theoretical analysis of its training dynamics. We also categorize and discuss recent advancements in DIP-based methods aimed at mitigating overfitting, including techniques such as regularization, network re-parameterization, and early stopping. Furthermore, we discuss approaches that combine DIP with pre-trained neural networks, present empirical comparison results against data-centric methods, and highlight open research questions and future directions.
uDiG-DIP: Unrolled Diffusion-Guided Deep Image Prior For Medical Image Reconstruction
Oct 06, 2024Deep learning (DL) methods have been extensively applied to various image recovery problems, including magnetic resonance imaging (MRI) and computed tomography (CT) reconstruction. Beyond supervised models, other approaches have been recently explored including two key recent schemes: Deep Image Prior (DIP) that is an unsupervised scan-adaptive method that leverages the network architecture as implicit regularization but can suffer from noise overfitting, and diffusion models (DMs), where the sampling procedure of a pre-trained generative model is modified to allow sampling from the measurement-conditioned distribution through approximations. In this paper, we propose combining DIP and DMs for MRI and CT reconstruction, motivated by (i) the impact of the DIP network input and (ii) the use of DMs as diffusion purifiers (DPs). Specifically, we propose an unrolled procedure that iteratively optimizes the DIP network with a DM-refined adaptive input using a loss with data consistency and autoencoding terms. We term the approach unrolled Diffusion-Guided DIP (uDiG-DIP). Our experimental results demonstrate that uDiG-DIP achieves superior reconstruction results compared to leading DM-based baselines and the original DIP for MRI and CT tasks.
SITCOM: Step-wise Triple-Consistent Diffusion Sampling for Inverse Problems
Oct 06, 2024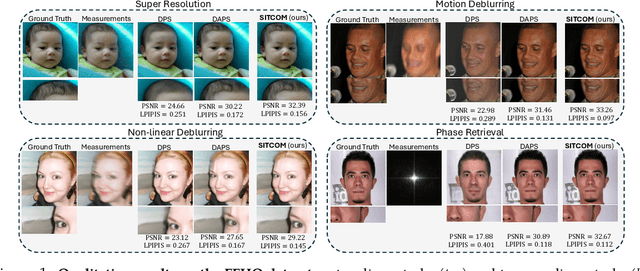
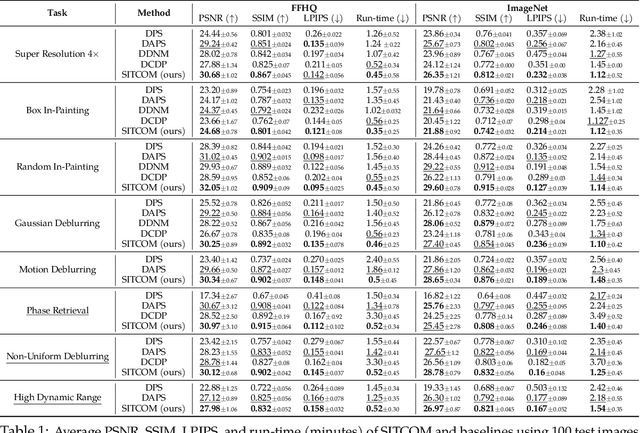

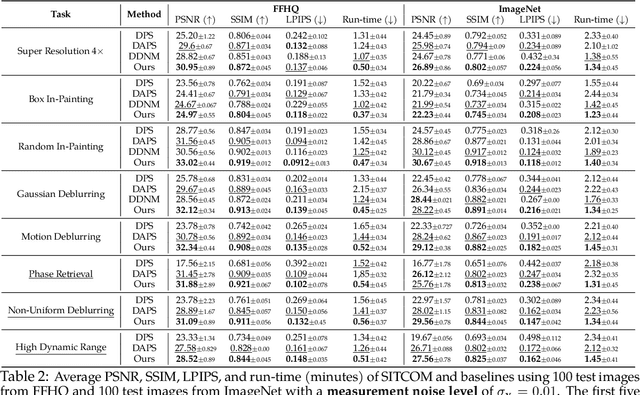
Diffusion models (DMs) are a class of generative models that allow sampling from a distribution learned over a training set. When applied to solving inverse imaging problems (IPs), the reverse sampling steps of DMs are typically modified to approximately sample from a measurement-conditioned distribution in the image space. However, these modifications may be unsuitable for certain settings (such as in the presence of measurement noise) and non-linear tasks, as they often struggle to correct errors from earlier sampling steps and generally require a large number of optimization and/or sampling steps. To address these challenges, we state three conditions for achieving measurement-consistent diffusion trajectories. Building on these conditions, we propose a new optimization-based sampling method that not only enforces the standard data manifold measurement consistency and forward diffusion consistency, as seen in previous studies, but also incorporates backward diffusion consistency that maintains a diffusion trajectory by optimizing over the input of the pre-trained model at every sampling step. By enforcing these conditions, either implicitly or explicitly, our sampler requires significantly fewer reverse steps. Therefore, we refer to our accelerated method as Step-wise Triple-Consistent Sampling (SITCOM). Compared to existing state-of-the-art baseline methods, under different levels of measurement noise, our extensive experiments across five linear and three non-linear image restoration tasks demonstrate that SITCOM achieves competitive or superior results in terms of standard image similarity metrics while requiring a significantly reduced run-time across all considered tasks.
Dataless Quadratic Neural Networks for the Maximum Independent Set Problem
Jun 27, 2024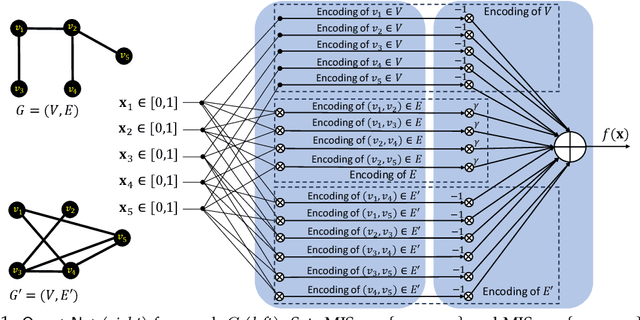



Combinatorial Optimization (CO) plays a crucial role in addressing various significant problems, among them the challenging Maximum Independent Set (MIS) problem. In light of recent advancements in deep learning methods, efforts have been directed towards leveraging data-driven learning approaches, typically rooted in supervised learning and reinforcement learning, to tackle the NP-hard MIS problem. However, these approaches rely on labeled datasets, exhibit weak generalization, and often depend on problem-specific heuristics. Recently, ReLU-based dataless neural networks were introduced to address combinatorial optimization problems. This paper introduces a novel dataless quadratic neural network formulation, featuring a continuous quadratic relaxation for the MIS problem. Notably, our method eliminates the need for training data by treating the given MIS instance as a trainable entity. More specifically, the graph structure and constraints of the MIS instance are used to define the structure and parameters of the neural network such that training it on a fixed input provides a solution to the problem, thereby setting it apart from traditional supervised or reinforcement learning approaches. By employing a gradient-based optimization algorithm like ADAM and leveraging an efficient off-the-shelf GPU parallel implementation, our straightforward yet effective approach demonstrates competitive or superior performance compared to state-of-the-art learning-based methods. Another significant advantage of our approach is that, unlike exact and heuristic solvers, the running time of our method scales only with the number of nodes in the graph, not the number of edges.
Improving Efficiency of Diffusion Models via Multi-Stage Framework and Tailored Multi-Decoder Architectures
Dec 14, 2023



Diffusion models, emerging as powerful deep generative tools, excel in various applications. They operate through a two-steps process: introducing noise into training samples and then employing a model to convert random noise into new samples (e.g., images). However, their remarkable generative performance is hindered by slow training and sampling. This is due to the necessity of tracking extensive forward and reverse diffusion trajectories, and employing a large model with numerous parameters across multiple timesteps (i.e., noise levels). To tackle these challenges, we present a multi-stage framework inspired by our empirical findings. These observations indicate the advantages of employing distinct parameters tailored to each timestep while retaining universal parameters shared across all time steps. Our approach involves segmenting the time interval into multiple stages where we employ custom multi-decoder U-net architecture that blends time-dependent models with a universally shared encoder. Our framework enables the efficient distribution of computational resources and mitigates inter-stage interference, which substantially improves training efficiency. Extensive numerical experiments affirm the effectiveness of our framework, showcasing significant training and sampling efficiency enhancements on three state-of-the-art diffusion models, including large-scale latent diffusion models. Furthermore, our ablation studies illustrate the impact of two important components in our framework: (i) a novel timestep clustering algorithm for stage division, and (ii) an innovative multi-decoder U-net architecture, seamlessly integrating universal and customized hyperparameters.