 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Training Task Diversity on In-Context Learning through the Lens of Low-Dimensional Subspaces
Jun 05, 2026The transformer's emergent ability to perform in-context learning (ICL) has sparked a wide range of studies designed to understand its underlying mechanisms. Existing works often study how training task diversity, defined either as the number of ICL training task vectors or as the number of function classes from which the task vectors are drawn, shapes both the learning dynamics and generalization capabilities of ICL. While both definitions have uncovered many interesting phenomena, many observations under the latter definition remain theoretically unexplained. This paper presents a minimal analytical model under which these phenomena provably emerge from the properties of the training data. By modeling the training task vectors as a mixture of low-rank Gaussians, we show how training task diversity, defined by the number of non-overlapping columns between subspaces that parameterize the covariance matrices, improves both the generalization and optimization trajectory of ICL with linear attention. In particular, we show that our model can explain (i) why training with task diversity shortens the ICL plateau and (ii) why ICL appears to achieve out-of-distribution generalization. We conclude by empirically demonstrating how our results extend to nonlinear transformers and nonlinear function classes. Overall, our work presents a tractable framework to unify existing observations.
Scaling Laws of SignSGD in Linear Regression: When Does It Outperform SGD?
Mar 02, 2026We study scaling laws of signSGD under a power-law random features (PLRF) model that accounts for both feature and target decay. We analyze the population risk of a linear model trained with one-pass signSGD on Gaussian-sketched features. We express the risk as a function of model size, training steps, learning rate, and the feature and target decay parameters. Comparing against the SGD risk analyzed by Paquette et al. (2024), we identify a drift-normalization effect and a noise-reshaping effect unique to signSGD. We then obtain compute-optimal scaling laws under the optimal choice of learning rate. Our analysis shows that the noise-reshaping effect can make the compute-optimal slope of signSGD steeper than that of SGD in regimes where noise is dominant. Finally, we observe that the widely used warmup-stable-decay (WSD) schedule further reduces the noise term and sharpens the compute-optimal slope, when feature decay is fast but target decay is slow.
High-Dimensional Sequential Change Detection
Feb 07, 2025We address the problem of detecting a change in the distribution of a high-dimensional multivariate normal time series. Assuming that the post-change parameters are unknown and estimated using a window of historical data, we extend the framework of quickest change detection (QCD) to the highdimensional setting in which the number of variables increases proportionally with the size of the window used to estimate the post-change parameters. Our analysis reveals that an information theoretic quantity, which we call the Normalized High- Dimensional Kullback-Leibler divergence (NHDKL), governs the high-dimensional asymptotic performance of QCD procedures. Specifically, we show that the detection delay is asymptotically inversely proportional to the difference between the NHDKL of the true post-change versus pre-change distributions and the NHDKL of the true versus estimated post-change distributions. In cases of perfect estimation, where the latter NHDKL is zero, the delay is inversely proportional to the NHDKL between the post-change and pre-change distributions alone. Thus, our analysis is a direct generalization of the traditional fixed-dimension, large-sample asymptotic framework, where the standard KL divergence is asymptotically inversely proportional to detection delay. Finally, we identify parameter estimators that asymptotically minimize the NHDKL between the true versus estimated post-change distributions, resulting in a QCD method that is guaranteed to outperform standard approaches based on fixed-dimension asymptotics.
Improving Efficiency of Diffusion Models via Multi-Stage Framework and Tailored Multi-Decoder Architectures
Dec 14, 2023



Diffusion models, emerging as powerful deep generative tools, excel in various applications. They operate through a two-steps process: introducing noise into training samples and then employing a model to convert random noise into new samples (e.g., images). However, their remarkable generative performance is hindered by slow training and sampling. This is due to the necessity of tracking extensive forward and reverse diffusion trajectories, and employing a large model with numerous parameters across multiple timesteps (i.e., noise levels). To tackle these challenges, we present a multi-stage framework inspired by our empirical findings. These observations indicate the advantages of employing distinct parameters tailored to each timestep while retaining universal parameters shared across all time steps. Our approach involves segmenting the time interval into multiple stages where we employ custom multi-decoder U-net architecture that blends time-dependent models with a universally shared encoder. Our framework enables the efficient distribution of computational resources and mitigates inter-stage interference, which substantially improves training efficiency. Extensive numerical experiments affirm the effectiveness of our framework, showcasing significant training and sampling efficiency enhancements on three state-of-the-art diffusion models, including large-scale latent diffusion models. Furthermore, our ablation studies illustrate the impact of two important components in our framework: (i) a novel timestep clustering algorithm for stage division, and (ii) an innovative multi-decoder U-net architecture, seamlessly integrating universal and customized hyperparameters.
Community Detection in High-Dimensional Graph Ensembles
Dec 06, 2023
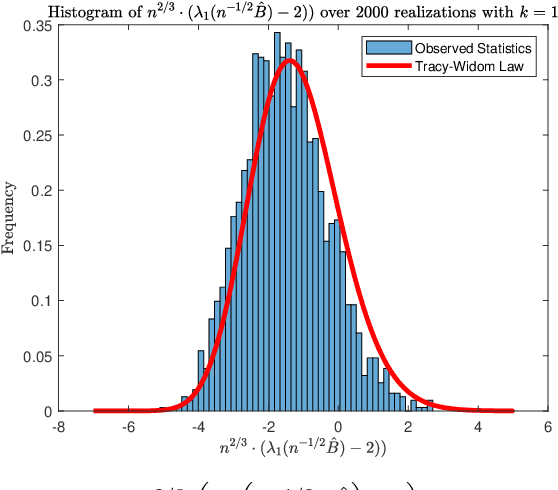

Detecting communities in high-dimensional graphs can be achieved by applying random matrix theory where the adjacency matrix of the graph is modeled by a Stochastic Block Model (SBM). However, the SBM makes an unrealistic assumption that the edge probabilities are homogeneous within communities, i.e., the edges occur with the same probabilities. The Degree-Corrected SBM is a generalization of the SBM that allows these edge probabilities to be different, but existing results from random matrix theory are not directly applicable to this heterogeneous model. In this paper, we derive a transformation of the adjacency matrix that eliminates this heterogeneity and preserves the relevant eigenstructure for community detection. We propose a test based on the extreme eigenvalues of this transformed matrix and (1) provide a method for controlling the significance level, (2) formulate a conjecture that the test achieves power one for all positive significance levels in the limit as the number of nodes approaches infinity, and (3) provide empirical evidence and theory supporting these claims.
Efficient Compression of Overparameterized Deep Models through Low-Dimensional Learning Dynamics
Nov 08, 2023



Overparameterized models have proven to be powerful tools for solving various machine learning tasks. However, overparameterization often leads to a substantial increase in computational and memory costs, which in turn requires extensive resources to train. In this work, we aim to reduce this complexity by studying the learning dynamics of overparameterized deep networks. By extensively studying its learning dynamics, we unveil that the weight matrices of various architectures exhibit a low-dimensional structure. This finding implies that we can compress the networks by reducing the training to a small subspace. We take a step in developing a principled approach for compressing deep networks by studying deep linear models. We demonstrate that the principal components of deep linear models are fitted incrementally but within a small subspace, and use these insights to compress deep linear networks by decreasing the width of its intermediate layers. Remarkably, we observe that with a particular choice of initialization, the compressed network converges faster than the original network, consistently yielding smaller recovery errors throughout all iterations of gradient descent. We substantiate this observation by developing a theory focused on the deep matrix factorization problem, and by conducting empirical evaluations on deep matrix sensing. Finally, we demonstrate how our compressed model can enhance the utility of deep nonlinear models. Overall, we observe that our compression technique accelerates the training process by more than 2x, without compromising model quality.
Algebraic and Statistical Properties of the Ordinary Least Squares Interpolator
Sep 27, 2023
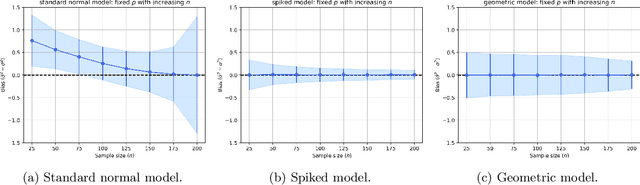

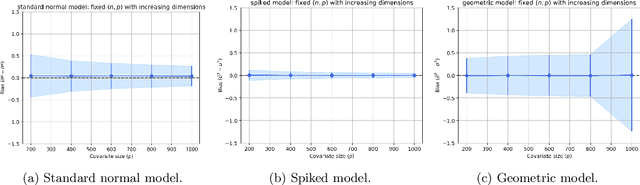
Deep learning research has uncovered the phenomenon of benign overfitting for over-parameterized statistical models, which has drawn significant theoretical interest in recent years. Given its simplicity and practicality, the ordinary least squares (OLS) interpolator has become essential to gain foundational insights into this phenomenon. While properties of OLS are well established in classical settings, its behavior in high-dimensional settings is less explored (unlike for ridge or lasso regression) though significant progress has been made of late. We contribute to this growing literature by providing fundamental algebraic and statistical results for the minimum $\ell_2$-norm OLS interpolator. In particular, we provide high-dimensional algebraic equivalents of (i) the leave-$k$-out residual formula, (ii) Cochran's formula, and (iii) the Frisch-Waugh-Lovell theorem. These results aid in understanding the OLS interpolator's ability to generalize and have substantive implications for causal inference. Additionally, under the Gauss-Markov model, we present statistical results such as a high-dimensional extension of the Gauss-Markov theorem and an analysis of variance estimation under homoskedastic errors. To substantiate our theoretical contributions, we conduct simulation studies that further explore the stochastic properties of the OLS interpolator.
Minimum-Risk Recalibration of Classifiers
May 18, 2023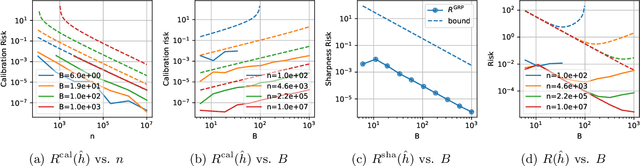

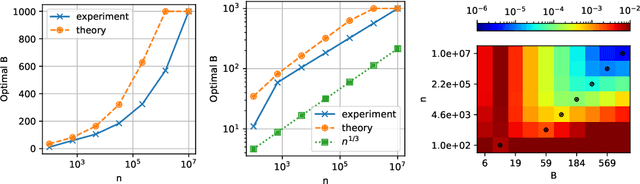
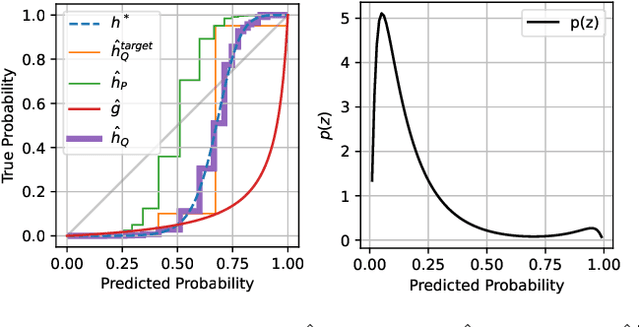
Recalibrating probabilistic classifiers is vital for enhancing the reliability and accuracy of predictive models. Despite the development of numerous recalibration algorithms, there is still a lack of a comprehensive theory that integrates calibration and sharpness (which is essential for maintaining predictive power). In this paper, we introduce the concept of minimum-risk recalibration within the framework of mean-squared-error (MSE) decomposition, offering a principled approach for evaluating and recalibrating probabilistic classifiers. Using this framework, we analyze the uniform-mass binning (UMB) recalibration method and establish a finite-sample risk upper bound of order $\tilde{O}(B/n + 1/B^2)$ where $B$ is the number of bins and $n$ is the sample size. By balancing calibration and sharpness, we further determine that the optimal number of bins for UMB scales with $n^{1/3}$, resulting in a risk bound of approximately $O(n^{-2/3})$. Additionally, we tackle the challenge of label shift by proposing a two-stage approach that adjusts the recalibration function using limited labeled data from the target domain. Our results show that transferring a calibrated classifier requires significantly fewer target samples compared to recalibrating from scratch. We validate our theoretical findings through numerical simulations, which confirm the tightness of the proposed bounds, the optimal number of bins, and the effectiveness of label shift adaptation.
Errors-in-variables Fréchet Regression with Low-rank Covariate Approximation
May 16, 2023


Fr\'echet regression has emerged as a promising approach for regression analysis involving non-Euclidean response variables. However, its practical applicability has been hindered by its reliance on ideal scenarios with abundant and noiseless covariate data. In this paper, we present a novel estimation method that tackles these limitations by leveraging the low-rank structure inherent in the covariate matrix. Our proposed framework combines the concepts of global Fr\'echet regression and principal component regression, aiming to improve the efficiency and accuracy of the regression estimator. By incorporating the low-rank structure, our method enables more effective modeling and estimation, particularly in high-dimensional and errors-in-variables regression settings. We provide a theoretical analysis of the proposed estimator's large-sample properties, including a comprehensive rate analysis of bias, variance, and additional variations due to measurement errors. Furthermore, our numerical experiments provide empirical evidence that supports the theoretical findings, demonstrating the superior performance of our approach. Overall, this work introduces a promising framework for regression analysis of non-Euclidean variables, effectively addressing the challenges associated with limited and noisy covariate data, with potential applications in diverse fields.
Robustness-preserving Lifelong Learning via Dataset Condensation
Mar 07, 2023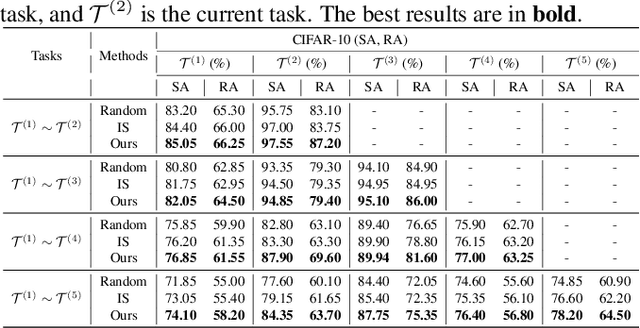
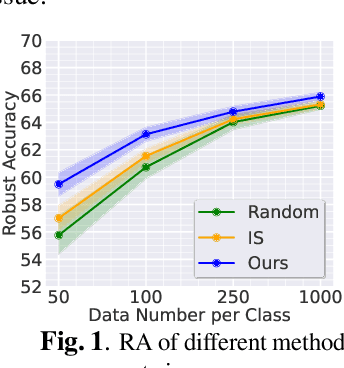
Lifelong learning (LL) aims to improve a predictive model as the data source evolves continuously. Most work in this learning paradigm has focused on resolving the problem of 'catastrophic forgetting,' which refers to a notorious dilemma between improving model accuracy over new data and retaining accuracy over previous data. Yet, it is also known that machine learning (ML) models can be vulnerable in the sense that tiny, adversarial input perturbations can deceive the models into producing erroneous predictions. This motivates the research objective of this paper - specification of a new LL framework that can salvage model robustness (against adversarial attacks) from catastrophic forgetting. Specifically, we propose a new memory-replay LL strategy that leverages modern bi-level optimization techniques to determine the 'coreset' of the current data (i.e., a small amount of data to be memorized) for ease of preserving adversarial robustness over time. We term the resulting LL framework 'Data-Efficient Robustness-Preserving LL' (DERPLL). The effectiveness of DERPLL is evaluated for class-incremental image classification using ResNet-18 over the CIFAR-10 dataset. Experimental results show that DERPLL outperforms the conventional coreset-guided LL baseline and achieves a substantial improvement in both standard accuracy and robust accuracy.