 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-RLHF: Automated Code Evaluation and Socratic Feedback Generation Tool using Large Language Models and Reinforcement Learning with Human Feedback
Apr 07, 2025Automated Program Repair tools are developed for generating feedback and suggesting a repair method for erroneous code. State of the art (SOTA) code repair methods rely on data-driven approaches and often fail to deliver solution for complicated programming questions. To interpret the natural language of unprecedented programming problems, using Large Language Models (LLMs) for code-feedback generation is crucial. LLMs generate more comprehensible feedback than compiler-generated error messages, and Reinforcement Learning with Human Feedback (RLHF) further enhances quality by integrating human-in-the-loop which helps novice students to lean programming from scratch interactively. We are applying RLHF fine-tuning technique for an expected Socratic response such as a question with hint to solve the programming issue. We are proposing code feedback generation tool by fine-tuning LLM with RLHF, Automated Code Evaluation with RLHF (ACE-RLHF), combining two open-source LLM models with two different SOTA optimization techniques. The quality of feedback is evaluated on two benchmark datasets containing basic and competition-level programming questions where the later is proposed by us. We achieved 2-5% higher accuracy than RL-free SOTA techniques using Llama-3-7B-Proximal-policy optimization in automated evaluation and similar or slightly higher accuracy compared to reward model-free RL with AI Feedback (RLAIF). We achieved almost 40% higher accuracy with GPT-3.5 Best-of-n optimization while performing manual evaluation.
Enhanced Penalty-based Bidirectional Reinforcement Learning Algorithms
Apr 04, 2025This research focuses on enhancing reinforcement learning (RL) algorithms by integrating penalty functions to guide agents in avoiding unwanted actions while optimizing rewards. The goal is to improve the learning process by ensuring that agents learn not only suitable actions but also which actions to avoid. Additionally, we reintroduce a bidirectional learning approach that enables agents to learn from both initial and terminal states, thereby improving speed and robustness in complex environments. Our proposed Penalty-Based Bidirectional methodology is tested against Mani skill benchmark environments, demonstrating an optimality improvement of success rate of approximately 4% compared to existing RL implementations. The findings indicate that this integrated strategy enhances policy learning, adaptability, and overall performance in challenging scenarios
DML-RAM: Deep Multimodal Learning Framework for Robotic Arm Manipulation using Pre-trained Models
Apr 04, 2025This paper presents a novel deep learning framework for robotic arm manipulation that integrates multimodal inputs using a late-fusion strategy. Unlike traditional end-to-end or reinforcement learning approaches, our method processes image sequences with pre-trained models and robot state data with machine learning algorithms, fusing their outputs to predict continuous action values for control. Evaluated on BridgeData V2 and Kuka datasets, the best configuration (VGG16 + Random Forest) achieved MSEs of 0.0021 and 0.0028, respectively, demonstrating strong predictive performance and robustness. The framework supports modularity, interpretability, and real-time decision-making, aligning with the goals of adaptive, human-in-the-loop cyber-physical systems.
MORAL: A Multimodal Reinforcement Learning Framework for Decision Making in Autonomous Laboratories
Apr 04, 2025We propose MORAL (a multimodal reinforcement learning framework for decision making in autonomous laboratories) that enhances sequential decision-making in autonomous robotic laboratories through the integration of visual and textual inputs. Using the BridgeData V2 dataset, we generate fine-tuned image captions with a pretrained BLIP-2 vision-language model and combine them with visual features through an early fusion strategy. The fused representations are processed using Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) agents. Experimental results demonstrate that multimodal agents achieve a 20% improvement in task completion rates and significantly outperform visual-only and textual-only baselines after sufficient training. Compared to transformer-based and recurrent multimodal RL models, our approach achieves superior performance in cumulative reward and caption quality metrics (BLEU, METEOR, ROUGE-L). These results highlight the impact of semantically aligned language cues in enhancing agent learning efficiency and generalization. The proposed framework contributes to the advancement of multimodal reinforcement learning and embodied AI systems in dynamic, real-world environments.
NSP: A Neuro-Symbolic Natural Language Navigational Planner
Sep 10, 2024



Path planners that can interpret free-form natural language instructions hold promise to automate a wide range of robotics applications. These planners simplify user interactions and enable intuitive control over complex semi-autonomous systems. While existing symbolic approaches offer guarantees on the correctness and efficiency, they struggle to parse free-form natural language inputs. Conversely, neural approaches based on pre-trained Large Language Models (LLMs) can manage natural language inputs but lack performance guarantees. In this paper, we propose a neuro-symbolic framework for path planning from natural language inputs called NSP. The framework leverages the neural reasoning abilities of LLMs to i) craft symbolic representations of the environment and ii) a symbolic path planning algorithm. Next, a solution to the path planning problem is obtained by executing the algorithm on the environment representation. The framework uses a feedback loop from the symbolic execution environment to the neural generation process to self-correct syntax errors and satisfy execution time constraints. We evaluate our neuro-symbolic approach using a benchmark suite with 1500 path-planning problems. The experimental evaluation shows that our neuro-symbolic approach produces 90.1% valid paths that are on average 19-77% shorter than state-of-the-art neural approaches.
Improving Robustness of Spectrogram Classifiers with Neural Stochastic Differential Equations
Sep 03, 2024Signal analysis and classification is fraught with high levels of noise and perturbation. Computer-vision-based deep learning models applied to spectrograms have proven useful in the field of signal classification and detection; however, these methods aren't designed to handle the low signal-to-noise ratios inherent within non-vision signal processing tasks. While they are powerful, they are currently not the method of choice in the inherently noisy and dynamic critical infrastructure domain, such as smart-grid sensing, anomaly detection, and non-intrusive load monitoring.
Automaton Distillation: Neuro-Symbolic Transfer Learning for Deep Reinforcement Learning
Oct 29, 2023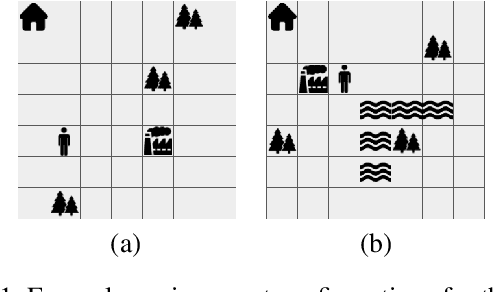
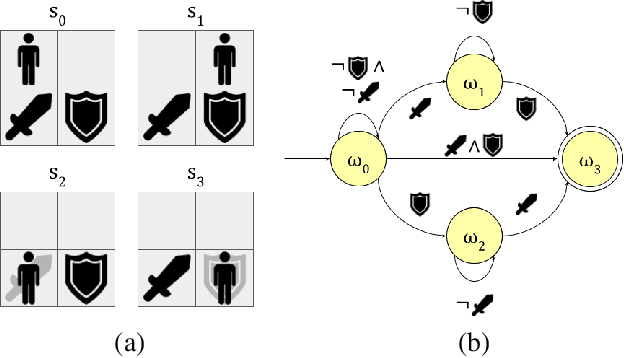
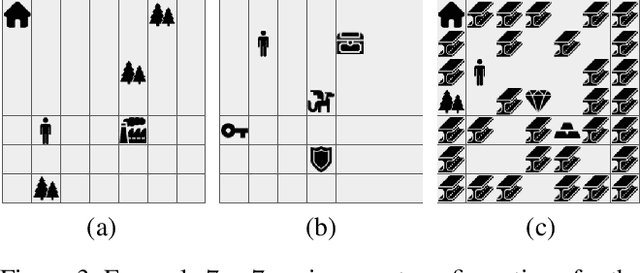
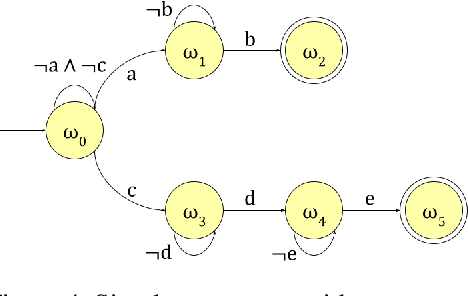
Reinforcement learning (RL) is a powerful tool for finding optimal policies in sequential decision processes. However, deep RL methods suffer from two weaknesses: collecting the amount of agent experience required for practical RL problems is prohibitively expensive, and the learned policies exhibit poor generalization on tasks outside of the training distribution. To mitigate these issues, we introduce automaton distillation, a form of neuro-symbolic transfer learning in which Q-value estimates from a teacher are distilled into a low-dimensional representation in the form of an automaton. We then propose two methods for generating Q-value estimates: static transfer, which reasons over an abstract Markov Decision Process constructed based on prior knowledge, and dynamic transfer, where symbolic information is extracted from a teacher Deep Q-Network (DQN). The resulting Q-value estimates from either method are used to bootstrap learning in the target environment via a modified DQN loss function. We list several failure modes of existing automaton-based transfer methods and demonstrate that both static and dynamic automaton distillation decrease the time required to find optimal policies for various decision tasks.
Integrated Decision Gradients: Compute Your Attributions Where the Model Makes Its Decision
May 31, 2023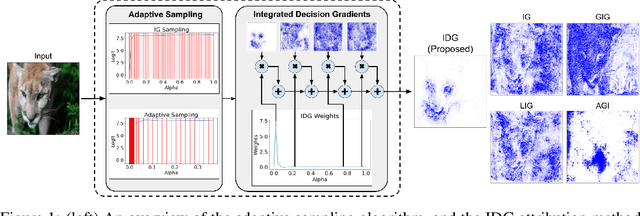
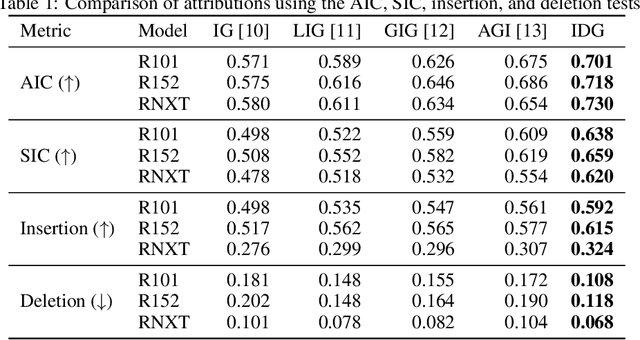
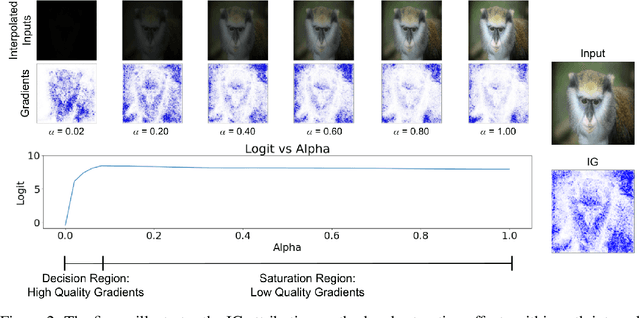

Attribution algorithms are frequently employed to explain the decisions of neural network models. Integrated Gradients (IG) is an influential attribution method due to its strong axiomatic foundation. The algorithm is based on integrating the gradients along a path from a reference image to the input image. Unfortunately, it can be observed that gradients computed from regions where the output logit changes minimally along the path provide poor explanations for the model decision, which is called the saturation effect problem. In this paper, we propose an attribution algorithm called integrated decision gradients (IDG). The algorithm focuses on integrating gradients from the region of the path where the model makes its decision, i.e., the portion of the path where the output logit rapidly transitions from zero to its final value. This is practically realized by scaling each gradient by the derivative of the output logit with respect to the path. The algorithm thereby provides a principled solution to the saturation problem. Additionally, we minimize the errors within the Riemann sum approximation of the path integral by utilizing non-uniform subdivisions determined by adaptive sampling. In the evaluation on ImageNet, it is demonstrated that IDG outperforms IG, left-IG, guided IG, and adversarial gradient integration both qualitatively and quantitatively using standard insertion and deletion metrics across three common models.
On the Robustness of AlphaFold: A COVID-19 Case Study
Jan 12, 2023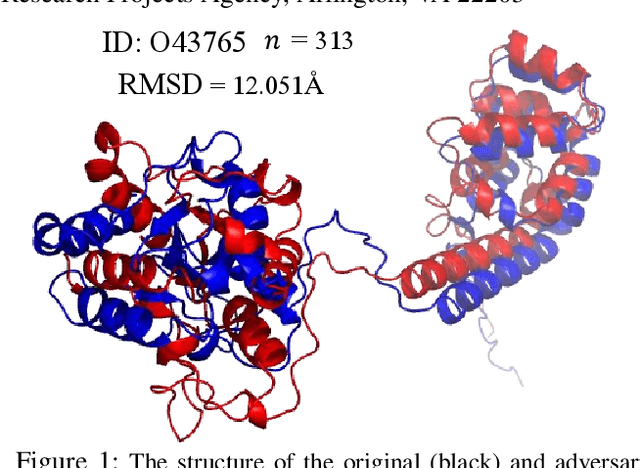
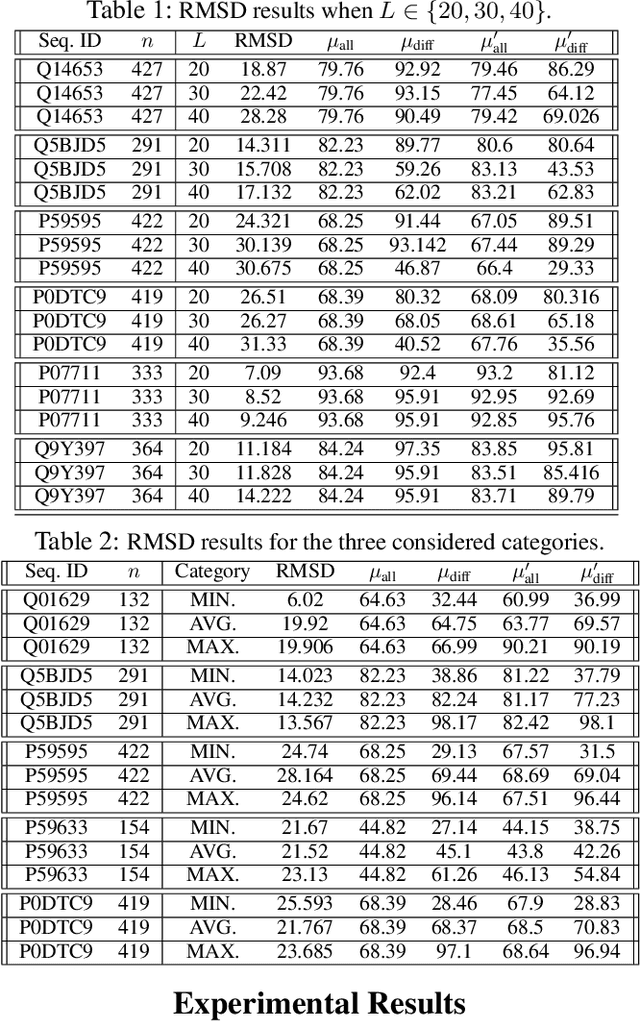
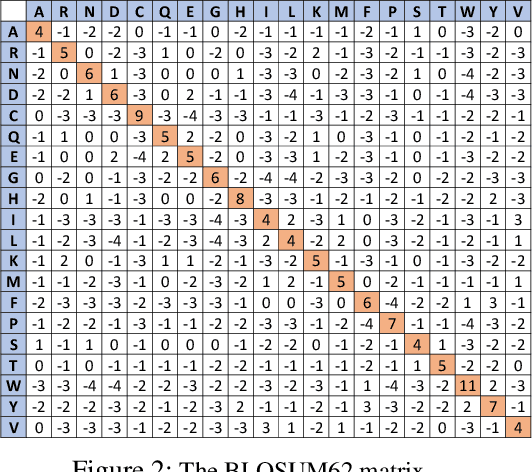

Protein folding neural networks (PFNNs) such as AlphaFold predict remarkably accurate structures of proteins compared to other approaches. However, the robustness of such networks has heretofore not been explored. This is particularly relevant given the broad social implications of such technologies and the fact that biologically small perturbations in the protein sequence do not generally lead to drastic changes in the protein structure. In this paper, we demonstrate that AlphaFold does not exhibit such robustness despite its high accuracy. This raises the challenge of detecting and quantifying the extent to which these predicted protein structures can be trusted. To measure the robustness of the predicted structures, we utilize (i) the root-mean-square deviation (RMSD) and (ii) the Global Distance Test (GDT) similarity measure between the predicted structure of the original sequence and the structure of its adversarially perturbed version. We prove that the problem of minimally perturbing protein sequences to fool protein folding neural networks is NP-complete. Based on the well-established BLOSUM62 sequence alignment scoring matrix, we generate adversarial protein sequences and show that the RMSD between the predicted protein structure and the structure of the original sequence are very large when the adversarial changes are bounded by (i) 20 units in the BLOSUM62 distance, and (ii) five residues (out of hundreds or thousands of residues) in the given protein sequence. In our experimental evaluation, we consider 111 COVID-19 proteins in the Universal Protein resource (UniProt), a central resource for protein data managed by the European Bioinformatics Institute, Swiss Institute of Bioinformatics, and the US Protein Information Resource. These result in an overall GDT similarity test score average of around 34%, demonstrating a substantial drop in the performance of AlphaFold.
The Multimodal Driver Monitoring Database: A Naturalistic Corpus to Study Driver Attention
Dec 23, 2020
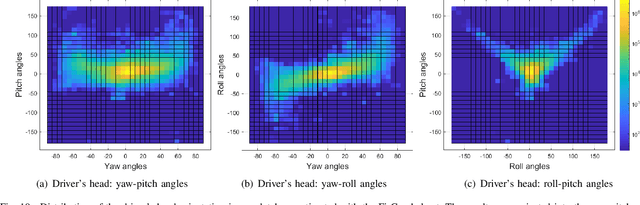
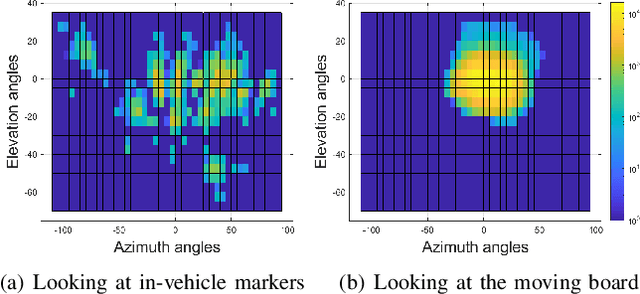

A smart vehicle should be able to monitor the actions and behaviors of the human driver to provide critical warnings or intervene when necessary. Recent advancements in deep learning and computer vision have shown great promise in monitoring human behaviors and activities. While these algorithms work well in a controlled environment, naturalistic driving conditions add new challenges such as illumination variations, occlusions and extreme head poses. A vast amount of in-domain data is required to train models that provide high performance in predicting driving related tasks to effectively monitor driver actions and behaviors. Toward building the required infrastructure, this paper presents the multimodal driver monitoring (MDM) dataset, which was collected with 59 subjects that were recorded performing various tasks. We use the Fi- Cap device that continuously tracks the head movement of the driver using fiducial markers, providing frame-based annotations to train head pose algorithms in naturalistic driving conditions. We ask the driver to look at predetermined gaze locations to obtain accurate correlation between the driver's facial image and visual attention. We also collect data when the driver performs common secondary activities such as navigation using a smart phone and operating the in-car infotainment system. All of the driver's activities are recorded with high definition RGB cameras and time-of-flight depth camera. We also record the controller area network-bus (CAN-Bus), extracting important information. These high quality recordings serve as the ideal resource to train various efficient algorithms for monitoring the driver, providing further advancements in the field of in-vehicle safety systems.