 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-NCS: Reinforcement learning based data-driven approach for nonuniform compressed sensing
Jul 02, 2021



A reinforcement-learning-based non-uniform compressed sensing (NCS) framework for time-varying signals is introduced. The proposed scheme, referred to as RL-NCS, aims to boost the performance of signal recovery through an optimal and adaptive distribution of sensing energy among two groups of coefficients of the signal, referred to as the region of interest (ROI) coefficients and non-ROI coefficients. The coefficients in ROI usually have greater importance and need to be reconstructed with higher accuracy compared to non-ROI coefficients. In order to accomplish this task, the ROI is predicted at each time step using two specific approaches. One of these approaches incorporates a long short-term memory (LSTM) network for the prediction. The other approach employs the previous ROI information for predicting the next step ROI. Using the exploration-exploitation technique, a Q-network learns to choose the best approach for designing the measurement matrix. Furthermore, a joint loss function is introduced for the efficient training of the Q-network as well as the LSTM network. The result indicates a significant performance gain for our proposed method, even for rapidly varying signals and a reduced number of measurements.
Iterative Projection and Matching: Finding Structure-preserving Representatives and Its Application to Computer Vision
Nov 29, 2018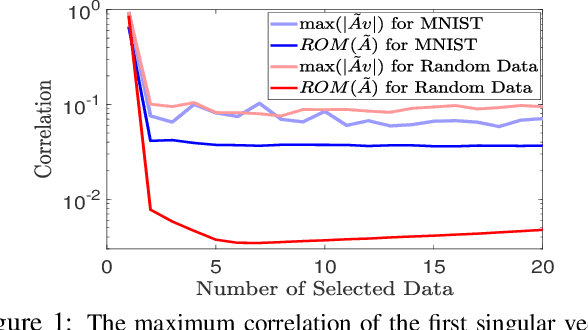
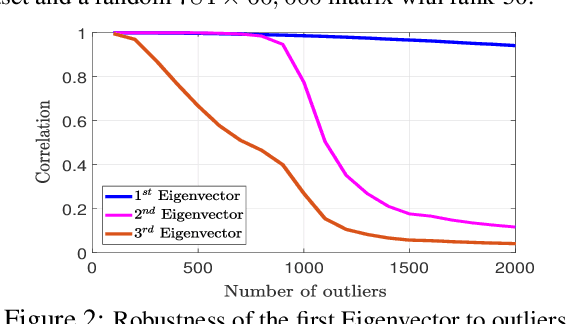

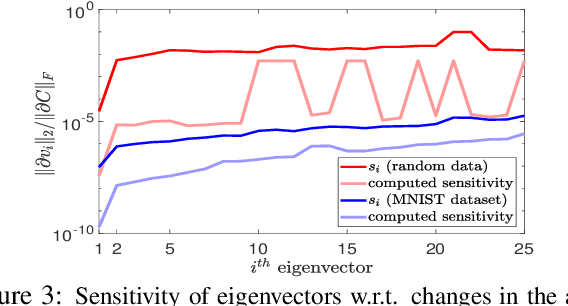
The goal of data selection is to capture the most structural information from a set of data. This paper presents a fast and accurate data selection method, in which the selected samples are optimized to span the subspace of all data. We propose a new selection algorithm, referred to as iterative projection and matching (IPM), with linear complexity w.r.t. the number of data, and without any parameter to be tuned. In our algorithm, at each iteration, the maximum information from the structure of the data is captured by one selected sample, and the captured information is neglected in the next iterations by projection on the null-space of previously selected samples. The computational efficiency and the selection accuracy of our proposed algorithm outperform those of the conventional methods. Furthermore, the superiority of the proposed algorithm is shown on active learning for video action recognition dataset on UCF-101; learning using representatives on ImageNet; training a generative adversarial network (GAN) to generate multi-view images from a single-view input on CMU Multi-PIE dataset; and video summarization on UTE Egocentric dataset.
Norm-Preservation: Why Residual Networks Can Become Extremely Deep?
May 18, 2018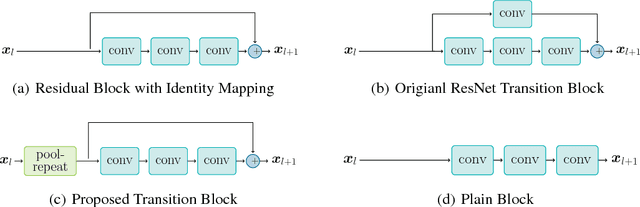

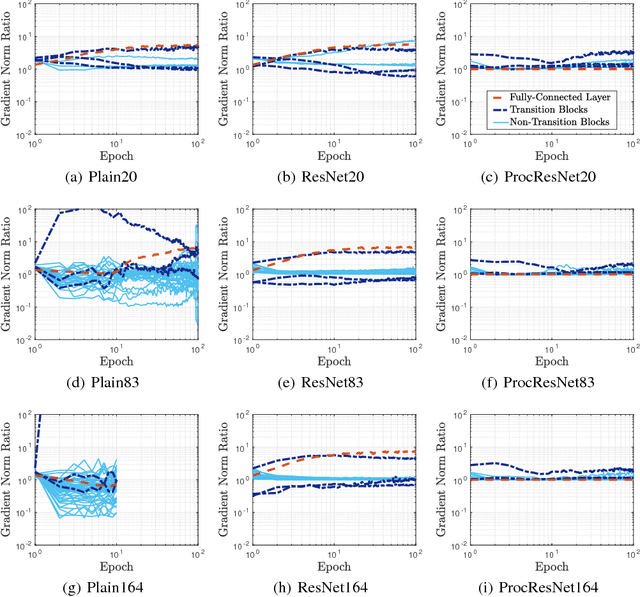

Augmenting deep neural networks with skip connections, as introduced in the so called ResNet architecture, surprised the community by enabling the training of networks of more than 1000 layers with significant performance gains. It has been shown that identity skip connections eliminate singularities and improve the optimization landscape of the network. This paper deciphers ResNet by analyzing the of effect of skip connections in the backward path and sets forth new theoretical results on the advantages of identity skip connections in deep neural networks. We prove that the skip connections in the residual blocks facilitate preserving the norm of the gradient and lead to well-behaved and stable back-propagation, which is a desirable feature from optimization perspective. We also show that, perhaps surprisingly, as more residual blocks are stacked, the network becomes more norm-preserving. Traditionally, norm-preservation is enforced on the network only at beginning of the training, by using initialization techniques. However, we show that identity skip connection retain norm-preservation during the training procedure. Our theoretical arguments are supported by extensive empirical evidence. Can we push for more norm-preservation? We answer this question by proposing zero-phase whitening of the fully-connected layer and adding norm-preserving transition layers. Our numerical investigations demonstrate that the learning dynamics and the performance of ResNets can be improved by making it even more norm preserving through changing only a few blocks in very deep residual networks. Our results and the introduced modification for ResNet, referred to as Procrustes ResNets, can be used as a guide for studying more complex architectures such as DenseNet, training deeper networks, and inspiring new architectures.