 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNorm-Preservation: Why Residual Networks Can Become Extremely Deep?
Paper and Code
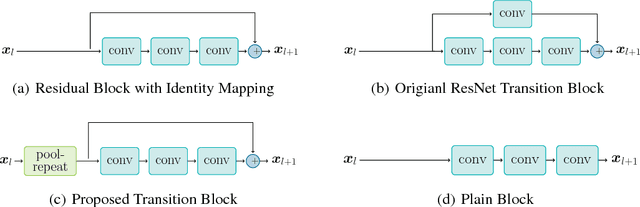

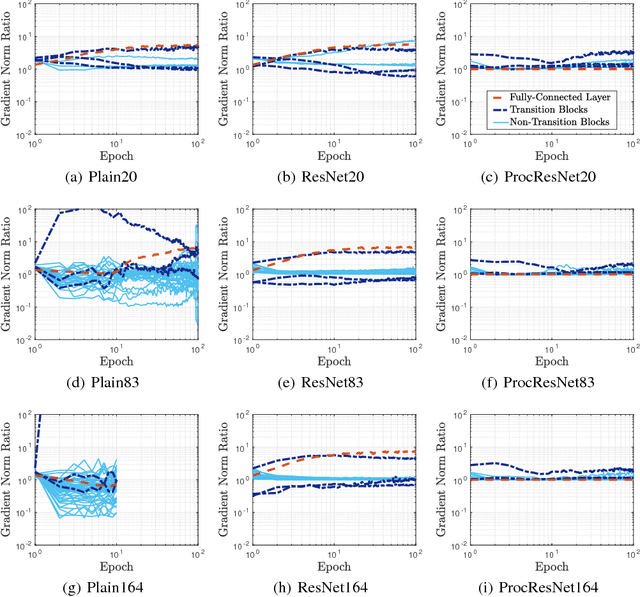

Augmenting deep neural networks with skip connections, as introduced in the so called ResNet architecture, surprised the community by enabling the training of networks of more than 1000 layers with significant performance gains. It has been shown that identity skip connections eliminate singularities and improve the optimization landscape of the network. This paper deciphers ResNet by analyzing the of effect of skip connections in the backward path and sets forth new theoretical results on the advantages of identity skip connections in deep neural networks. We prove that the skip connections in the residual blocks facilitate preserving the norm of the gradient and lead to well-behaved and stable back-propagation, which is a desirable feature from optimization perspective. We also show that, perhaps surprisingly, as more residual blocks are stacked, the network becomes more norm-preserving. Traditionally, norm-preservation is enforced on the network only at beginning of the training, by using initialization techniques. However, we show that identity skip connection retain norm-preservation during the training procedure. Our theoretical arguments are supported by extensive empirical evidence. Can we push for more norm-preservation? We answer this question by proposing zero-phase whitening of the fully-connected layer and adding norm-preserving transition layers. Our numerical investigations demonstrate that the learning dynamics and the performance of ResNets can be improved by making it even more norm preserving through changing only a few blocks in very deep residual networks. Our results and the introduced modification for ResNet, referred to as Procrustes ResNets, can be used as a guide for studying more complex architectures such as DenseNet, training deeper networks, and inspiring new architectures.