 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Compositional Visual Generation with Latent Classifier Guidance
Paper and Code
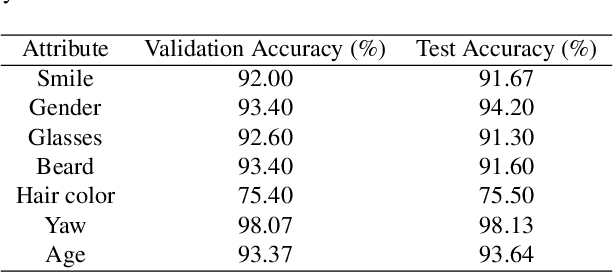



Diffusion probabilistic models have achieved enormous success in the field of image generation and manipulation. In this paper, we explore a novel paradigm of using the diffusion model and classifier guidance in the latent semantic space for compositional visual tasks. linear fashion. Specifically, we train latent diffusion models and auxiliary latent classifiers to facilitate non-linear navigation of latent representation generation for any pre-trained generative model with a semantic latent space. We demonstrate that such conditional generation achieved by latent classifier guidance provably maximizes a lower bound of the conditional log probability during training. To maintain the original semantics during manipulation, we introduce a new guidance term, which we show is crucial for achieving compositionality. With additional assumptions, we show that the non-linear manipulation reduces to a simple latent arithmetic approach. We show that this paradigm based on latent classifier guidance is agnostic to pre-trained generative models, and present competitive results for both image generation and sequential manipulation of real and synthetic images. Our findings suggest that latent classifier guidance is a promising approach that merits further exploration, even in the presence of other strong competing methods.