 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary 3D Instruction Ambiguity Detection
Jan 09, 2026In safety-critical domains, linguistic ambiguity can have severe consequences; a vague command like "Pass me the vial" in a surgical setting could lead to catastrophic errors. Yet, most embodied AI research overlooks this, assuming instructions are clear and focusing on execution rather than confirmation. To address this critical safety gap, we are the first to define Open-Vocabulary 3D Instruction Ambiguity Detection, a fundamental new task where a model must determine if a command has a single, unambiguous meaning within a given 3D scene. To support this research, we build Ambi3D, the large-scale benchmark for this task, featuring over 700 diverse 3D scenes and around 22k instructions. Our analysis reveals a surprising limitation: state-of-the-art 3D Large Language Models (LLMs) struggle to reliably determine if an instruction is ambiguous. To address this challenge, we propose AmbiVer, a two-stage framework that collects explicit visual evidence from multiple views and uses it to guide an vision-language model (VLM) in judging instruction ambiguity. Extensive experiments demonstrate the challenge of our task and the effectiveness of AmbiVer, paving the way for safer and more trustworthy embodied AI. Code and dataset available at https://jiayuding031020.github.io/ambi3d/.
Polysemous Language Gaussian Splatting via Matching-based Mask Lifting
Sep 26, 2025Lifting 2D open-vocabulary understanding into 3D Gaussian Splatting (3DGS) scenes is a critical challenge. However, mainstream methods suffer from three key flaws: (i) their reliance on costly per-scene retraining prevents plug-and-play application; (ii) their restrictive monosemous design fails to represent complex, multi-concept semantics; and (iii) their vulnerability to cross-view semantic inconsistencies corrupts the final semantic representation. To overcome these limitations, we introduce MUSplat, a training-free framework that abandons feature optimization entirely. Leveraging a pre-trained 2D segmentation model, our pipeline generates and lifts multi-granularity 2D masks into 3D, where we estimate a foreground probability for each Gaussian point to form initial object groups. We then optimize the ambiguous boundaries of these initial groups using semantic entropy and geometric opacity. Subsequently, by interpreting the object's appearance across its most representative viewpoints, a Vision-Language Model (VLM) distills robust textual features that reconciles visual inconsistencies, enabling open-vocabulary querying via semantic matching. By eliminating the costly per-scene training process, MUSplat reduces scene adaptation time from hours to mere minutes. On benchmark tasks for open-vocabulary 3D object selection and semantic segmentation, MUSplat outperforms established training-based frameworks while simultaneously addressing their monosemous limitations.
LongReasonArena: A Long Reasoning Benchmark for Large Language Models
Aug 26, 2025Existing long-context benchmarks for Large Language Models (LLMs) focus on evaluating comprehension of long inputs, while overlooking the evaluation of long reasoning abilities. To address this gap, we introduce LongReasonArena, a benchmark specifically designed to assess the long reasoning capabilities of LLMs. Our tasks require models to solve problems by executing multi-step algorithms that reflect key aspects of long reasoning, such as retrieval and backtracking. By controlling the inputs, the required reasoning length can be arbitrarily scaled, reaching up to 1 million tokens of reasoning for the most challenging tasks. Extensive evaluation results demonstrate that LongReasonArena presents a significant challenge for both open-source and proprietary LLMs. For instance, Deepseek-R1 achieves only 7.5% accuracy on our task. Further analysis also reveals that the accuracy exhibits a linear decline with respect to the logarithm of the expected number of reasoning steps. Our code and data is available at https://github.com/LongReasonArena/LongReasonArena.
Transformable Modular Robots: A CPG-Based Approach to Independent and Collective Locomotion
Mar 17, 2025Modular robotics enables the development of versatile and adaptive robotic systems with autonomous reconfiguration. This paper presents a modular robotic system in which each module has independent actuation, battery power, and control, allowing both individual mobility and coordinated locomotion. A hierarchical Central Pattern Generator (CPG) framework governs motion, with a low-level CPG controlling individual modules and a high-level CPG synchronizing inter-module coordination, enabling smooth transitions between independent and collective behaviors. To validate the system, we conduct simulations in MuJoCo and hardware experiments, evaluating locomotion across different configurations. We first analyze single-module motion, followed by two-module cooperative locomotion. Results demonstrate the effectiveness of the CPG-based control framework in achieving robust, flexible, and scalable locomotion. The proposed modular architecture has potential applications in search and rescue, environmental monitoring, and autonomous exploration, where adaptability and reconfigurability are essential.
When an Image is Worth 1,024 x 1,024 Words: A Case Study in Computational Pathology
Dec 06, 2023This technical report presents LongViT, a vision Transformer that can process gigapixel images in an end-to-end manner. Specifically, we split the gigapixel image into a sequence of millions of patches and project them linearly into embeddings. LongNet is then employed to model the extremely long sequence, generating representations that capture both short-range and long-range dependencies. The linear computation complexity of LongNet, along with its distributed algorithm, enables us to overcome the constraints of both computation and memory. We apply LongViT in the field of computational pathology, aiming for cancer diagnosis and prognosis within gigapixel whole-slide images. Experimental results demonstrate that LongViT effectively encodes gigapixel images and outperforms previous state-of-the-art methods on cancer subtyping and survival prediction. Code and models will be available at https://aka.ms/LongViT.
LongNet: Scaling Transformers to 1,000,000,000 Tokens
Jul 19, 2023Scaling sequence length has become a critical demand in the era of large language models. However, existing methods struggle with either computational complexity or model expressivity, rendering the maximum sequence length restricted. To address this issue, we introduce LongNet, a Transformer variant that can scale sequence length to more than 1 billion tokens, without sacrificing the performance on shorter sequences. Specifically, we propose dilated attention, which expands the attentive field exponentially as the distance grows. LongNet has significant advantages: 1) it has a linear computation complexity and a logarithm dependency between any two tokens in a sequence; 2) it can be served as a distributed trainer for extremely long sequences; 3) its dilated attention is a drop-in replacement for standard attention, which can be seamlessly integrated with the existing Transformer-based optimization. Experiments results demonstrate that LongNet yields strong performance on both long-sequence modeling and general language tasks. Our work opens up new possibilities for modeling very long sequences, e.g., treating a whole corpus or even the entire Internet as a sequence.
Breaking Symmetries Leads to Diverse Quadrupedal Gaits
Mar 08, 2023Symmetry manifests itself in legged locomotion in a variety of ways. No matter where a legged system begins to move periodically, the torso and limbs coordinate with each other's movements in a similar manner. Also, in many gaits observed in nature, the legs on both sides of the torso move in exactly the same way, sometimes they are just half a period out of phase. Furthermore, when some animals move forward and backward, their movements are strikingly similar as if the time had been reversed. This work aims to generalize these phenomena and propose formal definitions of symmetries in legged locomotion using group theory terminology. Symmetries in some common quadrupedal gaits such as pronking, bounding, half-bounding, and galloping have been discussed. Moreover, a spring-mass model has been used to demonstrate how breaking symmetries can alter gaits in a legged system. Studying the symmetries may provide insight into which gaits may be suitable for a particular robotic design, or may enable roboticists to design more agile and efficient robot controllers by using certain gaits.
Reasoning Chain Based Adversarial Attack for Multi-hop Question Answering
Dec 17, 2021

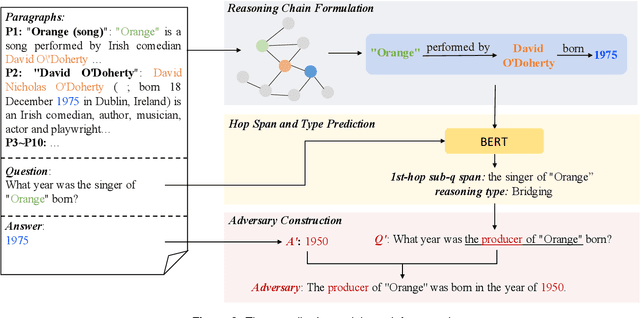

Recent years have witnessed impressive advances in challenging multi-hop QA tasks. However, these QA models may fail when faced with some disturbance in the input text and their interpretability for conducting multi-hop reasoning remains uncertain. Previous adversarial attack works usually edit the whole question sentence, which has limited effect on testing the entity-based multi-hop inference ability. In this paper, we propose a multi-hop reasoning chain based adversarial attack method. We formulate the multi-hop reasoning chains starting from the query entity to the answer entity in the constructed graph, which allows us to align the question to each reasoning hop and thus attack any hop. We categorize the questions into different reasoning types and adversarially modify part of the question corresponding to the selected reasoning hop to generate the distracting sentence. We test our adversarial scheme on three QA models on HotpotQA dataset. The results demonstrate significant performance reduction on both answer and supporting facts prediction, verifying the effectiveness of our reasoning chain based attack method for multi-hop reasoning models and the vulnerability of them. Our adversarial re-training further improves the performance and robustness of these models.
CropDefender: deep watermark which is more convenient to train and more robust against cropping
Sep 12, 2021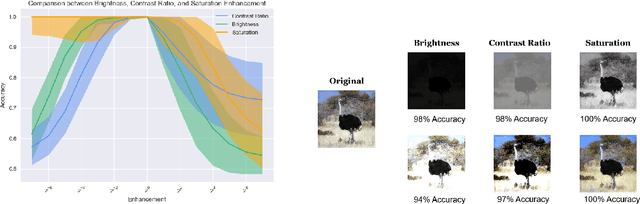
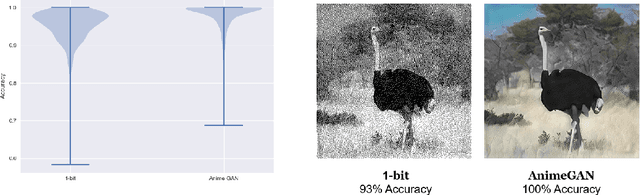

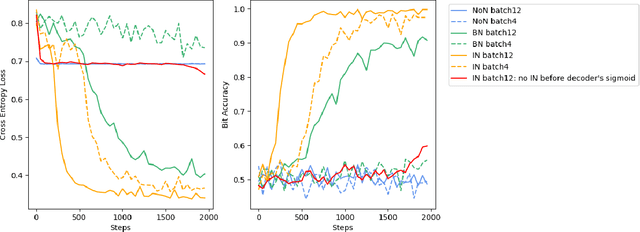
Digital image watermarking, which is a technique for invisibly embedding information into an image, is used in fields such as property rights protection. In recent years, some research has proposed the use of neural networks to add watermarks to natural images. We take StegaStamp as an example for our research. Whether facing traditional image editing methods, such as brightness, contrast, saturation adjustment, or style change like 1-bit conversion, GAN, StegaStamp has robustness far beyond traditional watermarking techniques, but it still has two drawbacks: it is vulnerable to cropping and is hard to train. We found that the causes of vulnerability to cropping is not the loss of information on the edge, but the movement of watermark position. By explicitly introducing the perturbation of cropping into the training, the cropping resistance is significantly improved. For the problem of difficult training, we introduce instance normalization to solve the vanishing gradient, set losses' weights as learnable parameters to reduce the number of hyperparameters, and use sigmoid to restrict pixel values of the generated image.