 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Chain Based Adversarial Attack for Multi-hop Question Answering
Paper and Code


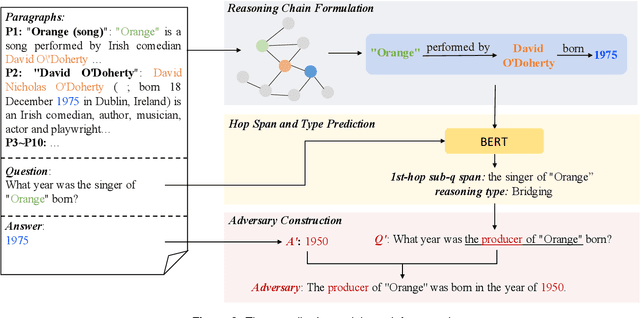

Recent years have witnessed impressive advances in challenging multi-hop QA tasks. However, these QA models may fail when faced with some disturbance in the input text and their interpretability for conducting multi-hop reasoning remains uncertain. Previous adversarial attack works usually edit the whole question sentence, which has limited effect on testing the entity-based multi-hop inference ability. In this paper, we propose a multi-hop reasoning chain based adversarial attack method. We formulate the multi-hop reasoning chains starting from the query entity to the answer entity in the constructed graph, which allows us to align the question to each reasoning hop and thus attack any hop. We categorize the questions into different reasoning types and adversarially modify part of the question corresponding to the selected reasoning hop to generate the distracting sentence. We test our adversarial scheme on three QA models on HotpotQA dataset. The results demonstrate significant performance reduction on both answer and supporting facts prediction, verifying the effectiveness of our reasoning chain based attack method for multi-hop reasoning models and the vulnerability of them. Our adversarial re-training further improves the performance and robustness of these models.