 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull Point Encoding for Local Feature Aggregation in 3D Point Clouds
Paper and Code
Mar 08, 2023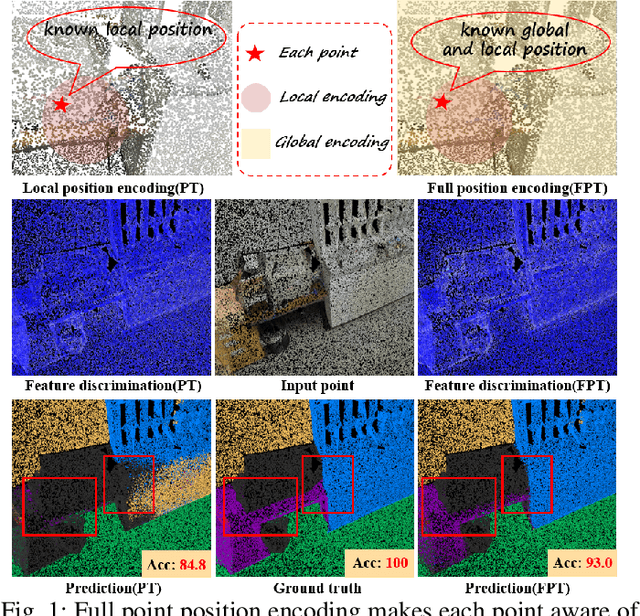
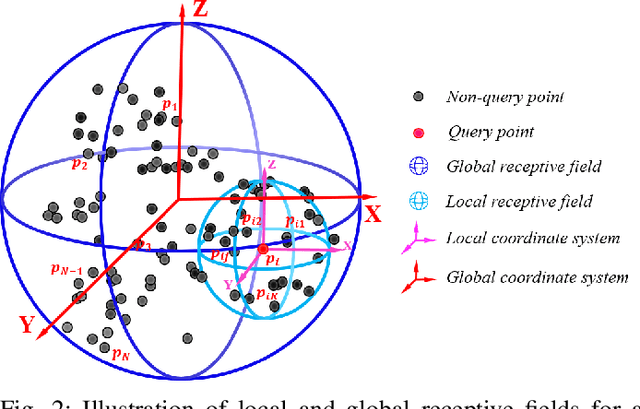
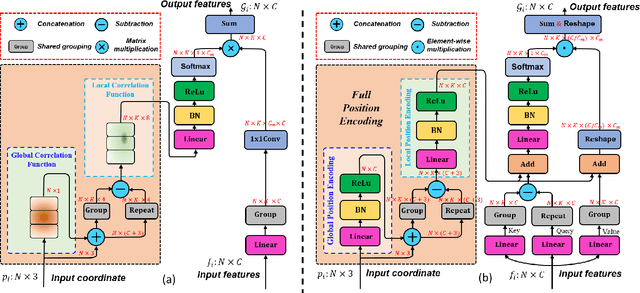
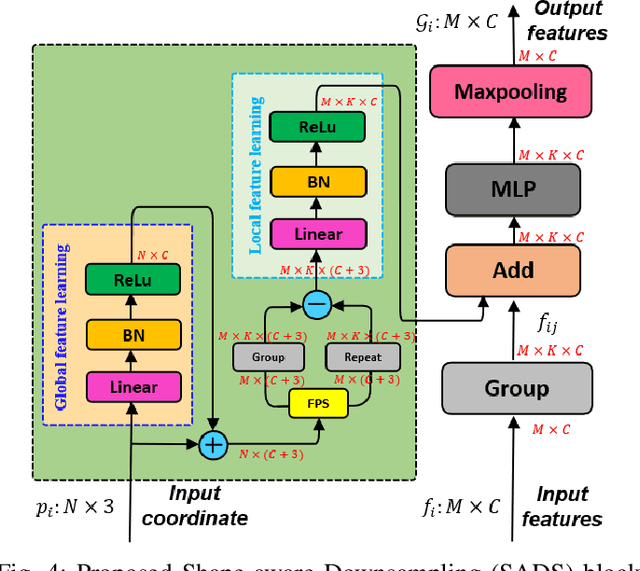
Point cloud processing methods exploit local point features and global context through aggregation which does not explicity model the internal correlations between local and global features. To address this problem, we propose full point encoding which is applicable to convolution and transformer architectures. Specifically, we propose Full Point Convolution (FPConv) and Full Point Transformer (FPTransformer) architectures. The key idea is to adaptively learn the weights from local and global geometric connections, where the connections are established through local and global correlation functions respectively. FPConv and FPTransformer simultaneously model the local and global geometric relationships as well as their internal correlations, demonstrating strong generalization ability and high performance. FPConv is incorporated in classical hierarchical network architectures to achieve local and global shape-aware learning. In FPTransformer, we introduce full point position encoding in self-attention, that hierarchically encodes each point position in the global and local receptive field. We also propose a shape aware downsampling block which takes into account the local shape and the global context. Experimental comparison to existing methods on benchmark datasets show the efficacy of FPConv and FPTransformer for semantic segmentation, object detection, classification, and normal estimation tasks. In particular, we achieve state-of-the-art semantic segmentation results of 76% mIoU on S3DIS 6-fold and 72.2% on S3DIS Area5.