 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Image Dataset of Common Skin Diseases of Bangladesh and Benchmarking Performance with Machine Learning Models
Mar 26, 2026Skin diseases are a major public health concern worldwide, and their detection is often challenging without access to dermatological expertise. In countries like Bangladesh, which is highly populated, the number of qualified skin specialists and diagnostic instruments is insufficient to meet the demand. Due to the lack of proper detection and treatment of skin diseases, that may lead to severe health consequences including death. Common properties of skin diseases are, changing the color, texture, and pattern of skin and in this era of artificial intelligence and machine learning, we are able to detect skin diseases by using image processing and computer vision techniques. In response to this challenge, we develop a publicly available dataset focused on common skin disease detection using machine learning techniques. We focus on five prevalent skin diseases in Bangladesh: Contact Dermatitis, Vitiligo, Eczema, Scabies, and Tinea Ringworm. The dataset consists of 1612 images (of which, 250 are distinct while others are augmented), collected directly from patients at the outpatient department of Faridpur Medical College, Faridpur, Bangladesh. The data comprises of 302, 381, 301, 316, and 312 images of Dermatitis, Eczema, Scabies, Tinea Ringworm, and Vitiligo, respectively. Although the data are collected regionally, the selected diseases are common across many countries especially in South Asia, making the dataset potentially valuable for global applications in machine learning-based dermatology. We also apply several machine learning and deep learning models on the dataset and report classification performance. We expect that this research would garner attention from machine learning and deep learning researchers and practitioners working in the field of automated disease diagnosis.
NCTB-QA: A Large-Scale Bangla Educational Question Answering Dataset and Benchmarking Performance
Mar 05, 2026Reading comprehension systems for low-resource languages face significant challenges in handling unanswerable questions. These systems tend to produce unreliable responses when correct answers are absent from context. To solve this problem, we introduce NCTB-QA, a large-scale Bangla question answering dataset comprising 87,805 question-answer pairs extracted from 50 textbooks published by Bangladesh's National Curriculum and Textbook Board. Unlike existing Bangla datasets, NCTB-QA maintains a balanced distribution of answerable (57.25%) and unanswerable (42.75%) questions. NCTB-QA also includes adversarially designed instances containing plausible distractors. We benchmark three transformer-based models (BERT, RoBERTa, ELECTRA) and demonstrate substantial improvements through fine-tuning. BERT achieves 313% relative improvement in F1 score (0.150 to 0.620). Semantic answer quality measured by BERTScore also increases significantly across all models. Our results establish NCTB-QA as a challenging benchmark for Bangla educational question answering. This study demonstrates that domain-specific fine-tuning is critical for robust performance in low-resource settings.
EdgeDAM: Real-time Object Tracking for Mobile Devices
Mar 05, 2026Single-object tracking (SOT) on edge devices is a critical computer vision task, requiring accurate and continuous target localization across video frames under occlusion, distractor interference, and fast motion. However, recent state-of-the-art distractor-aware memory mechanisms are largely built on segmentation-based trackers and rely on mask prediction and attention-driven memory updates, which introduce substantial computational overhead and limit real-time deployment on resource-constrained hardware; meanwhile, lightweight trackers sustain high throughput but are prone to drift when visually similar distractors appear. To address these challenges, we propose EdgeDAM, a lightweight detection-guided tracking framework that reformulates distractor-aware memory for bounding-box tracking under strict edge constraints. EdgeDAM introduces two key strategies: (1) Dual-Buffer Distractor-Aware Memory (DAM), which integrates a Recent-Aware Memory to preserve temporally consistent target hypotheses and a Distractor-Resolving Memory to explicitly store hard negative candidates and penalize their re-selection during recovery; and (2) Confidence-Driven Switching with Held-Box Stabilization, where tracker reliability and temporal consistency criteria adaptively activate detection and memory-guided re-identification during occlusion, while a held-box mechanism temporarily freezes and expands the estimate to suppress distractor contamination. Extensive experiments on five benchmarks, including the distractor-focused DiDi dataset, demonstrate improved robustness under occlusion and fast motion while maintaining real-time performance on mobile devices, achieving 88.2% accuracy on DiDi and 25 FPS on an iPhone 15. Code will be released.
BAWSeg: A UAV Multispectral Benchmark for Barley Weed Segmentation
Mar 02, 2026Accurate weed mapping in cereal fields requires pixel-level segmentation from UAV imagery that remains reliable across fields, seasons, and illumination. Existing multispectral pipelines often depend on thresholded vegetation indices, which are brittle under radiometric drift and mixed crop--weed pixels, or on single-stream CNN and Transformer backbones that ingest stacked bands and indices, where radiance cues and normalized index cues interfere and reduce sensitivity to small weed clusters embedded in crop canopies. We propose VISA (Vegetation-Index and Spectral Attention), a two-stream segmentation network that decouples these cues and fuses them at native resolution. The radiance stream learns from calibrated five-band reflectance using residual spectral-spatial attention to preserve fine textures and row boundaries that are attenuated by ratio indices. The index stream operates on vegetation-index maps with windowed self-attention to model local structure efficiently, state-space layers to propagate field-scale context without quadratic attention cost, and Slot Attention to form stable region descriptors that improve discrimination of sparse weeds under canopy mixing. To support supervised training and deployment-oriented evaluation, we introduce BAWSeg, a four-year UAV multispectral dataset collected over commercial barley paddocks in Western Australia, providing radiometrically calibrated blue, green, red, red edge, and near-infrared orthomosaics, derived vegetation indices, and dense crop, weed, and other labels with leakage-free block splits. On BAWSeg, VISA achieves 75.6% mIoU and 63.5% weed IoU with 22.8M parameters, outperforming a multispectral SegFormer-B1 baseline by 1.2 mIoU and 1.9 weed IoU. Under cross-plot and cross-year protocols, VISA maintains 71.2% and 69.2% mIoU, respectively. The BAWSeg data, VISA code, and trained models will be released upon publication.
Reliable Deep Learning for Small-Scale Classifications: Experiments on Real-World Image Datasets from Bangladesh
Jan 17, 2026Convolutional neural networks (CNNs) have achieved state-of-the-art performance in image recognition tasks but often involve complex architectures that may overfit on small datasets. In this study, we evaluate a compact CNN across five publicly available, real-world image datasets from Bangladesh, including urban encroachment, vehicle detection, road damage, and agricultural crops. The network demonstrates high classification accuracy, efficient convergence, and low computational overhead. Quantitative metrics and saliency analyses indicate that the model effectively captures discriminative features and generalizes robustly across diverse scenarios, highlighting the suitability of streamlined CNN architectures for small-class image classification tasks.
Detecting Unauthorized Vehicles using Deep Learning for Smart Cities: A Case Study on Bangladesh
Oct 30, 2025Modes of transportation vary across countries depending on geographical location and cultural context. In South Asian countries rickshaws are among the most common means of local transport. Based on their mode of operation, rickshaws in cities across Bangladesh can be broadly classified into non-auto (pedal-powered) and auto-rickshaws (motorized). Monitoring the movement of auto-rickshaws is necessary as traffic rules often restrict auto-rickshaws from accessing certain routes. However, existing surveillance systems make it quite difficult to monitor them due to their similarity to other vehicles, especially non-auto rickshaws whereas manual video analysis is too time-consuming. This paper presents a machine learning-based approach to automatically detect auto-rickshaws in traffic images. In this system, we used real-time object detection using the YOLOv8 model. For training purposes, we prepared a set of 1,730 annotated images that were captured under various traffic conditions. The results show that our proposed model performs well in real-time auto-rickshaw detection and offers an mAP50 of 83.447% and binary precision and recall values above 78%, demonstrating its effectiveness in handling both dense and sparse traffic scenarios. The dataset has been publicly released for further research.
Multispectral Remote Sensing for Weed Detection in West Australian Agricultural Lands
Feb 12, 2025The Kondinin region in Western Australia faces significant agricultural challenges due to pervasive weed infestations, causing economic losses and ecological impacts. This study constructs a tailored multispectral remote sensing dataset and an end-to-end framework for weed detection to advance precision agriculture practices. Unmanned aerial vehicles were used to collect raw multispectral data from two experimental areas (E2 and E8) over four years, covering 0.6046 km^{2} and ground truth annotations were created with GPS-enabled vehicles to manually label weeds and crops. The dataset is specifically designed for agricultural applications in Western Australia. We propose an end-to-end framework for weed detection that includes extensive preprocessing steps, such as denoising, radiometric calibration, image alignment, orthorectification, and stitching. The proposed method combines vegetation indices (NDVI, GNDVI, EVI, SAVI, MSAVI) with multispectral channels to form classification features, and employs several deep learning models to identify weeds based on the input features. Among these models, ResNet achieves the highest performance, with a weed detection accuracy of 0.9213, an F1-Score of 0.8735, an mIOU of 0.7888, and an mDC of 0.8865, validating the efficacy of the dataset and the proposed weed detection method.
* 8 pages, 9 figures, 1 table, Accepted for oral presentation at IEEE 25th International Conference on Digital Image Computing: Techniques and Applications (DICTA 2024). Conference Proceeding: 979-8-3503-7903-7/24/\$31.00 (C) 2024 IEEE
Automated Road Extraction and Centreline Fitting in LiDAR Point Clouds
Feb 11, 2025Road information extraction from 3D point clouds is useful for urban planning and traffic management. Existing methods often rely on local features and the refraction angle of lasers from kerbs, which makes them sensitive to variable kerb designs and issues in high-density areas due to data homogeneity. We propose an approach for extracting road points and fitting centrelines using a top-down view of LiDAR based ground-collected point clouds. This prospective view reduces reliance on specific kerb design and results in better road extraction. We first perform statistical outlier removal and density-based clustering to reduce noise from 3D point cloud data. Next, we perform ground point filtering using a grid-based segmentation method that adapts to diverse road scenarios and terrain characteristics. The filtered points are then projected onto a 2D plane, and the road is extracted by a skeletonisation algorithm. The skeleton is back-projected onto the 3D point cloud with calculated normals, which guide a region growing algorithm to find nearby road points. The extracted road points are then smoothed with the Savitzky-Golay filter to produce the final centreline. Our initial approach without post-processing of road skeleton achieved 67% in IoU by testing on the Perth CBD dataset with different road types. Incorporating the post-processing of the road skeleton improved the extraction of road points around the smoothed skeleton. The refined approach achieved a higher IoU value of 73% and with 23% reduction in the processing time. Our approach offers a generalised and computationally efficient solution that combines 3D and 2D processing techniques, laying the groundwork for future road reconstruction and 3D-to-2D point cloud alignment.
Soft Masked Transformer for Point Cloud Processing with Skip Attention-Based Upsampling
Mar 21, 2024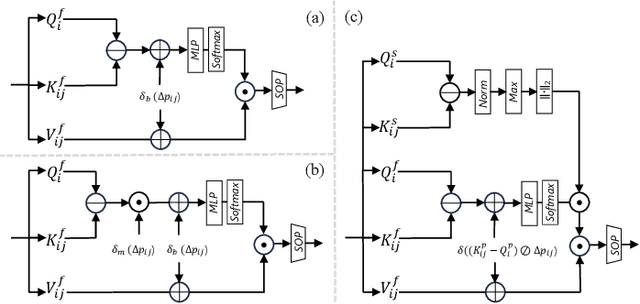
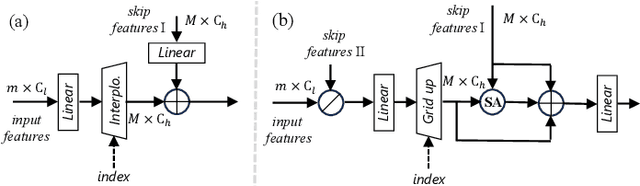
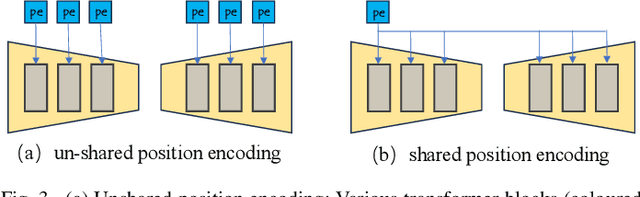
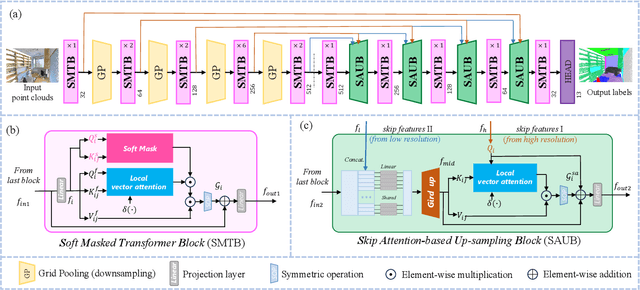
Point cloud processing methods leverage local and global point features %at the feature level to cater to downstream tasks, yet they often overlook the task-level context inherent in point clouds during the encoding stage. We argue that integrating task-level information into the encoding stage significantly enhances performance. To that end, we propose SMTransformer which incorporates task-level information into a vector-based transformer by utilizing a soft mask generated from task-level queries and keys to learn the attention weights. Additionally, to facilitate effective communication between features from the encoding and decoding layers in high-level tasks such as segmentation, we introduce a skip-attention-based up-sampling block. This block dynamically fuses features from various resolution points across the encoding and decoding layers. To mitigate the increase in network parameters and training time resulting from the complexity of the aforementioned blocks, we propose a novel shared position encoding strategy. This strategy allows various transformer blocks to share the same position information over the same resolution points, thereby reducing network parameters and training time without compromising accuracy.Experimental comparisons with existing methods on multiple datasets demonstrate the efficacy of SMTransformer and skip-attention-based up-sampling for point cloud processing tasks, including semantic segmentation and classification. In particular, we achieve state-of-the-art semantic segmentation results of 73.4% mIoU on S3DIS Area 5 and 62.4% mIoU on SWAN dataset
CompactifAI: Extreme Compression of Large Language Models using Quantum-Inspired Tensor Networks
Jan 25, 2024


Large Language Models (LLMs) such as ChatGPT and LlaMA are advancing rapidly in generative Artificial Intelligence (AI), but their immense size poses significant challenges, such as huge training and inference costs, substantial energy demands, and limitations for on-site deployment. Traditional compression methods such as pruning, distillation, and low-rank approximation focus on reducing the effective number of neurons in the network, while quantization focuses on reducing the numerical precision of individual weights to reduce the model size while keeping the number of neurons fixed. While these compression methods have been relatively successful in practice, there's no compelling reason to believe that truncating the number of neurons is an optimal strategy. In this context, this paper introduces CompactifAI, an innovative LLM compression approach using quantum-inspired Tensor Networks that focuses on the model's correlation space instead, allowing for a more controlled, refined and interpretable model compression. Our method is versatile and can be implemented with - or on top of - other compression techniques. As a benchmark, we demonstrate that CompactifAI alone enables compression of the LlaMA-2 7B model to only $30\%$ of its original size while recovering over $90\%$ of the original accuracy after a brief distributed retraining.