 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Engineering in Learning-to-Rank for Community Question Answering Task
Paper and Code
Sep 14, 2023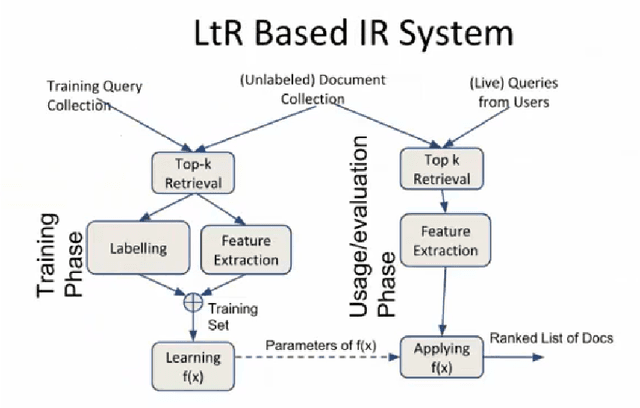

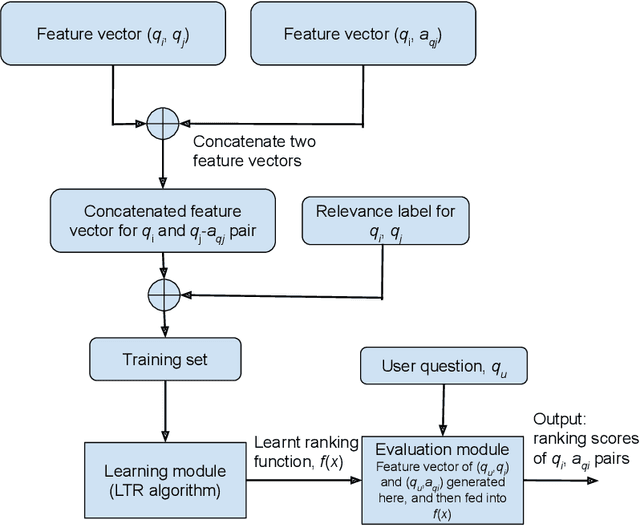
Community question answering (CQA) forums are Internet-based platforms where users ask questions about a topic and other expert users try to provide solutions. Many CQA forums such as Quora, Stackoverflow, Yahoo!Answer, StackExchange exist with a lot of user-generated data. These data are leveraged in automated CQA ranking systems where similar questions (and answers) are presented in response to the query of the user. In this work, we empirically investigate a few aspects of this domain. Firstly, in addition to traditional features like TF-IDF, BM25 etc., we introduce a BERT-based feature that captures the semantic similarity between the question and answer. Secondly, most of the existing research works have focused on features extracted only from the question part; features extracted from answers have not been explored extensively. We combine both types of features in a linear fashion. Thirdly, using our proposed concepts, we conduct an empirical investigation with different rank-learning algorithms, some of which have not been used so far in CQA domain. On three standard CQA datasets, our proposed framework achieves state-of-the-art performance. We also analyze importance of the features we use in our investigation. This work is expected to guide the practitioners to select a better set of features for the CQA retrieval task.