 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Engineering in Learning-to-Rank for Community Question Answering Task
Sep 14, 2023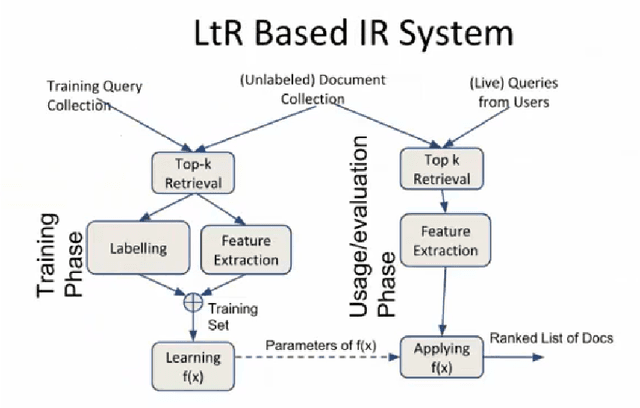

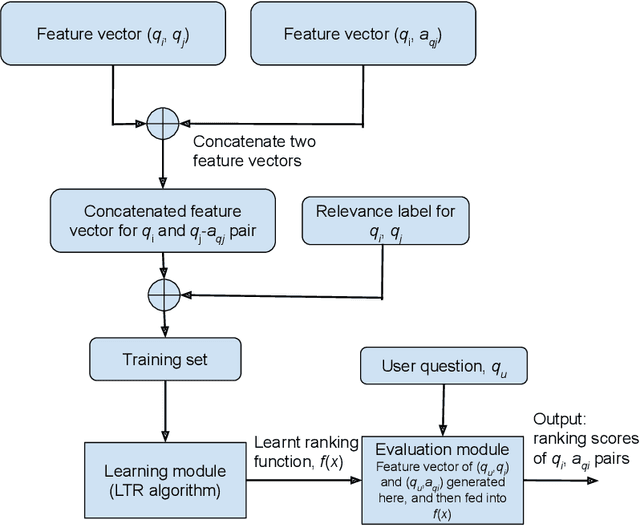
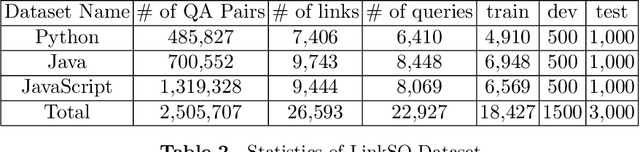
Community question answering (CQA) forums are Internet-based platforms where users ask questions about a topic and other expert users try to provide solutions. Many CQA forums such as Quora, Stackoverflow, Yahoo!Answer, StackExchange exist with a lot of user-generated data. These data are leveraged in automated CQA ranking systems where similar questions (and answers) are presented in response to the query of the user. In this work, we empirically investigate a few aspects of this domain. Firstly, in addition to traditional features like TF-IDF, BM25 etc., we introduce a BERT-based feature that captures the semantic similarity between the question and answer. Secondly, most of the existing research works have focused on features extracted only from the question part; features extracted from answers have not been explored extensively. We combine both types of features in a linear fashion. Thirdly, using our proposed concepts, we conduct an empirical investigation with different rank-learning algorithms, some of which have not been used so far in CQA domain. On three standard CQA datasets, our proposed framework achieves state-of-the-art performance. We also analyze importance of the features we use in our investigation. This work is expected to guide the practitioners to select a better set of features for the CQA retrieval task.
A Comparative Study on Forecasting of Retail Sales
Mar 14, 2022
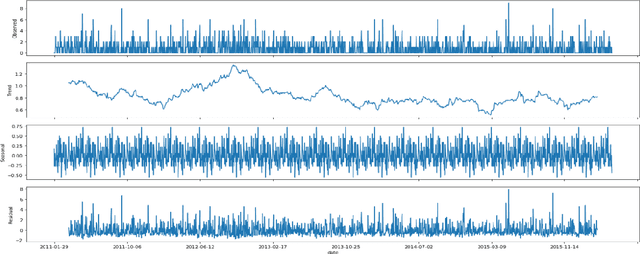
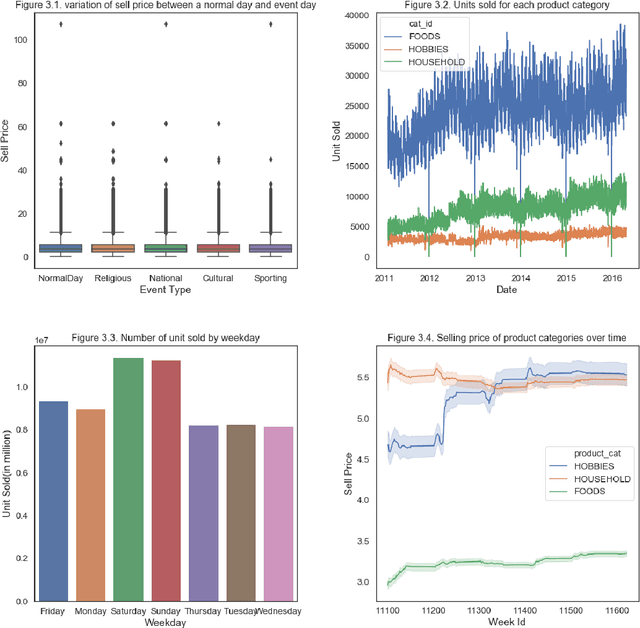
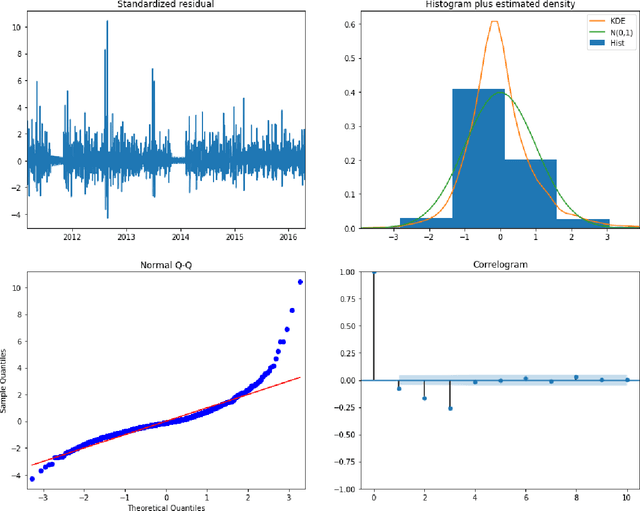
Predicting product sales of large retail companies is a challenging task considering volatile nature of trends, seasonalities, events as well as unknown factors such as market competitions, change in customer's preferences, or unforeseen events, e.g., COVID-19 outbreak. In this paper, we benchmark forecasting models on historical sales data from Walmart to predict their future sales. We provide a comprehensive theoretical overview and analysis of the state-of-the-art timeseries forecasting models. Then, we apply these models on the forecasting challenge dataset (M5 forecasting by Kaggle). Specifically, we use a traditional model, namely, ARIMA (Autoregressive Integrated Moving Average), and recently developed advanced models e.g., Prophet model developed by Facebook, light gradient boosting machine (LightGBM) model developed by Microsoft and benchmark their performances. Results suggest that ARIMA model outperforms the Facebook Prophet and LightGBM model while the LightGBM model achieves huge computational gain for the large dataset with negligible compromise in the prediction accuracy.
Detection of Bangla Fake News using MNB and SVM Classifier
May 29, 2020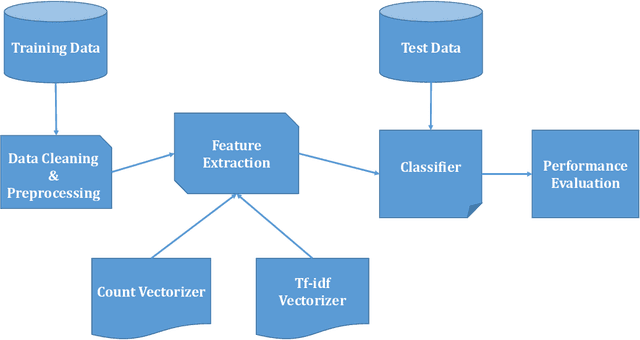
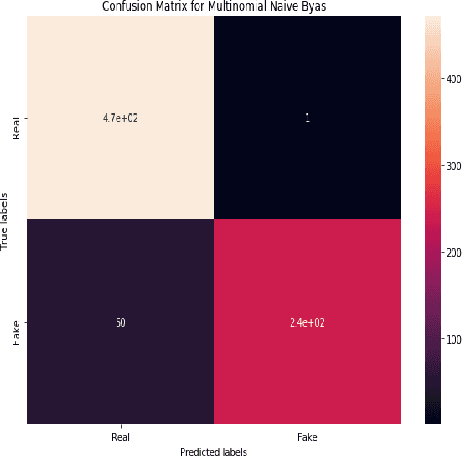
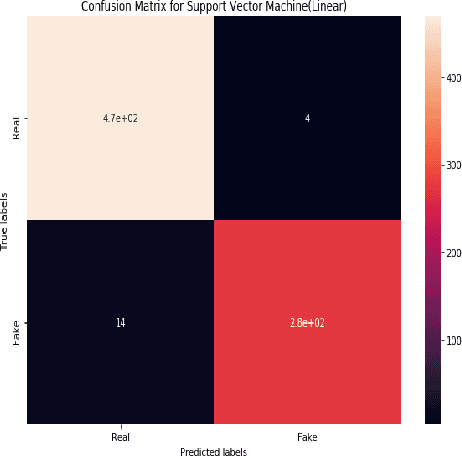
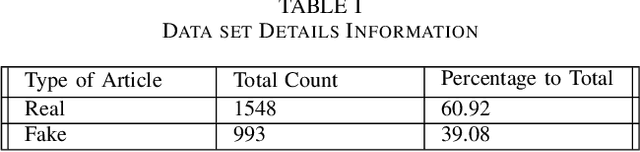
Fake news has been coming into sight in significant numbers for numerous business and political reasons and has become frequent in the online world. People can get contaminated easily by these fake news for its fabricated words which have enormous effects on the offline community. Thus, interest in research in this area has risen. Significant research has been conducted on the detection of fake news from English texts and other languages but a few in Bangla Language. Our work reflects the experimental analysis on the detection of Bangla fake news from social media as this field still requires much focus. In this research work, we have used two supervised machine learning algorithms, Multinomial Naive Bayes (MNB) and Support Vector Machine (SVM) classifiers to detect Bangla fake news with CountVectorizer and Term Frequency - Inverse Document Frequency Vectorizer as feature extraction. Our proposed framework detects fake news depending on the polarity of the corresponding article. Finally, our analysis shows SVM with the linear kernel with an accuracy of 96.64% outperform MNB with an accuracy of 93.32%.
Lung Cancer Detection and Classification based on Image Processing and Statistical Learning
Nov 25, 2019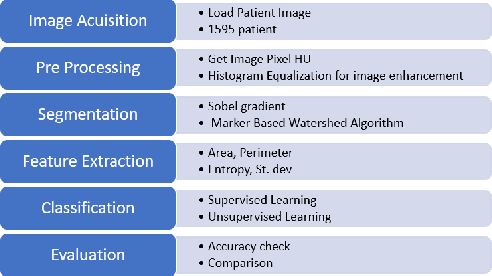
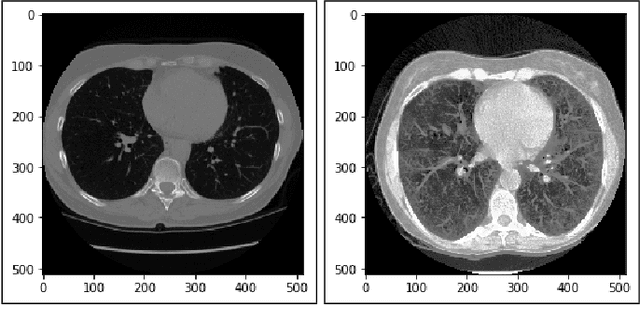
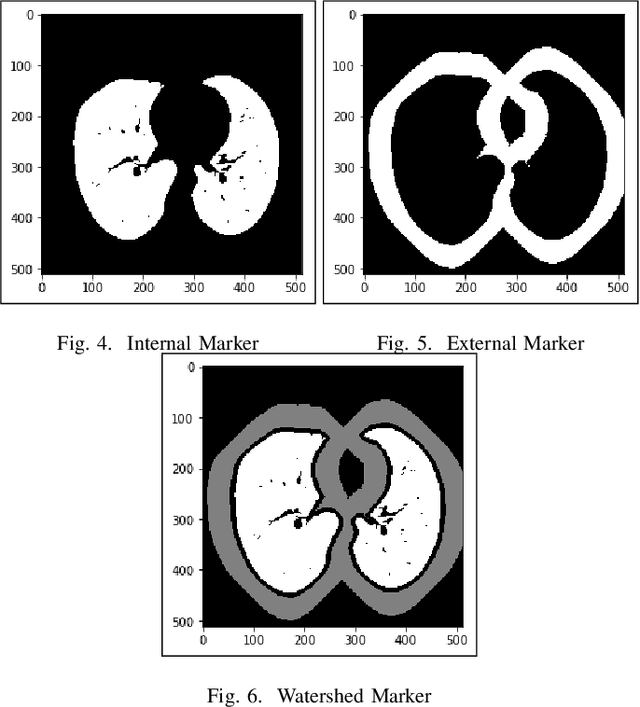
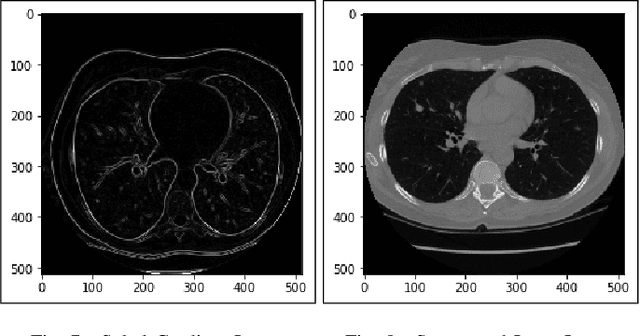
Lung cancer is one of the death threatening diseases among human beings. Early and accurate detection of lung cancer can increase the survival rate from lung cancer. Computed Tomography (CT) images are commonly used for detecting the lung cancer.Using a data set of thousands of high-resolution lung scans collected from Kaggle competition [1], we will develop algorithms that accurately determine in the lungs are cancerous or not. The proposed system promises better result than the existing systems, which would be beneficial for the radiologist for the accurate and early detection of cancer. The method has been tested on 198 slices of CT images of various stages of cancer obtained from Kaggle dataset[1] and is found satisfactory results. The accuracy of the proposed method in this dataset is 72.2%