 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Keyword-Based Technique to Evaluate Broad Question Answer Script
Jun 26, 2025Evaluation is the method of assessing and determining the educational system through various techniques such as verbal or viva-voice test, subjective or objective written test. This paper presents an efficient solution to evaluate the subjective answer script electronically. In this paper, we proposed and implemented an integrated system that examines and evaluates the written answer script. This article focuses on finding the keywords from the answer script and then compares them with the keywords that have been parsed from both open and closed domain. The system also checks the grammatical and spelling errors in the answer script. Our proposed system tested with answer scripts of 100 students and gives precision score 0.91.
* ACM Conference Proceedings (9 Pages)
BANSpEmo: A Bangla Emotional Speech Recognition Dataset
Dec 21, 2023
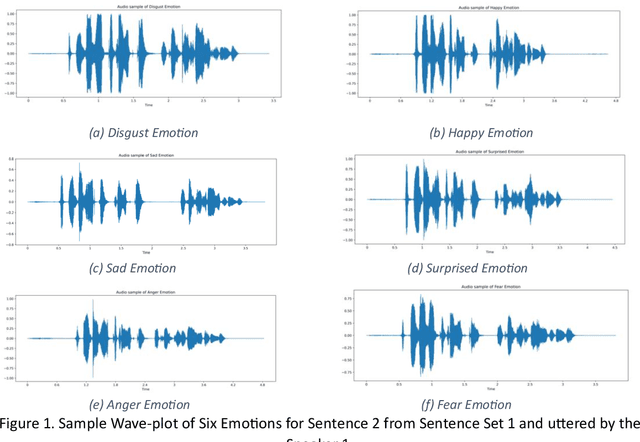
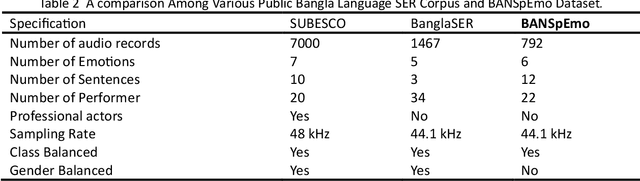
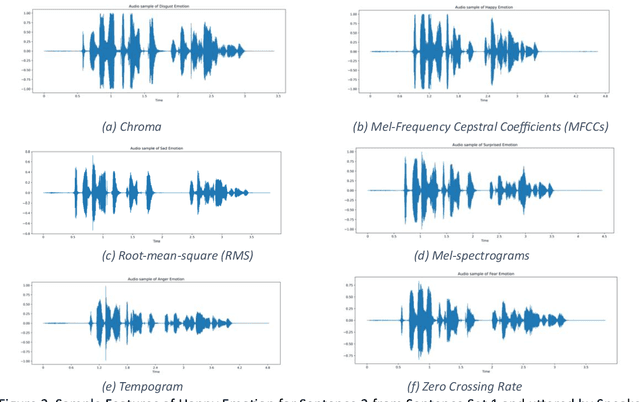
In the field of audio and speech analysis, the ability to identify emotions from acoustic signals is essential. Human-computer interaction (HCI) and behavioural analysis are only a few of the many areas where the capacity to distinguish emotions from speech signals has an extensive range of applications. Here, we are introducing BanSpEmo, a corpus of emotional speech that only consists of audio recordings and has been created specifically for the Bangla language. This corpus contains 792 audio recordings over a duration of more than 1 hour and 23 minutes. 22 native speakers took part in the recording of two sets of sentences that represent the six desired emotions. The data set consists of 12 Bangla sentences which are uttered in 6 emotions as Disgust, Happy, Sad, Surprised, Anger, and Fear. This corpus is not also gender balanced. Ten individuals who either have experience in related field or have acting experience took part in the assessment of this corpus. It has a balanced number of audio recordings in each emotion class. BanSpEmo can be considered as a useful resource to promote emotion and speech recognition research and related applications in the Bangla language. The dataset can be found here: https://data.mendeley.com/datasets/rdwn4bs5ky and might be employed for academic research.
Identifying Alzheimer Disease Dementia Levels Using Machine Learning Methods
Nov 02, 2023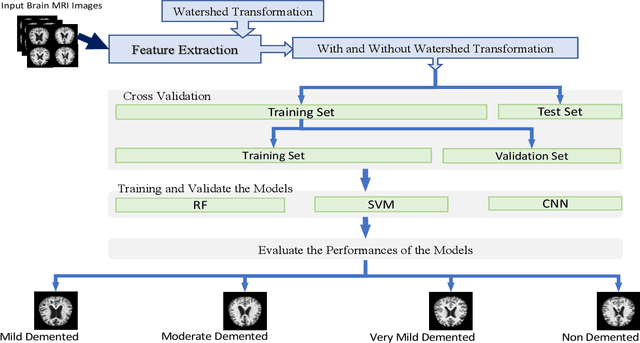
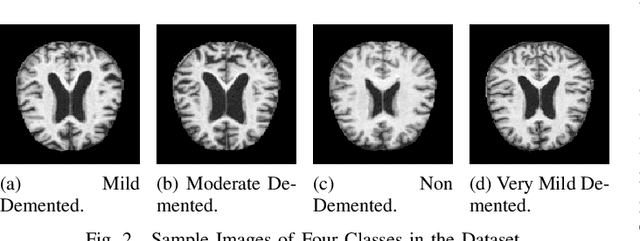

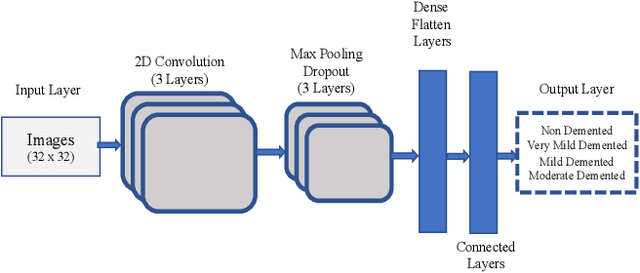
Dementia, a prevalent neurodegenerative condition, is a major manifestation of Alzheimer's disease (AD). As the condition progresses from mild to severe, it significantly impairs the individual's ability to perform daily tasks independently, necessitating the need for timely and accurate AD classification. Machine learning or deep learning models have emerged as effective tools for this purpose. In this study, we suggested an approach for classifying the four stages of dementia using RF, SVM, and CNN algorithms, augmented with watershed segmentation for feature extraction from MRI images. Our results reveal that SVM with watershed features achieves an impressive accuracy of 96.25%, surpassing other classification methods. The ADNI dataset is utilized to evaluate the effectiveness of our method, and we observed that the inclusion of watershed segmentation contributes to the enhanced performance of the models.
Recognition of COVID-19 Disease Utilizing X-Ray Imaging of the Chest Using CNN
Sep 05, 2021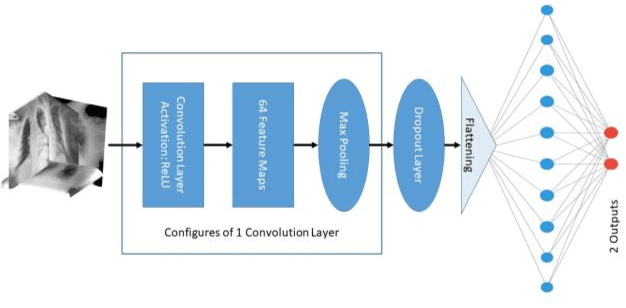
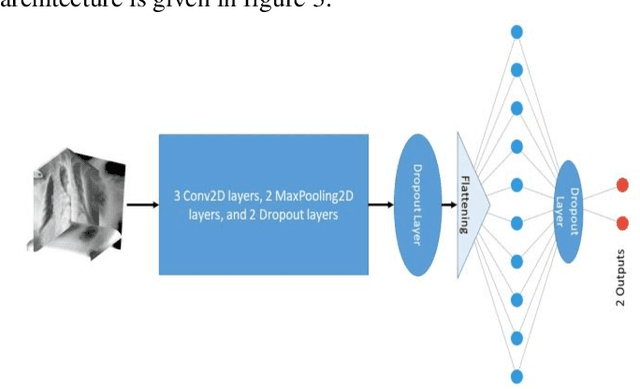
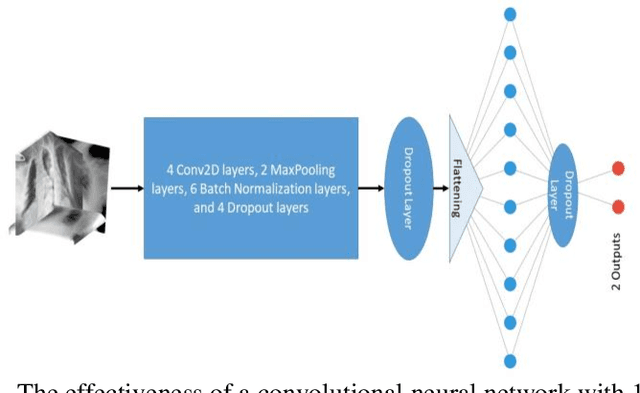
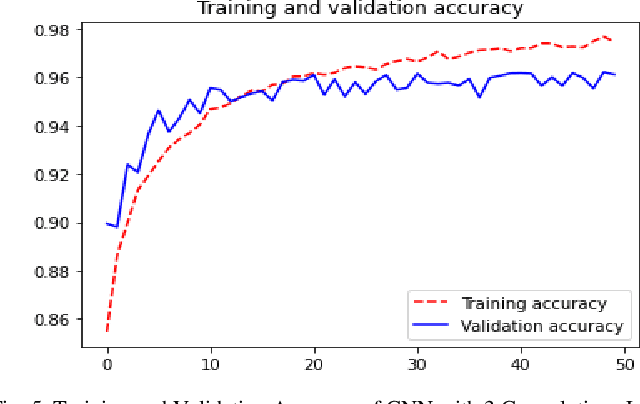
Since this COVID-19 pandemic thrives, the utilization of X-Ray images of the Chest (CXR) as a complementary screening technique to RT-PCR testing grows to its clinical use for respiratory complaints. Many new deep learning approaches have developed as a consequence. The goal of this research is to assess the convolutional neural networks (CNNs) to diagnosis COVID-19 utisizing X-ray images of chest. The performance of CNN with one, three, and four convolution layers has been evaluated in this research. A dataset of 13,808 CXR photographs are used in this research. When evaluated on X-ray images with three splits of the dataset, our preliminary experimental results show that the CNN model with three convolution layers can reliably detect with 96 percent accuracy (precision being 96 percent). This fact indicates the commitment of our suggested model for reliable screening of COVID-19.
Detection of Bangla Fake News using MNB and SVM Classifier
May 29, 2020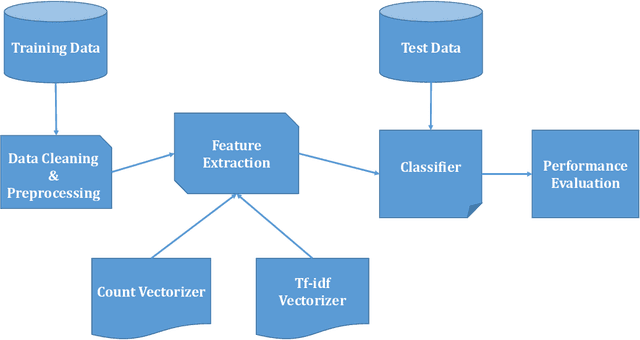
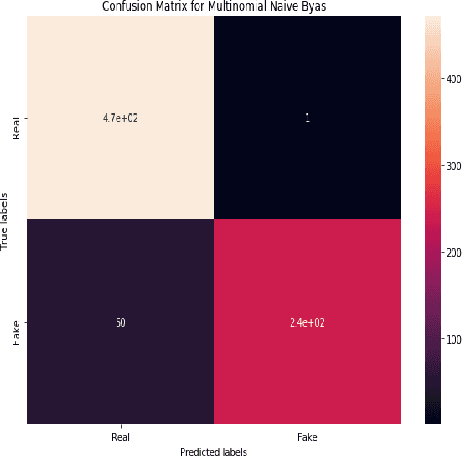
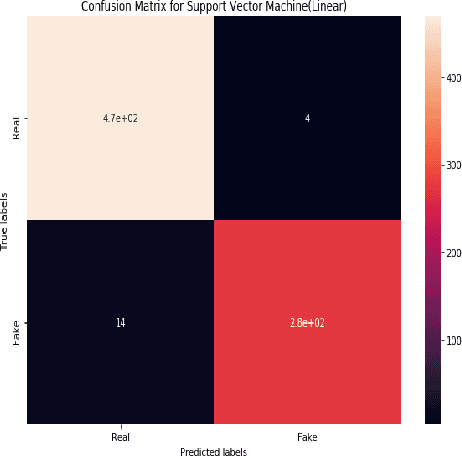
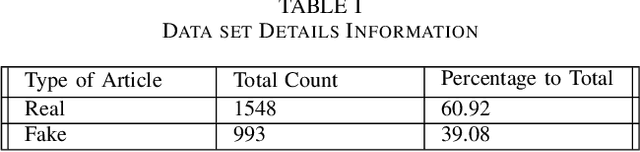
Fake news has been coming into sight in significant numbers for numerous business and political reasons and has become frequent in the online world. People can get contaminated easily by these fake news for its fabricated words which have enormous effects on the offline community. Thus, interest in research in this area has risen. Significant research has been conducted on the detection of fake news from English texts and other languages but a few in Bangla Language. Our work reflects the experimental analysis on the detection of Bangla fake news from social media as this field still requires much focus. In this research work, we have used two supervised machine learning algorithms, Multinomial Naive Bayes (MNB) and Support Vector Machine (SVM) classifiers to detect Bangla fake news with CountVectorizer and Term Frequency - Inverse Document Frequency Vectorizer as feature extraction. Our proposed framework detects fake news depending on the polarity of the corresponding article. Finally, our analysis shows SVM with the linear kernel with an accuracy of 96.64% outperform MNB with an accuracy of 93.32%.