 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBANSpEmo: A Bangla Emotional Speech Recognition Dataset
Dec 21, 2023
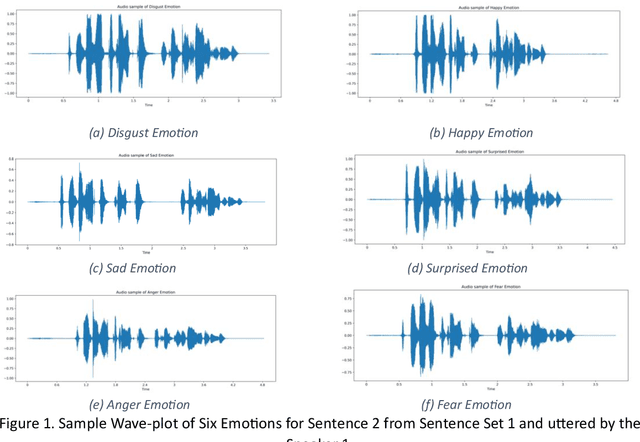
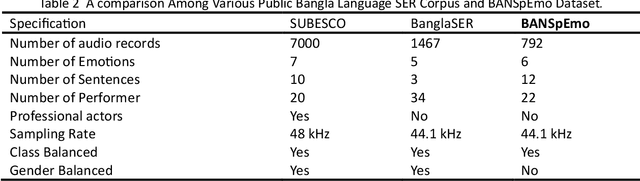
In the field of audio and speech analysis, the ability to identify emotions from acoustic signals is essential. Human-computer interaction (HCI) and behavioural analysis are only a few of the many areas where the capacity to distinguish emotions from speech signals has an extensive range of applications. Here, we are introducing BanSpEmo, a corpus of emotional speech that only consists of audio recordings and has been created specifically for the Bangla language. This corpus contains 792 audio recordings over a duration of more than 1 hour and 23 minutes. 22 native speakers took part in the recording of two sets of sentences that represent the six desired emotions. The data set consists of 12 Bangla sentences which are uttered in 6 emotions as Disgust, Happy, Sad, Surprised, Anger, and Fear. This corpus is not also gender balanced. Ten individuals who either have experience in related field or have acting experience took part in the assessment of this corpus. It has a balanced number of audio recordings in each emotion class. BanSpEmo can be considered as a useful resource to promote emotion and speech recognition research and related applications in the Bangla language. The dataset can be found here: https://data.mendeley.com/datasets/rdwn4bs5ky and might be employed for academic research.
Detection of Bangla Fake News using MNB and SVM Classifier
May 29, 2020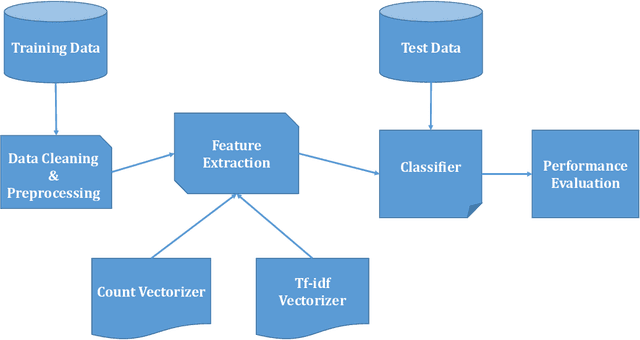
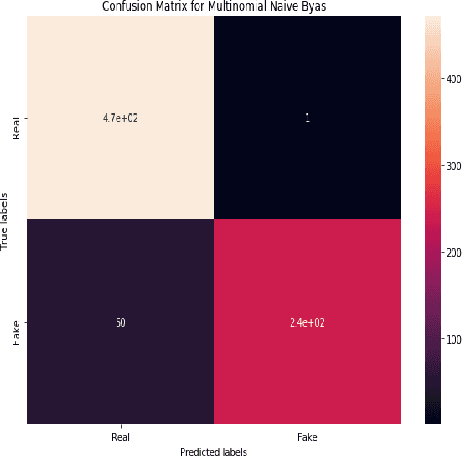
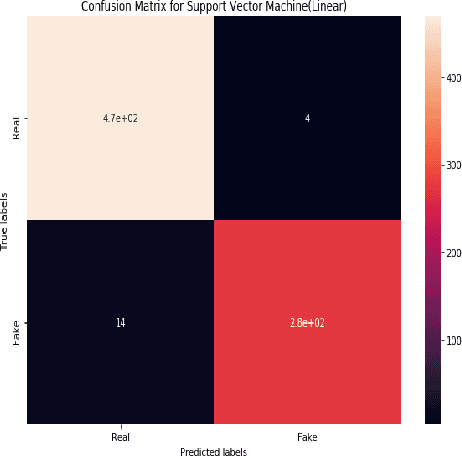
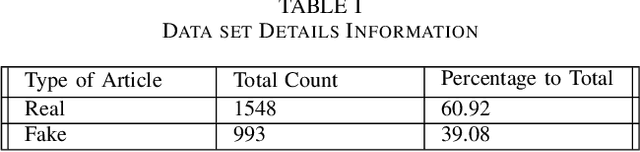
Fake news has been coming into sight in significant numbers for numerous business and political reasons and has become frequent in the online world. People can get contaminated easily by these fake news for its fabricated words which have enormous effects on the offline community. Thus, interest in research in this area has risen. Significant research has been conducted on the detection of fake news from English texts and other languages but a few in Bangla Language. Our work reflects the experimental analysis on the detection of Bangla fake news from social media as this field still requires much focus. In this research work, we have used two supervised machine learning algorithms, Multinomial Naive Bayes (MNB) and Support Vector Machine (SVM) classifiers to detect Bangla fake news with CountVectorizer and Term Frequency - Inverse Document Frequency Vectorizer as feature extraction. Our proposed framework detects fake news depending on the polarity of the corresponding article. Finally, our analysis shows SVM with the linear kernel with an accuracy of 96.64% outperform MNB with an accuracy of 93.32%.