 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Masked Transformer for Point Cloud Processing with Skip Attention-Based Upsampling
Paper and Code
Mar 21, 2024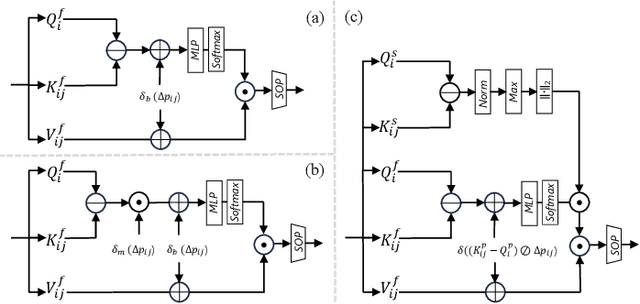
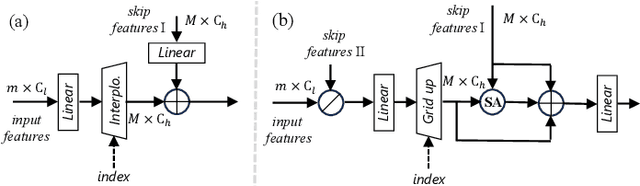
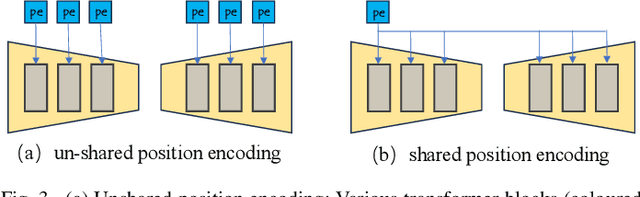
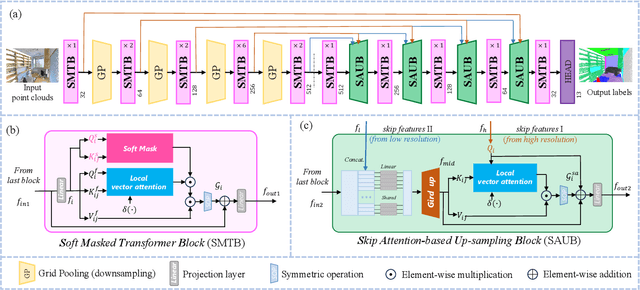
Point cloud processing methods leverage local and global point features %at the feature level to cater to downstream tasks, yet they often overlook the task-level context inherent in point clouds during the encoding stage. We argue that integrating task-level information into the encoding stage significantly enhances performance. To that end, we propose SMTransformer which incorporates task-level information into a vector-based transformer by utilizing a soft mask generated from task-level queries and keys to learn the attention weights. Additionally, to facilitate effective communication between features from the encoding and decoding layers in high-level tasks such as segmentation, we introduce a skip-attention-based up-sampling block. This block dynamically fuses features from various resolution points across the encoding and decoding layers. To mitigate the increase in network parameters and training time resulting from the complexity of the aforementioned blocks, we propose a novel shared position encoding strategy. This strategy allows various transformer blocks to share the same position information over the same resolution points, thereby reducing network parameters and training time without compromising accuracy.Experimental comparisons with existing methods on multiple datasets demonstrate the efficacy of SMTransformer and skip-attention-based up-sampling for point cloud processing tasks, including semantic segmentation and classification. In particular, we achieve state-of-the-art semantic segmentation results of 73.4% mIoU on S3DIS Area 5 and 62.4% mIoU on SWAN dataset