 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-invariant Prototypes for Semantic Segmentation
Paper and Code
Aug 12, 2022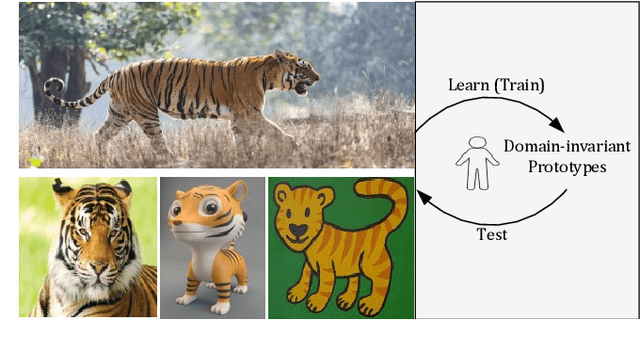
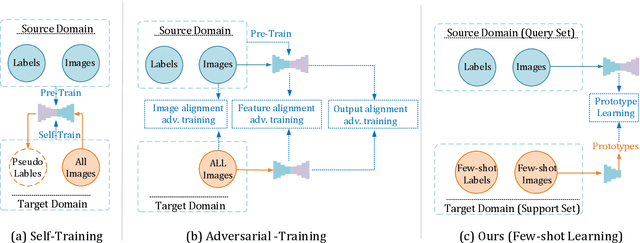
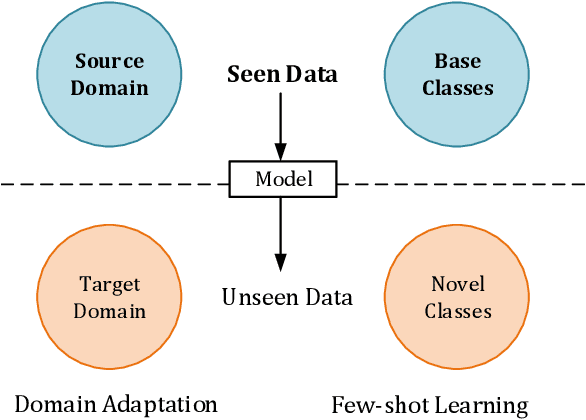
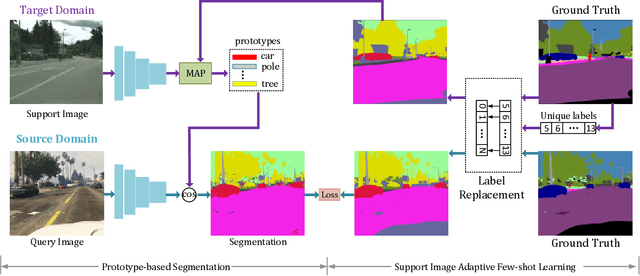
Deep Learning has greatly advanced the performance of semantic segmentation, however, its success relies on the availability of large amounts of annotated data for training. Hence, many efforts have been devoted to domain adaptive semantic segmentation that focuses on transferring semantic knowledge from a labeled source domain to an unlabeled target domain. Existing self-training methods typically require multiple rounds of training, while another popular framework based on adversarial training is known to be sensitive to hyper-parameters. In this paper, we present an easy-to-train framework that learns domain-invariant prototypes for domain adaptive semantic segmentation. In particular, we show that domain adaptation shares a common character with few-shot learning in that both aim to recognize some types of unseen data with knowledge learned from large amounts of seen data. Thus, we propose a unified framework for domain adaptation and few-shot learning. The core idea is to use the class prototypes extracted from few-shot annotated target images to classify pixels of both source images and target images. Our method involves only one-stage training and does not need to be trained on large-scale un-annotated target images. Moreover, our method can be extended to variants of both domain adaptation and few-shot learning. Experiments on adapting GTA5-to-Cityscapes and SYNTHIA-to-Cityscapes show that our method achieves competitive performance to state-of-the-art.