 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARMFlow: AutoRegressive MeanFlow for Online 3D Human Reaction Generation
Dec 18, 2025



3D human reaction generation faces three main challenges:(1) high motion fidelity, (2) real-time inference, and (3) autoregressive adaptability for online scenarios. Existing methods fail to meet all three simultaneously. We propose ARMFlow, a MeanFlow-based autoregressive framework that models temporal dependencies between actor and reactor motions. It consists of a causal context encoder and an MLP-based velocity predictor. We introduce Bootstrap Contextual Encoding (BSCE) in training, encoding generated history instead of the ground-truth ones, to alleviate error accumulation in autoregressive generation. We further introduce the offline variant ReMFlow, achieving state-of-the-art performance with the fastest inference among offline methods. Our ARMFlow addresses key limitations of online settings by: (1) enhancing semantic alignment via a global contextual encoder; (2) achieving high accuracy and low latency in a single-step inference; and (3) reducing accumulated errors through BSCE. Our single-step online generation surpasses existing online methods on InterHuman and InterX by over 40% in FID, while matching offline state-of-the-art performance despite using only partial sequence conditions.
UniHM: Universal Human Motion Generation with Object Interactions in Indoor Scenes
May 19, 2025Human motion synthesis in complex scenes presents a fundamental challenge, extending beyond conventional Text-to-Motion tasks by requiring the integration of diverse modalities such as static environments, movable objects, natural language prompts, and spatial waypoints. Existing language-conditioned motion models often struggle with scene-aware motion generation due to limitations in motion tokenization, which leads to information loss and fails to capture the continuous, context-dependent nature of 3D human movement. To address these issues, we propose UniHM, a unified motion language model that leverages diffusion-based generation for synthesizing scene-aware human motion. UniHM is the first framework to support both Text-to-Motion and Text-to-Human-Object Interaction (HOI) in complex 3D scenes. Our approach introduces three key contributions: (1) a mixed-motion representation that fuses continuous 6DoF motion with discrete local motion tokens to improve motion realism; (2) a novel Look-Up-Free Quantization VAE (LFQ-VAE) that surpasses traditional VQ-VAEs in both reconstruction accuracy and generative performance; and (3) an enriched version of the Lingo dataset augmented with HumanML3D annotations, providing stronger supervision for scene-specific motion learning. Experimental results demonstrate that UniHM achieves comparative performance on the OMOMO benchmark for text-to-HOI synthesis and yields competitive results on HumanML3D for general text-conditioned motion generation.
MonoDiff9D: Monocular Category-Level 9D Object Pose Estimation via Diffusion Model
Apr 14, 2025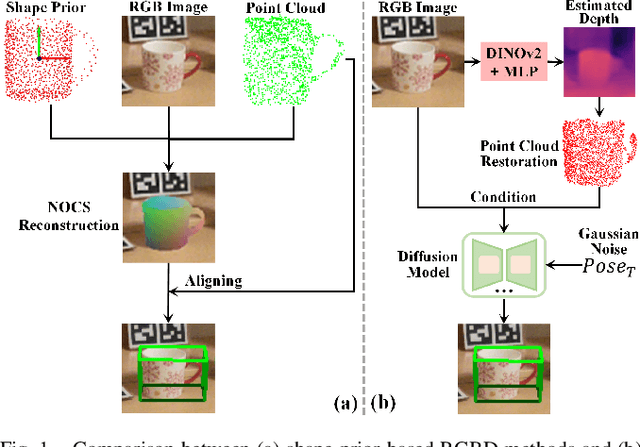
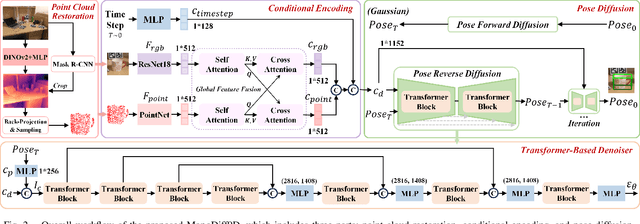

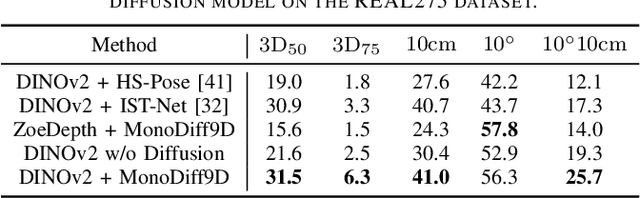
Object pose estimation is a core means for robots to understand and interact with their environment. For this task, monocular category-level methods are attractive as they require only a single RGB camera. However, current methods rely on shape priors or CAD models of the intra-class known objects. We propose a diffusion-based monocular category-level 9D object pose generation method, MonoDiff9D. Our motivation is to leverage the probabilistic nature of diffusion models to alleviate the need for shape priors, CAD models, or depth sensors for intra-class unknown object pose estimation. We first estimate coarse depth via DINOv2 from the monocular image in a zero-shot manner and convert it into a point cloud. We then fuse the global features of the point cloud with the input image and use the fused features along with the encoded time step to condition MonoDiff9D. Finally, we design a transformer-based denoiser to recover the object pose from Gaussian noise. Extensive experiments on two popular benchmark datasets show that MonoDiff9D achieves state-of-the-art monocular category-level 9D object pose estimation accuracy without the need for shape priors or CAD models at any stage. Our code will be made public at https://github.com/CNJianLiu/MonoDiff9D.
Auto-Regressive Diffusion for Generating 3D Human-Object Interactions
Mar 21, 2025Text-driven Human-Object Interaction (Text-to-HOI) generation is an emerging field with applications in animation, video games, virtual reality, and robotics. A key challenge in HOI generation is maintaining interaction consistency in long sequences. Existing Text-to-Motion-based approaches, such as discrete motion tokenization, cannot be directly applied to HOI generation due to limited data in this domain and the complexity of the modality. To address the problem of interaction consistency in long sequences, we propose an autoregressive diffusion model (ARDHOI) that predicts the next continuous token. Specifically, we introduce a Contrastive Variational Autoencoder (cVAE) to learn a physically plausible space of continuous HOI tokens, thereby ensuring that generated human-object motions are realistic and natural. For generating sequences autoregressively, we develop a Mamba-based context encoder to capture and maintain consistent sequential actions. Additionally, we implement an MLP-based denoiser to generate the subsequent token conditioned on the encoded context. Our model has been evaluated on the OMOMO and BEHAVE datasets, where it outperforms existing state-of-the-art methods in terms of both performance and inference speed. This makes ARDHOI a robust and efficient solution for text-driven HOI tasks
Text-guided 3D Human Motion Generation with Keyframe-based Parallel Skip Transformer
May 24, 2024

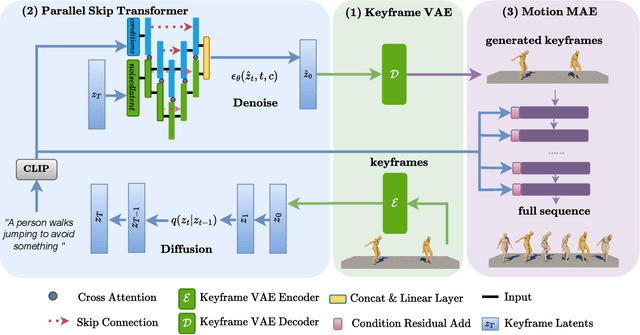
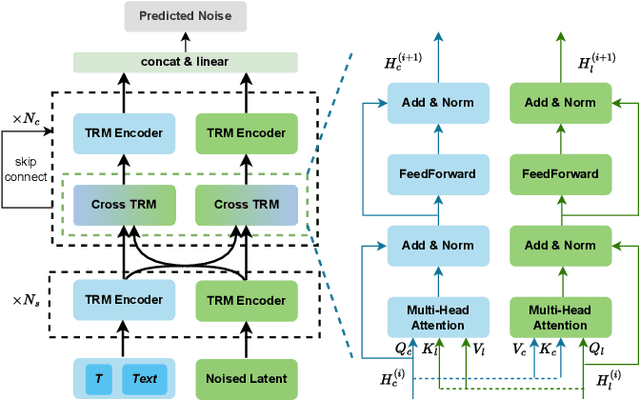
Text-driven human motion generation is an emerging task in animation and humanoid robot design. Existing algorithms directly generate the full sequence which is computationally expensive and prone to errors as it does not pay special attention to key poses, a process that has been the cornerstone of animation for decades. We propose KeyMotion, that generates plausible human motion sequences corresponding to input text by first generating keyframes followed by in-filling. We use a Variational Autoencoder (VAE) with Kullback-Leibler regularization to project the keyframes into a latent space to reduce dimensionality and further accelerate the subsequent diffusion process. For the reverse diffusion, we propose a novel Parallel Skip Transformer that performs cross-modal attention between the keyframe latents and text condition. To complete the motion sequence, we propose a text-guided Transformer designed to perform motion-in-filling, ensuring the preservation of both fidelity and adherence to the physical constraints of human motion. Experiments show that our method achieves state-of-theart results on the HumanML3D dataset outperforming others on all R-precision metrics and MultiModal Distance. KeyMotion also achieves competitive performance on the KIT dataset, achieving the best results on Top3 R-precision, FID, and Diversity metrics.