 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfecting Imperfect Physical Neural Networks with Transferable Robustness using Sharpness-Aware Training
Paper and Code
Nov 19, 2024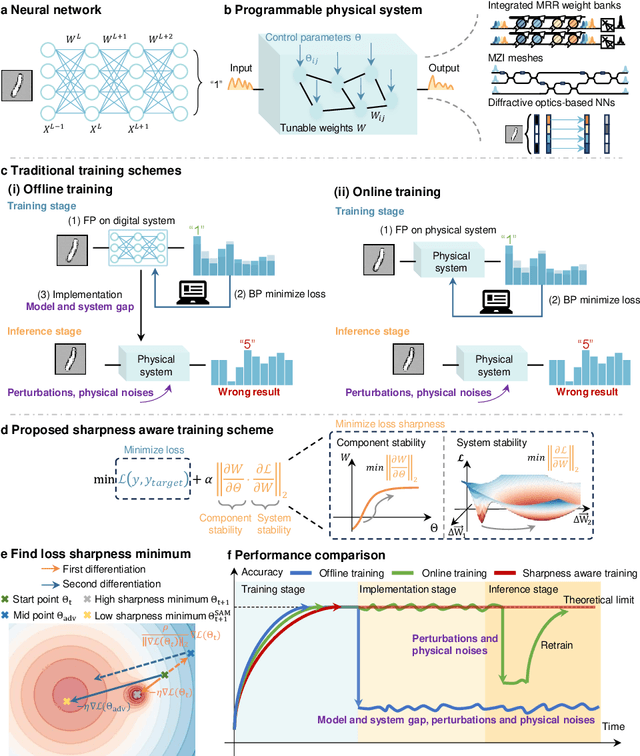
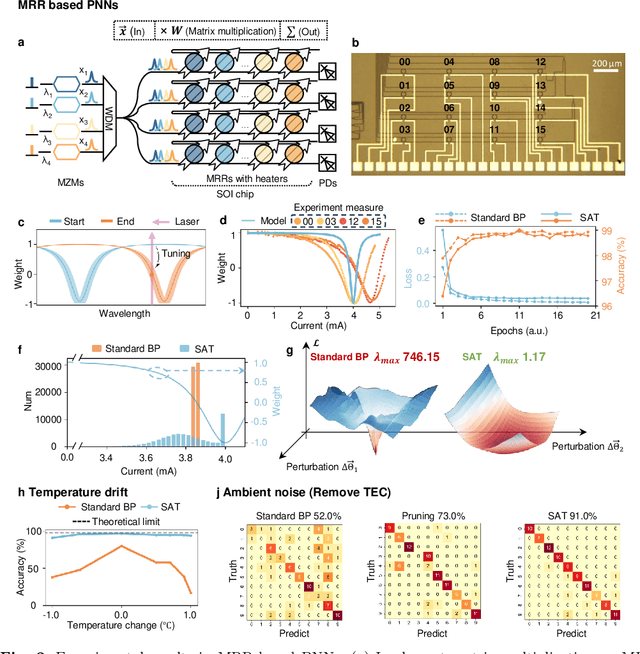
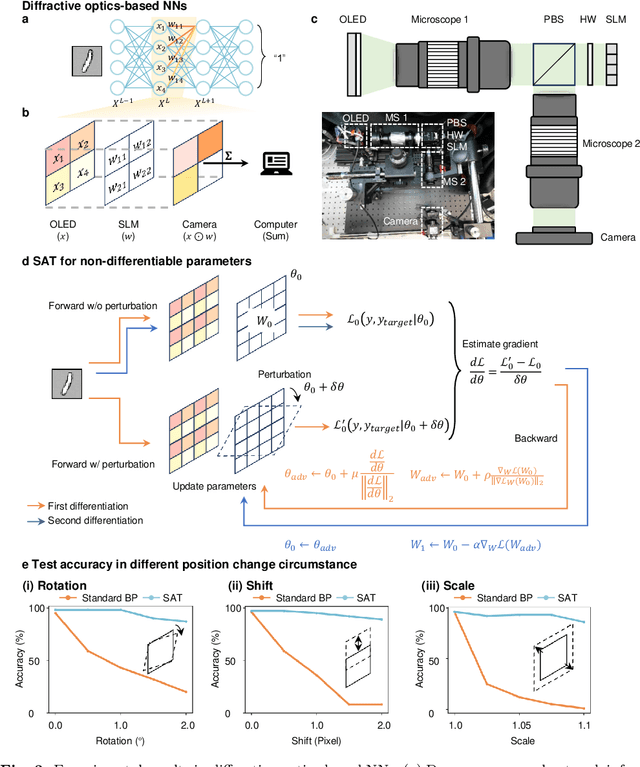
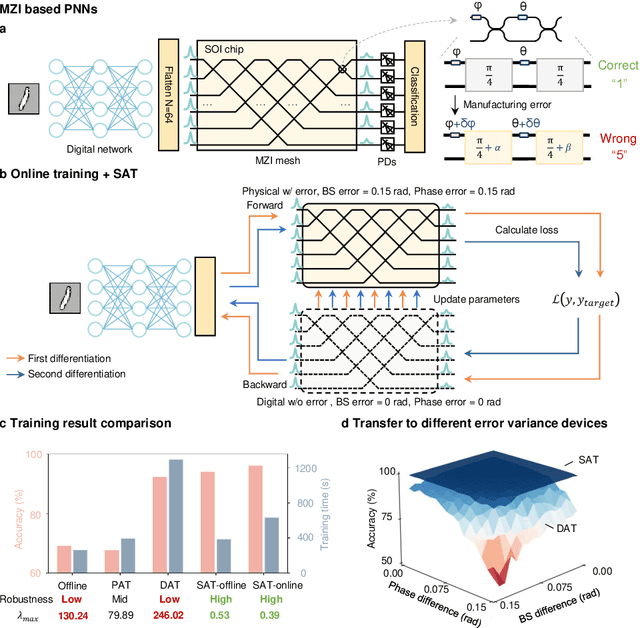
AI models are essential in science and engineering, but recent advances are pushing the limits of traditional digital hardware. To address these limitations, physical neural networks (PNNs), which use physical substrates for computation, have gained increasing attention. However, developing effective training methods for PNNs remains a significant challenge. Current approaches, regardless of offline and online training, suffer from significant accuracy loss. Offline training is hindered by imprecise modeling, while online training yields device-specific models that can't be transferred to other devices due to manufacturing variances. Both methods face challenges from perturbations after deployment, such as thermal drift or alignment errors, which make trained models invalid and require retraining. Here, we address the challenges with both offline and online training through a novel technique called Sharpness-Aware Training (SAT), where we innovatively leverage the geometry of the loss landscape to tackle the problems in training physical systems. SAT enables accurate training using efficient backpropagation algorithms, even with imprecise models. PNNs trained by SAT offline even outperform those trained online, despite modeling and fabrication errors. SAT also overcomes online training limitations by enabling reliable transfer of models between devices. Finally, SAT is highly resilient to perturbations after deployment, allowing PNNs to continuously operate accurately under perturbations without retraining. We demonstrate SAT across three types of PNNs, showing it is universally applicable, regardless of whether the models are explicitly known. This work offers a transformative, efficient approach to training PNNs, addressing critical challenges in analog computing and enabling real-world deployment.